Executing JavaScript after X seconds
onclick = "setTimeout(function() { document.getElementById('div1').style.display='none';document.getElementById('div2').style.display='none'}, 1000)"
Change 1000 to the number of milliseconds you want to delay.
Get only specific attributes with from Laravel Collection
I have now come up with an own solution to this:
1. Created a general function to extract specific attributes from arrays
The function below extract only specific attributes from an associative array, or an array of associative arrays (the last is what you get when doing $collection->toArray() in Laravel).
It can be used like this:
$data = array_extract( $collection->toArray(), ['id','url'] );
I am using the following functions:
function array_is_assoc( $array )
{
return is_array( $array ) && array_diff_key( $array, array_keys(array_keys($array)) );
}
function array_extract( $array, $attributes )
{
$data = [];
if ( array_is_assoc( $array ) )
{
foreach ( $attributes as $attribute )
{
$data[ $attribute ] = $array[ $attribute ];
}
}
else
{
foreach ( $array as $key => $values )
{
$data[ $key ] = [];
foreach ( $attributes as $attribute )
{
$data[ $key ][ $attribute ] = $values[ $attribute ];
}
}
}
return $data;
}
This solution does not focus on performance implications on looping through the collections in large datasets.
2. Implement the above via a custom collection i Laravel
Since I would like to be able to simply do $collection->extract('id','url'); on any collection object, I have implemented a custom collection class.
First I created a general Model, which extends the Eloquent model, but uses a different collection class. All you models need to extend this custom model, and not the Eloquent Model then.
<?php
namespace App\Models;
use Illuminate\Database\Eloquent\Model as EloquentModel;
use Lib\Collection;
class Model extends EloquentModel
{
public function newCollection(array $models = [])
{
return new Collection( $models );
}
}
?>
Secondly I created the following custom collection class:
<?php
namespace Lib;
use Illuminate\Support\Collection as EloquentCollection;
class Collection extends EloquentCollection
{
public function extract()
{
$attributes = func_get_args();
return array_extract( $this->toArray(), $attributes );
}
}
?>
Lastly, all models should then extend your custom model instead, like such:
<?php
namespace App\Models;
class Article extends Model
{
...
Now the functions from no. 1 above are neatly used by the collection to make the $collection->extract() method available.
How do I set up cron to run a file just once at a specific time?
For those who is not able to access/install at in environment, can use custom script:
#!/bin/bash
if [ $# -lt 2 ]; then
echo ""
echo "Syntax Error!"
echo "Usage: $0 <shell script> <datetime>"
echo "<datetime> format: %Y%m%d%H%M"
echo "Example: $0 /home/user/scripts/server_backup.sh 202008142350"
echo ""
exit 1
fi
while true; do
t=$(date +%Y%m%d%H%M);
if [ $t -eq $2 ]; then
/bin/bash $1
echo DONE $(date);
break;
fi;
sleep 1;
done
Let's name the script as run1time.sh Example could be something like:
nohup bash run1time.sh /path/to/your/script.sh 202008150300 &
Restart node upon changing a file
You should look at something like nodemon.
Nodemon will watch the files in the directory in which nodemon was started, and if they change, it will automatically restart your node application.
Example:
nodemon ./server.js localhost 8080
or simply
nodemon server
How do I tokenize a string sentence in NLTK?
As @PavelAnossov answered, the canonical answer, use the word_tokenize function in nltk:
from nltk import word_tokenize
sent = "This is my text, this is a nice way to input text."
word_tokenize(sent)
If your sentence is truly simple enough:
Using the string.punctuation set, remove punctuation then split using the whitespace delimiter:
import string
x = "This is my text, this is a nice way to input text."
y = "".join([i for i in x if not in string.punctuation]).split(" ")
print y
How to sort strings in JavaScript
Use String.prototype.localeCompare a per your example:
list.sort(function (a, b) {
return ('' + a.attr).localeCompare(b.attr);
})
We force a.attr to be a string to avoid exceptions. localeCompare has been supported since Internet Explorer 6 and Firefox 1. You may also see the following code used that doesn't respect a locale:
if (item1.attr < item2.attr)
return -1;
if ( item1.attr > item2.attr)
return 1;
return 0;
The forked VM terminated without saying properly goodbye. VM crash or System.exit called
The forked JVM used in the test is running out of memory. The solution would be to either disable forking a JVM and running the tests on the main JVM ensuring you have sufficient memory or to pass args to increase the memory of the forked JVM
Check out the solution in this answer
Excel Date to String conversion
Here is a VBA approach:
Sub change()
toText Sheets(1).Range("A1:F20")
End Sub
Sub toText(target As Range)
Dim cell As Range
For Each cell In target
cell.Value = cell.Text
cell.NumberFormat = "@"
Next cell
End Sub
If you are looking for a solution without programming, the Question should be moved to SuperUser.
How to return string value from the stored procedure
Use SELECT or an output parameter. More can be found here: http://www.sqlteam.com/forums/topic.asp?TOPIC_ID=100201
What reference do I need to use Microsoft.Office.Interop.Excel in .NET?
Here is super solid solution, you just need have excell.dll in your Debug/Release folder Mine is 77,824 bytes, I downloaded it as a file, this also explain why some people have Debug compiled but Release not or vice versa.
Trento
Extend contigency table with proportions (percentages)
I am not 100% certain, but I think this does what you want using prop.table. See mostly the last 3 lines. The rest of the code is just creating fake data.
set.seed(1234)
total_bill <- rnorm(50, 25, 3)
tip <- 0.15 * total_bill + rnorm(50, 0, 1)
sex <- rbinom(50, 1, 0.5)
smoker <- rbinom(50, 1, 0.3)
day <- ceiling(runif(50, 0,7))
time <- ceiling(runif(50, 0,3))
size <- 1 + rpois(50, 2)
my.data <- as.data.frame(cbind(total_bill, tip, sex, smoker, day, time, size))
my.data
my.table <- table(my.data$smoker)
my.prop <- prop.table(my.table)
cbind(my.table, my.prop)
gdb fails with "Unable to find Mach task port for process-id" error
These instructions work for OSX High Sierra and avoid running gdb as root (yuck!). I recently updated from OSX 10.13.2 to 10.3.3. I think this is when gdb 8.0.1 (installed w/ homebrew) started failing for me.
I had difficulty with other people's instructions. After different instructions, everything was a mess. So I started a fresh. I more or less followed these instructions.
Clean the mess :
brew uninstall --force gdb # This deletes _all_ versions of gdb on the machine- In
Applications->Utilities->Keychain Access, I deleted all previous gdb certificates and keys (be sure you know what you're doing here!). It's unclear if this is necessary, but since I'd buggered up trying to create those certificates and keys using other instructions I eliminated them anyways. I had keys and certificates in both login and system.
Now reinstall gdb.
brew install gdb- Within
Keychain Access, go to menuKeychain Access->Certificate Assistant->Create a Certificate - Check "Let me override defaults" and set
Name : gdb-cert Identity Type: Self Signed Root Certificate Type : Code Signing [X] Let me override defaults
- On 1st Certificate Information page:
Serial Number : 1 Validity Period (days): 3650
On 2nd Certificate Information page, I left all fields blank except those already filled in.
On Key Pair Information page, I left the defaults
Key Size : 2048 Algorithm : RSA
- On Key Usage Extension page, I left the defaults checked.
[X] Include Key Usage Extension [X] This extension is critical Capabilities: [X] Signature
- On Extended Key Usage Extension page, I left the defaults checked.
[X] Include Extended Key Usage Extension [X] This extension is critical Capabilities: [X] Code Signing
On Basic Constraints Extension Page, nothing was checked (default).
On Subject Alternate Name Extension page, I left the default checked and didn't add anything else.
[X] Include Subject Alternate Name Extension
- On Specify a Location for the certificate page, I set
Keychain: System
I clicked Create and was prompted for my password.
Back in the
Keychain Accessapp, I went toSystemand right clicked ongdb-certand under dropdown menuTrust, I changed all the fields toAlways Trust.Rebooted computer.
At the Terminal, I ran
codesign -s gdb-cert /usr/local/bin/gdb. I entered my password when prompted.At the Terminal, I ran
echo "set startup-with-shell off" >> ~/.gdbinitI ran
gdb myprogramand thenstartwithin the gdb console. Here, I believe, it prompted for me for my password. After that, all subsequent runs, it did not prompt for my password.
Eclipse reports rendering library more recent than ADT plug-in
Change the Target version to new updates you have. Otherwise, change what SDK version you have in the Android manifest file.
android:minSdkVersion="8"
android:targetSdkVersion="18"
"std::endl" vs "\n"
They will both write the appropriate end-of-line character(s). In addition to that endl will cause the buffer to be committed. You usually don't want to use endl when doing file I/O because the unnecessary commits can impact performance.
Uncaught TypeError: Object #<Object> has no method 'movingBoxes'
There are a few things you can try to get this working.
Be ABSOLUTELY sure your script is being pulled into the page, one way to check is by using the 'sources' tab in the Chrome Debugger and searching for the file.
Be sure that you've included the script after you've included jQuery, as it is most certainly dependant upon that.
Other than that, I checked out the API and you're definitely doing everything right as far as I can see. Best of luck friend!
EDIT: Ensure you close your script tag. There's an answer below that points to that being the solution.
More elegant "ps aux | grep -v grep"
You could use preg_split instead of explode and split on [ ]+ (one or more spaces). But I think in this case you could go with preg_match_all and capturing:
preg_match_all('/[ ]php[ ]+\S+[ ]+(\S+)/', $input, $matches);
$result = $matches[1];
The pattern matches a space, php, more spaces, a string of non-spaces (the path), more spaces, and then captures the next string of non-spaces. The first space is mostly to ensure that you don't match php as part of a user name but really only as a command.
An alternative to capturing is the "keep" feature of PCRE. If you use \K in the pattern, everything before it is discarded in the match:
preg_match_all('/[ ]php[ ]+\S+[ ]+\K\S+/', $input, $matches);
$result = $matches[0];
I would use preg_match(). I do something similar for many of my system management scripts. Here is an example:
$test = "user 12052 0.2 0.1 137184 13056 ? Ss 10:00 0:00 php /home/user/public_html/utilities/runProcFile.php cust1 cron
user 12054 0.2 0.1 137184 13064 ? Ss 10:00 0:00 php /home/user/public_html/utilities/runProcFile.php cust3 cron
user 12055 0.6 0.1 137844 14220 ? Ss 10:00 0:00 php /home/user/public_html/utilities/runProcFile.php cust4 cron
user 12057 0.2 0.1 137184 13052 ? Ss 10:00 0:00 php /home/user/public_html/utilities/runProcFile.php cust89 cron
user 12058 0.2 0.1 137184 13052 ? Ss 10:00 0:00 php /home/user/public_html/utilities/runProcFile.php cust435 cron
user 12059 0.3 0.1 135112 13000 ? Ss 10:00 0:00 php /home/user/public_html/utilities/runProcFile.php cust16 cron
root 12068 0.0 0.0 106088 1164 pts/1 S+ 10:00 0:00 sh -c ps aux | grep utilities > /home/user/public_html/logs/dashboard/currentlyPosting.txt
root 12070 0.0 0.0 103240 828 pts/1 R+ 10:00 0:00 grep utilities";
$lines = explode("\n", $test);
foreach($lines as $line){
if(preg_match("/.php[\s+](cust[\d]+)[\s+]cron/i", $line, $matches)){
print_r($matches);
}
}
The above prints:
Array
(
[0] => .php cust1 cron
[1] => cust1
)
Array
(
[0] => .php cust3 cron
[1] => cust3
)
Array
(
[0] => .php cust4 cron
[1] => cust4
)
Array
(
[0] => .php cust89 cron
[1] => cust89
)
Array
(
[0] => .php cust435 cron
[1] => cust435
)
Array
(
[0] => .php cust16 cron
[1] => cust16
)
You can set $test to equal the output from exec. the values you are looking for would be in the if statement under the foreach. $matches[1] will have the custx value.
How to set radio button selected value using jquery
Try
function RadionButtonSelectedValueSet(name, SelectdValue) {
$('input[name="' + name+ '"][value="' + SelectdValue + '"]').prop('checked', true);
}
also call the method on dom ready
<script type="text/javascript">
jQuery(function(){
RadionButtonSelectedValueSet('RBLExperienceApplicable', '1');
})
</script>
xcode-select active developer directory error
For context, today is Jan 28, 2019.
On my Mac, I did two things to resolve this problem:
Run the following command in your terminal:
sudo xcode-select --installRestart your Mac.
Until I restarted the computer, the problem kept occurring in my Android Studio. After reboot, it was working just fine. Also note that I did not execute any --switch commands as others are doing. I hope this helps.
how do I check in bash whether a file was created more than x time ago?
I always liked using date -r /the/file +%s to find its age.
You can also do touch --date '2015-10-10 9:55' /tmp/file to get extremely fine-grained time on an arbitrary date/time.
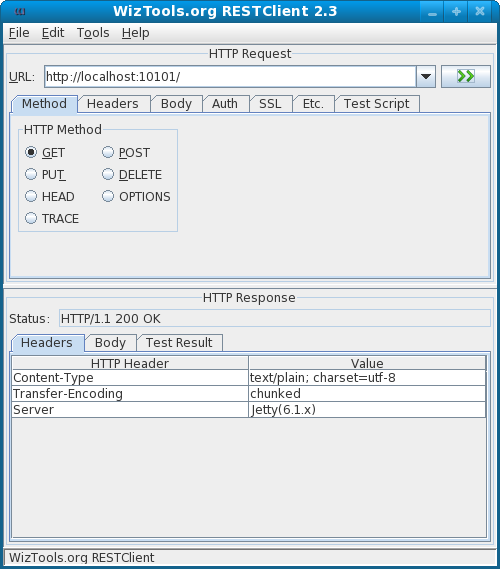
Graphical HTTP client for windows
Update: For people that still come across this, Postman is your best bet now: https://www.getpostman.com/apps
RestClient is my favorite. It's Java based. I think it should meet your needs quite nicely. I particularly like the Auth suppport.
https://github.com/wiztools/rest-client
Embed a PowerPoint presentation into HTML
I was looking for a solution for similar problem.
I looked into http://phppowerpoint.codeplex.com/
But they have no better documentation, and even no demo page I could see over there and it was seemingly difficult.
What I came up with is: SkyDrive by Microsoft. https://skydrive.live.com
All you need is an account with them and upload your PPT and embed them straightaway. PPT player is quite clean to use and I like it.
how to change text in Android TextView
@Zordid @Iambda answer is great, but I found that if I put
mHandler.postDelayed(mUpdateUITimerTask, 10 * 1000);
in the run() method and
mHandler.postDelayed(mUpdateUITimerTask, 0);
in the onCreate method make the thing keep updating.
Click a button with XPath containing partial id and title in Selenium IDE
Now that you have provided your HTML sample, we're able to see that your XPath is slightly wrong. While it's valid XPath, it's logically wrong.
You've got:
//*[contains(@id, 'ctl00_btnAircraftMapCell')]//*[contains(@title, 'Select Seat')]
Which translates into:
Get me all the elements that have an ID that contains ctl00_btnAircraftMapCell. Out of these elements, get any child elements that have a title that contains Select Seat.
What you actually want is:
//a[contains(@id, 'ctl00_btnAircraftMapCell') and contains(@title, 'Select Seat')]
Which translates into:
Get me all the anchor elements that have both: an id that contains ctl00_btnAircraftMapCell and a title that contains Select Seat.
Javascript objects: get parent
Try this until a non-no answer appears:
function parent() {
this.child;
interestingProperty = "5";
...
}
function child() {
this.parent;
...
}
a = new parent();
a.child = new child();
a.child.parent = a; // this gives the child a reference to its parent
alert(a.interestingProperty+" === "+a.child.parent.interestingProperty);
Lists: Count vs Count()
If you by any chance wants to change the type of your collection you are better served with the Count() extension. This way you don't have to refactor your code (to use Length for instance).
When do I need to use Begin / End Blocks and the Go keyword in SQL Server?
GO isn't a keyword in SQL Server; it's a batch separator. GO ends a batch of statements. This is especially useful when you are using something like SQLCMD. Imagine you are entering in SQL statements on the command line. You don't necessarily want the thing to execute every time you end a statement, so SQL Server does nothing until you enter "GO".
Likewise, before your batch starts, you often need to have some objects visible. For example, let's say you are creating a database and then querying it. You can't write:
CREATE DATABASE foo;
USE foo;
CREATE TABLE bar;
because foo does not exist for the batch which does the CREATE TABLE. You'd need to do this:
CREATE DATABASE foo;
GO
USE foo;
CREATE TABLE bar;
Why compile Python code?
Something not touched upon is source-to-source-compiling. For example, nuitka translates Python code to C/C++, and compiles it to binary code which directly runs on the CPU, instead of Python bytecode which runs on the slower virtual machine.
This can lead to significant speedups, or it would let you work with Python while your environment depends on C/C++ code.
Refused to apply inline style because it violates the following Content Security Policy directive
As the error message says, you have an inline style, which CSP prohibits. I see at least one (list-style: none) in your HTML. Put that style in your CSS file instead.
To explain further, Content Security Policy does not allow inline CSS because it could be dangerous. From An Introduction to Content Security Policy:
"If an attacker can inject a script tag that directly contains some malicious payload .. the browser has no mechanism by which to distinguish it from a legitimate inline script tag. CSP solves this problem by banning inline script entirely: it’s the only way to be sure."
Java using scanner enter key pressed
This works using java.util.Scanner and will take multiple "enter" keystrokes:
Scanner scanner = new Scanner(System.in);
String readString = scanner.nextLine();
while(readString!=null) {
System.out.println(readString);
if (readString.isEmpty()) {
System.out.println("Read Enter Key.");
}
if (scanner.hasNextLine()) {
readString = scanner.nextLine();
} else {
readString = null;
}
}
To break it down:
Scanner scanner = new Scanner(System.in);
String readString = scanner.nextLine();
These lines initialize a new Scanner that is reading from the standard input stream (the keyboard) and reads a single line from it.
while(readString!=null) {
System.out.println(readString);
While the scanner is still returning non-null data, print each line to the screen.
if (readString.isEmpty()) {
System.out.println("Read Enter Key.");
}
If the "enter" (or return, or whatever) key is supplied by the input, the nextLine() method will return an empty string; by checking to see if the string is empty, we can determine whether that key was pressed. Here the text Read Enter Key is printed, but you could perform whatever action you want here.
if (scanner.hasNextLine()) {
readString = scanner.nextLine();
} else {
readString = null;
}
Finally, after printing the content and/or doing something when the "enter" key is pressed, we check to see if the scanner has another line; for the standard input stream, this method will "block" until either the stream is closed, the execution of the program ends, or further input is supplied.
insert data into database with codeigniter
Try this in your model:
function order_summary_insert()
$OrderLines=$this->input->post('orderlines');
$CustomerName=$this->input->post('customer');
$data = array(
'OrderLines'=>$OrderLines,
'CustomerName'=>$CustomerName
);
$this->db->insert('Customer_Orders',$data);
}
Try to use controller just to control the view and models always post your values in model. it makes easy to understand. Your controller will be:
function new_blank_order_summary() {
$this->sales_model->order_summary_insert($data);
$this->load->view('sales/new_blank_order_summary');
}
How to display scroll bar onto a html table
You have to insert your <table> into a <div> that it has fixed size, and in <div> style you have to set overflow: scroll.
What is the Windows equivalent of the diff command?
The windows equivalent to the diff command is the fc (File Comapre) command.
Here are the basic steps to do so:
1. Keep the two files in a folder (Example file1.html and file2.html)
2. Launch command prompt
3. Type fc file1Location file2Location
Have found a detailed tutorial on the same:
http://www.howtogeek.com/206123/how-to-use-fc-file-compare-from-the-windows-command-prompt/
JQuery to load Javascript file dynamically
I realize I am a little late here, (5 years or so), but I think there is a better answer than the accepted one as follows:
$("#addComment").click(function() {
if(typeof TinyMCE === "undefined") {
$.ajax({
url: "tinymce.js",
dataType: "script",
cache: true,
success: function() {
TinyMCE.init();
}
});
}
});
The getScript() function actually prevents browser caching. If you run a trace you will see the script is loaded with a URL that includes a timestamp parameter:
http://www.yoursite.com/js/tinymce.js?_=1399055841840
If a user clicks the #addComment link multiple times, tinymce.js will be re-loaded from a differently timestampped URL. This defeats the purpose of browser caching.
===
Alternatively, in the getScript() documentation there is a some sample code that demonstrates how to enable caching by creating a custom cachedScript() function as follows:
jQuery.cachedScript = function( url, options ) {
// Allow user to set any option except for dataType, cache, and url
options = $.extend( options || {}, {
dataType: "script",
cache: true,
url: url
});
// Use $.ajax() since it is more flexible than $.getScript
// Return the jqXHR object so we can chain callbacks
return jQuery.ajax( options );
};
// Usage
$.cachedScript( "ajax/test.js" ).done(function( script, textStatus ) {
console.log( textStatus );
});
===
Or, if you want to disable caching globally, you can do so using ajaxSetup() as follows:
$.ajaxSetup({
cache: true
});
Difference between View and ViewGroup in Android
A
ViewGroupis a special view that can contain other views (called children.) The view group is the base class for layouts and views containers. This class also defines theViewGroup.LayoutParamsclass which serves as the base class for layouts parameters.Viewclass represents the basic building block for user interface components. A View occupies a rectangular area on the screen and is responsible for drawing and event handling. View is the base class for widgets, which are used to create interactive UI components (buttons, text fields, etc.).- Example : ViewGroup (LinearLayout), View (TextView)
Finding index of character in Swift String
If you are looking for easy way to get index of Character or String checkout this library http://www.dollarswift.org/#indexof-char-character-int
You can get the indexOf from a string using another string as well or regex pattern
How to printf "unsigned long" in C?
%lu is the correct format for unsigned long. Sounds like there are other issues at play here, such as memory corruption or an uninitialized variable. Perhaps show us a larger picture?
file_put_contents: Failed to open stream, no such file or directory
I was also stuck on the same kind of problem and I followed the simple steps below.
Just get the exact url of the file to which you want to copy, for example:
http://www.test.com/test.txt (file to copy)
Then pass the exact absolute folder path with filename where you do want to write that file.
If you are on a Windows machine then
d:/xampp/htdocs/upload/test.txtIf you are on a Linux machine then
/var/www/html/upload/test.txt
You can get the document root with the PHP function $_SERVER['DOCUMENT_ROOT'].
ADB not responding. You can wait more,or kill "adb.exe" process manually and click 'Restart'
If you need to kill all adb processes on windows with one command, you can do it as follows:
taskkill /F /IM adb*
cannot load such file -- bundler/setup (LoadError)
It could be that there was a previous Ruby env installed on your system prior to your installation of 2.0? This might have had an existing GEM_PATH that lead to the /1.8 directory which the installation of version 2.0 simply kept.
The problem you where likely having, then, was that Passenger/Apache was looking in the /2.0 directory when in fact the gems were in the /1.8 directory. Your explicitly telling apache to use the /1.8 directory thus makes sense to fix the problem.
SetEnv GEM_HOME /usr/lib/ruby/gems/1.8
You might also try using the Ruby Version Manager to handle multiple Ruby envs.
Some things I found in Google:
"SSL certificate verify failed" using pip to install packages
Pretty unique case here, but having Fiddler running (not even targeting the same process) gave me the same SSL errors. Running pip install with --verbose showed an error with Fiddler, closing Fiddler immediately fixed the issue.
Which data type for latitude and longitude?
If you do not need all the functionality PostGIS offers, Postgres (nowadays) offers an extension module called earthdistance. It uses the point or cube data type depending on your accuracy needs for distance calculations.
You can now use the earth_box function to -for example- query for points within a certain distance of a location.
How to run a script at the start up of Ubuntu?
First of all, the easiest way to run things at startup is to add them to the file /etc/rc.local.
Another simple way is to use @reboot in your crontab. Read the cron manpage for details.
However, if you want to do things properly, in addition to adding a script to /etc/init.d you need to tell ubuntu when the script should be run and with what parameters. This is done with the command update-rc.d which creates a symlink from some of the /etc/rc* directories to your script. So, you'd need to do something like:
update-rc.d yourscriptname start 2
However, real init scripts should be able to handle a variety of command line options and otherwise integrate to the startup process. The file /etc/init.d/README has some details and further pointers.
How to do error logging in CodeIgniter (PHP)
Also make sure that you have allowed codeigniter to log the type of messages you want in a config file.
i.e $config['log_threshold'] = [log_level ranges 0-4];
Render HTML to an image
I read the answer by Sjeiti which I found very interesting, where you with just a few plain JavaScript lines can render HTML in an image.
We of course have to be aware of the limitations of this method (please read about some of them in his answer).
Here I have taken his code a couple of steps further.
An SVG-image has in principle infinite resolution, since it is vector graphics. But you might have noticed that the image that Sjeiti's code generated did not have a high resolution. This can be fixed by scaling the SVG-image before transferring it to the canvas-element, which I have done in the last one of the two (runnable) example codes i give below. The other thing I have implemented in that code is the last step, namely saving it as a PNG-file. Just to complete the whole thing.
So, I give two runnable snippets of code:
The first one demonstrates the infinite resolution of an SVG. Run it and zoom in with your browser to see that the resolution does not diminish as you zoom in.
In the snippet that you can run I have used backticks to specify a so called template string with line breaks so that you can more clearly see the HTML that is rendered. But otherwise, if that HTML is within one line, then the code will be very short, like this.
const body = document.getElementsByTagName('BODY')[0];
const img = document.createElement('img')
img.src = 'data:image/svg+xml,' + encodeURIComponent(`<svg xmlns="http://www.w3.org/2000/svg" width="200" height="200"><foreignObject width="100%" height="100%"><div xmlns="http://www.w3.org/1999/xhtml" style="border:1px solid red;padding:20px;"><style>em {color:red;}.test {color:blue;}</style>What you see here is only an image, nothing else.<br /><br /><em>I</em> really like <span class="test">cheese.</span><br /><br />Zoom in to check the resolution!</div></foreignObject></svg>`);
body.appendChild(img);
Here it comes as a runnable snippet.
const body = document.getElementsByTagName('BODY')[0];
const img = document.createElement('img')
img.src = 'data:image/svg+xml,' + encodeURIComponent(`
<svg xmlns="http://www.w3.org/2000/svg" width="200" height="200">
<foreignObject width="100%" height="100%">
<div xmlns="http://www.w3.org/1999/xhtml" style="border:1px solid red;padding:20px;">
<style>
em {
color:red;
}
.test {
color:blue;
}
</style>
What you see here is only an image, nothing
else.<br />
<br />
<em>I</em> really like <span class="test">cheese.</span><br />
<br />
Zoom in to check the resolution!
</div>
</foreignObject>
</svg>
`);
body.appendChild(img);Zoom in and check the infinite resolution of the SVG.
The next runnable, below, is the one that implements the two extra steps which I mentioned above, namely improving resolution by first scaling the SVG, and then the saving as a PNG-image.
window.addEventListener("load", doit, false)
var canvas;
var ctx;
var tempImg;
function doit() {
const body = document.getElementsByTagName('BODY')[0];
const scale = document.getElementById('scale').value;
let trans = document.getElementById('trans').checked;
if (trans) {
trans = '';
} else {
trans = 'background-color:white;';
}
let source = `
<div xmlns="http://www.w3.org/1999/xhtml" style="border:1px solid red;padding:20px;${trans}">
<style>
em {
color:red;
}
.test {
color:blue;
}
</style>
What you see here is only an image, nothing
else.<br />
<br />
<em>I</em> really like <span class="test">cheese.</span><br />
<br />
<div style="text-align:center;">
Scaling:
<br />
${scale} times!
</div>
</div>`
document.getElementById('source').innerHTML = source;
canvas = document.createElement('canvas');
ctx = canvas.getContext('2d');
canvas.width = 200*scale;
canvas.height = 200*scale;
tempImg = document.createElement('img');
tempImg.src = 'data:image/svg+xml,' + encodeURIComponent(`
<svg xmlns="http://www.w3.org/2000/svg" width="${200*scale}" height="${200*scale}">
<foreignObject
style="
width:200px;
height:200px;
transform:scale(${scale});
"
>` + source + `
</foreignObject>
</svg>
`);
}
function saveAsPng(){
ctx.drawImage(tempImg, 0, 0);
var a = document.createElement('a');
a.href = canvas.toDataURL('image/png');
a.download = 'image.png';
a.click();
}<table border="0">
<tr>
<td colspan="2">
The claims in the HTML-text is only true for the image created when you click the button.
</td>
</tr>
<tr>
<td width="250">
<div id="source" style="width:200px;height:200px;">
</div>
</td>
<td valign="top">
<div>
In this example the PNG-image will be squarish even if the HTML here on the left is not exactly squarish. That can be fixed.<br>
To increase the resolution of the image you can change the scaling with this slider.
<div style="text-align:right;margin:5px 0px;">
<label style="background-color:#FDD;border:1px solid #F77;padding:0px 10px;"><input id="trans" type="checkbox" onchange="doit();" /> Make it transparent</label>
</div>
<span style="white-space:nowrap;">1<input id="scale" type="range" min="1" max="10" step="0.25" value="2" oninput="doit();" style="width:150px;vertical-align:-8px;" />10 <button onclick="saveAsPng();">Save as PNG-image</button></span>
</div>
</td>
</tr>
</table>Try with different scalings. If you for example set scaling to 10, then you get a very good resolution in the generated PNG-image. And I added a little extra feature: a checkbox so that you can make the PNG-image transparent if you like.
Notice:
The Save-button does not work in Chrome and Edge when this script is run here at Stack Overflow. The reason is this https://www.chromestatus.com/feature/5706745674465280 .
Therefore I have also put this snippet on https://jsfiddle.net/7gozdq5v/ where it works for those browsers.
How to get a variable type in Typescript?
I have checked a variable if it is a boolean or not as below
console.log(isBoolean(this.myVariable));
Similarly we have
isNumber(this.myVariable);
isString(this.myvariable);
and so on.
CMAKE_MAKE_PROGRAM not found
I tried to use CMake to build GammaRay for Qt on Windows with mingw. So, I had the Qt installed. And I had the same problem as other users here.
The approach that worked for me is launching cmake-gui from Qt build prompt (a shortcut created by Qt installer in "Start Menu\All programs\Qt{QT_VERSION}" folder).
"multiple target patterns" Makefile error
I also got this error (within the Eclipse-based STM32CubeIDE on Windows).
After double-clicking on the "multiple target patterns" error it showed a path to a .ld file. It turns out to be another "illegal character" problem. The offending character was the (wait for it): =
Heuristic of the week: use only [a..z] in your paths, as there are bound to be other illegal characters </vomit>.
The GNU make manual doesn't explicitly document this.
How to use 'git pull' from the command line?
Try setting the HOME environment variable in Windows to your home folder (c:\users\username).
( you can confirm that this is the problem by doing echo $HOME in git bash and echo %HOME% in cmd - latter might not be available )
Accessing AppDelegate from framework?
If you're creating a framework the whole idea is to make it portable. Tying a framework to the app delegate defeats the purpose of building a framework. What is it you need the app delegate for?
Running shell command and capturing the output
Something like that:
def runProcess(exe):
p = subprocess.Popen(exe, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
while(True):
# returns None while subprocess is running
retcode = p.poll()
line = p.stdout.readline()
yield line
if retcode is not None:
break
Note, that I'm redirecting stderr to stdout, it might not be exactly what you want, but I want error messages also.
This function yields line by line as they come (normally you'd have to wait for subprocess to finish to get the output as a whole).
For your case the usage would be:
for line in runProcess('mysqladmin create test -uroot -pmysqladmin12'.split()):
print line,
Convert this string to datetime
The Problem is with your code formatting,
inorder to use strtotime() You should replace '06/Oct/2011:19:00:02' with 06/10/2011 19:00:02 and date('d/M/Y:H:i:s', $date); with date('d/M/Y H:i:s', $date);. Note the spaces in between.
So the final code looks like this
$s = '06/10/2011 19:00:02';
$date = strtotime($s);
echo date('d/M/Y H:i:s', $date);
RSA Public Key format
Starting from the decoded base64 data of an OpenSSL rsa-ssh Key, i've been able to guess a format:
00 00 00 07: four byte length prefix (7 bytes)73 73 68 2d 72 73 61: "ssh-rsa"00 00 00 01: four byte length prefix (1 byte)25: RSA Exponent (e): 2500 00 01 00: four byte length prefix (256 bytes)RSA Modulus (
n):7f 9c 09 8e 8d 39 9e cc d5 03 29 8b c4 78 84 5f d9 89 f0 33 df ee 50 6d 5d d0 16 2c 73 cf ed 46 dc 7e 44 68 bb 37 69 54 6e 9e f6 f0 c5 c6 c1 d9 cb f6 87 78 70 8b 73 93 2f f3 55 d2 d9 13 67 32 70 e6 b5 f3 10 4a f5 c3 96 99 c2 92 d0 0f 05 60 1c 44 41 62 7f ab d6 15 52 06 5b 14 a7 d8 19 a1 90 c6 c1 11 f8 0d 30 fd f5 fc 00 bb a4 ef c9 2d 3f 7d 4a eb d2 dc 42 0c 48 b2 5e eb 37 3c 6c a0 e4 0a 27 f0 88 c4 e1 8c 33 17 33 61 38 84 a0 bb d0 85 aa 45 40 cb 37 14 bf 7a 76 27 4a af f4 1b ad f0 75 59 3e ac df cd fc 48 46 97 7e 06 6f 2d e7 f5 60 1d b1 99 f8 5b 4f d3 97 14 4d c5 5e f8 76 50 f0 5f 37 e7 df 13 b8 a2 6b 24 1f ff 65 d1 fb c8 f8 37 86 d6 df 40 e2 3e d3 90 2c 65 2b 1f 5c b9 5f fa e9 35 93 65 59 6d be 8c 62 31 a9 9b 60 5a 0e e5 4f 2d e6 5f 2e 71 f3 7e 92 8f fe 8b
The closest validation of my theory i can find it from RFC 4253:
The "ssh-rsa" key format has the following specific encoding:
string "ssh-rsa" mpint e mpint nHere the 'e' and 'n' parameters form the signature key blob.
But it doesn't explain the length prefixes.
Taking the random RSA PUBLIC KEY i found (in the question), and decoding the base64 into hex:
30 82 01 0a 02 82 01 01 00 fb 11 99 ff 07 33 f6 e8 05 a4 fd 3b 36 ca 68
e9 4d 7b 97 46 21 16 21 69 c7 15 38 a5 39 37 2e 27 f3 f5 1d f3 b0 8b 2e
11 1c 2d 6b bf 9f 58 87 f1 3a 8d b4 f1 eb 6d fe 38 6c 92 25 68 75 21 2d
dd 00 46 87 85 c1 8a 9c 96 a2 92 b0 67 dd c7 1d a0 d5 64 00 0b 8b fd 80
fb 14 c1 b5 67 44 a3 b5 c6 52 e8 ca 0e f0 b6 fd a6 4a ba 47 e3 a4 e8 94
23 c0 21 2c 07 e3 9a 57 03 fd 46 75 40 f8 74 98 7b 20 95 13 42 9a 90 b0
9b 04 97 03 d5 4d 9a 1c fe 3e 20 7e 0e 69 78 59 69 ca 5b f5 47 a3 6b a3
4d 7c 6a ef e7 9f 31 4e 07 d9 f9 f2 dd 27 b7 29 83 ac 14 f1 46 67 54 cd
41 26 25 16 e4 a1 5a b1 cf b6 22 e6 51 d3 e8 3f a0 95 da 63 0b d6 d9 3e
97 b0 c8 22 a5 eb 42 12 d4 28 30 02 78 ce 6b a0 cc 74 90 b8 54 58 1f 0f
fb 4b a3 d4 23 65 34 de 09 45 99 42 ef 11 5f aa 23 1b 15 15 3d 67 83 7a
63 02 03 01 00 01
From RFC3447 - Public-Key Cryptography Standards (PKCS) #1: RSA Cryptography Specifications Version 2.1:
A.1.1 RSA public key syntax
An RSA public key should be represented with the ASN.1 type
RSAPublicKey:RSAPublicKey ::= SEQUENCE { modulus INTEGER, -- n publicExponent INTEGER -- e }The fields of type RSAPublicKey have the following meanings:
- modulus is the RSA modulus n.
- publicExponent is the RSA public exponent e.
Using Microsoft's excellent (and the only real) ASN.1 documentation:
30 82 01 0a ;SEQUENCE (0x010A bytes: 266 bytes)
| 02 82 01 01 ;INTEGER (0x0101 bytes: 257 bytes)
| | 00 ;leading zero because high-bit, but number is positive
| | fb 11 99 ff 07 33 f6 e8 05 a4 fd 3b 36 ca 68
| | e9 4d 7b 97 46 21 16 21 69 c7 15 38 a5 39 37 2e 27 f3 f5 1d f3 b0 8b 2e
| | 11 1c 2d 6b bf 9f 58 87 f1 3a 8d b4 f1 eb 6d fe 38 6c 92 25 68 75 21 2d
| | dd 00 46 87 85 c1 8a 9c 96 a2 92 b0 67 dd c7 1d a0 d5 64 00 0b 8b fd 80
| | fb 14 c1 b5 67 44 a3 b5 c6 52 e8 ca 0e f0 b6 fd a6 4a ba 47 e3 a4 e8 94
| | 23 c0 21 2c 07 e3 9a 57 03 fd 46 75 40 f8 74 98 7b 20 95 13 42 9a 90 b0
| | 9b 04 97 03 d5 4d 9a 1c fe 3e 20 7e 0e 69 78 59 69 ca 5b f5 47 a3 6b a3
| | 4d 7c 6a ef e7 9f 31 4e 07 d9 f9 f2 dd 27 b7 29 83 ac 14 f1 46 67 54 cd
| | 41 26 25 16 e4 a1 5a b1 cf b6 22 e6 51 d3 e8 3f a0 95 da 63 0b d6 d9 3e
| | 97 b0 c8 22 a5 eb 42 12 d4 28 30 02 78 ce 6b a0 cc 74 90 b8 54 58 1f 0f
| | fb 4b a3 d4 23 65 34 de 09 45 99 42 ef 11 5f aa 23 1b 15 15 3d 67 83 7a
| | 63
| 02 03 ;INTEGER (3 bytes)
| 01 00 01
giving the public key modulus and exponent:
- modulus =
0xfb1199ff0733f6e805a4fd3b36ca68...837a63 - exponent = 65,537
Using subprocess to run Python script on Windows
It looks like windows tries to run the script using its own EXE framework rather than call it like
python /the/script.py
Try,
subprocess.Popen(["python", "/the/script.py"])
Edit: "python" would need to be on your path.
pgadmin4 : postgresql application server could not be contacted.
I found the same issue when upgrading to pgAdmin 4 (v1.6). On Windows I found that clearing out the C:\Users\%USERNAME%\AppData\Roaming\pgAdmin folder fixed the issue for me. I believe it was attempting to use the sessions from the prior version and was failing. I know the question was marked as answered, but downgrading may not always be an option.
Note: AppData\Roaming\pgAdmin is a hidden folder.
How to output (to a log) a multi-level array in a format that is human-readable?
Syntax
print_r(variable, return);
variable Required. Specifies the variable to return information about
return Optional. When set to true, this function will return the information (not print it). Default is false
Example
error_log( print_r(<array Variable>, TRUE) );
Why do I get "Exception; must be caught or declared to be thrown" when I try to compile my Java code?
In your 'encrypt' method, you should either get rid of the try/catch and instead add a try/catch around where you call encrypt (inside 'actionPerformed') or return null inside the catch within encrypt (that's the second error.
How can I use custom fonts on a website?
CSS lets you use custom fonts, downloadable fonts on your website. You can download the font of your preference, let’s say myfont.ttf, and upload it to your remote server where your blog or website is hosted.
@font-face {
font-family: myfont;
src: url('myfont.ttf');
}
Convert a char to upper case using regular expressions (EditPad Pro)
TextPad will allow you to perform this operation.
example:
test this sentence
Find what: \([^ ]*\) \(.*\)
Replace with: \U\1\E \2
the \U will cause all following chars to be upper
the \E will turn off the \U
the result will be:
TEST this sentence
Hadoop: «ERROR : JAVA_HOME is not set»
You can add in your .bashrc file:
export JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::")
and it will dynamically change when you update your packages.
How do I run Selenium in Xvfb?
The easiest way is probably to use xvfb-run:
DISPLAY=:1 xvfb-run java -jar selenium-server-standalone-2.0b3.jar
xvfb-run does the whole X authority dance for you, give it a try!
What does servletcontext.getRealPath("/") mean and when should I use it
Introduction
The ServletContext#getRealPath() is intented to convert a web content path (the path in the expanded WAR folder structure on the server's disk file system) to an absolute disk file system path.
The "/" represents the web content root. I.e. it represents the web folder as in the below project structure:
YourWebProject
|-- src
| :
|
|-- web
| |-- META-INF
| | `-- MANIFEST.MF
| |-- WEB-INF
| | `-- web.xml
| |-- index.jsp
| `-- login.jsp
:
So, passing the "/" to getRealPath() would return you the absolute disk file system path of the /web folder of the expanded WAR file of the project. Something like /path/to/server/work/folder/some.war/ which you should be able to further use in File or FileInputStream.
Note that most starters don't seem to see/realize that you can actually pass the whole web content path to it and that they often use
String absolutePathToIndexJSP = servletContext.getRealPath("/") + "index.jsp"; // Wrong!
or even
String absolutePathToIndexJSP = servletContext.getRealPath("") + "index.jsp"; // Wronger!
instead of
String absolutePathToIndexJSP = servletContext.getRealPath("/index.jsp"); // Right!
Don't ever write files in there
Also note that even though you can write new files into it using FileOutputStream, all changes (e.g. new files or edited files) will get lost whenever the WAR is redeployed; with the simple reason that all those changes are not contained in the original WAR file. So all starters who are attempting to save uploaded files in there are doing it wrong.
Moreover, getRealPath() will always return null or a completely unexpected path when the server isn't configured to expand the WAR file into the disk file system, but instead into e.g. memory as a virtual file system.
getRealPath() is unportable; you'd better never use it
Use getRealPath() carefully. There are actually no sensible real world use cases for it. Based on my 20 years of Java EE experience, there has always been another way which is much better and more portable than getRealPath().
If all you actually need is to get an InputStream of the web resource, better use ServletContext#getResourceAsStream() instead, this will work regardless of the way how the WAR is expanded. So, if you for example want an InputStream of index.jsp, then do not do:
InputStream input = new FileInputStream(servletContext.getRealPath("/index.jsp")); // Wrong!
But instead do:
InputStream input = servletContext.getResourceAsStream("/index.jsp"); // Right!
Or if you intend to obtain a list of all available web resource paths, use ServletContext#getResourcePaths() instead.
Set<String> resourcePaths = servletContext.getResourcePaths("/");
You can obtain an individual resource as URL via ServletContext#getResource(). This will return null when the resource does not exist.
URL resource = servletContext.getResource(path);
Or if you intend to save an uploaded file, or create a temporary file, then see the below "See also" links.
See also:
Swift: How to get substring from start to last index of character
I would do it using a subscript (s[start..<end]):
Swift 3, 4, 5
let s = "www.stackoverflow.com"
let start = s.startIndex
let end = s.index(s.endIndex, offsetBy: -4)
let substring = s[start..<end] // www.stackoverflow
Convert NVARCHAR to DATETIME in SQL Server 2008
alter table your_table
alter column LoginDate datetime;
SQLFiddle demo
How to add a line break in an Android TextView?
If you're using XML to declare your TextView use android:singleLine = "false" or in Java, use txtSubTitle.setSingleLine(false);
How do I install Composer on a shared hosting?
I was able to install composer on HostGator's shared hosting. Logged in to SSH with Putty, right after login you should be in your home directory, which is usually /home/username, where username is your username obviously. Then ran the curl command posted by @niutech above. This downloaded the composer to my home directory and it's now accessible and working well.
How to set the Android progressbar's height?
You can use the LinearProgressIndicator provided by the Material Components Library and the app:trackThickness attribute:
<com.google.android.material.progressindicator.LinearProgressIndicator
android:indeterminate="true"
app:trackThickness="xxdp"
../>
With 12dp:

With 4dp:

Note: it requires at least the version 1.3.0-alpha04.
Where is android_sdk_root? and how do I set it.?
in mac os you can try brew install gradle
Method to find string inside of the text file. Then getting the following lines up to a certain limit
I am doing something similar but in C++. What you need to do is read the lines in one at a time and parse them (go over the words one by one). I have an outter loop that goes over all the lines and inside that is another loop that goes over all the words. Once the word you need is found, just exit the loop and return a counter or whatever you want.
This is my code. It basically parses out all the words and adds them to the "index". The line that word was in is then added to a vector and used to reference the line (contains the name of the file, the entire line and the line number) from the indexed words.
ifstream txtFile;
txtFile.open(path, ifstream::in);
char line[200];
//if path is valid AND is not already in the list then add it
if(txtFile.is_open() && (find(textFilePaths.begin(), textFilePaths.end(), path) == textFilePaths.end())) //the path is valid
{
//Add the path to the list of file paths
textFilePaths.push_back(path);
int lineNumber = 1;
while(!txtFile.eof())
{
txtFile.getline(line, 200);
Line * ln = new Line(line, path, lineNumber);
lineNumber++;
myList.push_back(ln);
vector<string> words = lineParser(ln);
for(unsigned int i = 0; i < words.size(); i++)
{
index->addWord(words[i], ln);
}
}
result = true;
}
Generating random numbers in Objective-C
For game dev use random() to generate randoms. Probably at least 5x faster than using arc4random(). Modulo bias is not an issue, especially for games, when generating randoms using the full range of random(). Be sure to seed first. Call srandomdev() in AppDelegate. Here's some helper functions:
static inline int random_range(int low, int high){ return (random()%(high-low+1))+low;}
static inline CGFloat frandom(){ return (CGFloat)random()/UINT32_C(0x7FFFFFFF);}
static inline CGFloat frandom_range(CGFloat low, CGFloat high){ return (high-low)*frandom()+low;}
Getting NetworkCredential for current user (C#)
If the web service being invoked uses windows integrated security, creating a NetworkCredential from the current WindowsIdentity should be sufficient to allow the web service to use the current users windows login. However, if the web service uses a different security model, there isn't any way to extract a users password from the current identity ... that in and of itself would be insecure, allowing you, the developer, to steal your users passwords. You will likely need to provide some way for your user to provide their password, and keep it in some secure cache if you don't want them to have to repeatedly provide it.
Edit: To get the credentials for the current identity, use the following:
Uri uri = new Uri("http://tempuri.org/");
ICredentials credentials = CredentialCache.DefaultCredentials;
NetworkCredential credential = credentials.GetCredential(uri, "Basic");
How can I use onItemSelected in Android?
For Kotlin and bindings the code is:
binding.spinner.onItemSelectedListener = object : AdapterView.OnItemSelectedListener{
override fun onNothingSelected(parent: AdapterView<*>?) {
}
override fun onItemSelected(parent: AdapterView<*>?, view: View?, position: Int, id: Long) {
}
}
Get value from SimpleXMLElement Object
For me its easier to use arrays than objects,
So, I convert an Xml-Object,
$xml = simplexml_load_file('xml_file.xml');
$json_string = json_encode($xml);
$result_array = json_decode($json_string, TRUE);
How to access route, post, get etc. parameters in Zend Framework 2
require_once 'lib/Zend/Loader/StandardAutoloader.php';
$loader = new Zend\Loader\StandardAutoloader(array('autoregister_zf' => true));
$loader->registerNamespace('Http\PhpEnvironment', 'lib/Zend/Http');
// Register with spl_autoload:
$loader->register();
$a = new Zend\Http\PhpEnvironment\Request();
print_r($a->getQuery()->get()); exit;
What's the difference between jquery.js and jquery.min.js?
jquery.min is compress version. It's removed comments, new lines, ...
How to delete a record by id in Flask-SQLAlchemy
You can do this,
User.query.filter_by(id=123).delete()
or
User.query.filter(User.id == 123).delete()
Make sure to commit for delete() to take effect.
MySQL: Quick breakdown of the types of joins
Full Outer join don't exist in mysql , you might need to use a combination of left and right join.
Nginx Different Domains on Same IP
Your "listen" directives are wrong. See this page: http://nginx.org/en/docs/http/server_names.html.
They should be
server {
listen 80;
server_name www.domain1.com;
root /var/www/domain1;
}
server {
listen 80;
server_name www.domain2.com;
root /var/www/domain2;
}
Note, I have only included the relevant lines. Everything else looked okay but I just deleted it for clarity. To test it you might want to try serving a text file from each server first before actually serving php. That's why I left the 'root' directive in there.
Confused about stdin, stdout and stderr?
stdin
Reads input through the console (e.g. Keyboard input). Used in C with scanf
scanf(<formatstring>,<pointer to storage> ...);
stdout
Produces output to the console. Used in C with printf
printf(<string>, <values to print> ...);
stderr
Produces 'error' output to the console. Used in C with fprintf
fprintf(stderr, <string>, <values to print> ...);
Redirection
The source for stdin can be redirected. For example, instead of coming from keyboard input, it can come from a file (echo < file.txt ), or another program ( ps | grep <userid>).
The destinations for stdout, stderr can also be redirected. For example stdout can be redirected to a file: ls . > ls-output.txt, in this case the output is written to the file ls-output.txt. Stderr can be redirected with 2>.
Access files stored on Amazon S3 through web browser
You can use a bucket policy to give anonymous users full read access to your objects. Depending on whether you need them to LIST or just perform a GET, you'll want to tweak this. (I.e. permissions for listing the contents of a bucket have the action set to "s3:ListBucket").
http://docs.aws.amazon.com/AmazonS3/latest/dev/AccessPolicyLanguage_UseCases_s3_a.html
Your policy will look something like the following. You can use the S3 console at http://aws.amazon.com/console to upload it.
{
"Version":"2008-10-17",
"Statement":[{
"Sid":"AddPerm",
"Effect":"Allow",
"Principal": {
"AWS": "*"
},
"Action":["s3:GetObject"],
"Resource":["arn:aws:s3:::bucket/*"
]
}
]
}
If you're truly opening up your objects to the world, you'll want to look into setting up CloudWatch rules on your billing so you can shut off permissions to your objects if they become too popular.
SQL Server FOR EACH Loop
Off course an old question. But I have a simple solution where no need of Looping, CTE, Table variables etc.
DECLARE @MyVar datetime = '1/1/2010'
SELECT @MyVar
SELECT DATEADD (DD,NUMBER,@MyVar)
FROM master.dbo.spt_values
WHERE TYPE='P' AND NUMBER BETWEEN 0 AND 4
ORDER BY NUMBER
Note : spt_values is a Mircrosoft's undocumented table. It has numbers for every type. Its not suggestible to use as it can be removed in any new versions of sql server without prior information, since it is undocumented. But we can use it as quick workaround in some scenario's like above.
Setting up FTP on Amazon Cloud Server
To enable passive ftp on an EC2 server, you need to configure the ports that your ftp server should use for inbound connections, then open a list of available ports for the ftp client data connections.
I'm not that familiar with linux, but the commands you posted are the steps to install the ftp server, configure the ec2 firewall rules (through the AWS API), then configure the ftp server to use the ports you allowed on the ec2 firewall.
So this step installs the ftp client (VSFTP)
> yum install vsftpd
These steps configure the ftp client
> vi /etc/vsftpd/vsftpd.conf
-- Add following lines at the end of file --
pasv_enable=YES
pasv_min_port=1024
pasv_max_port=1048
pasv_address=<Public IP of your instance>
> /etc/init.d/vsftpd restart
but the other two steps are easier done through the amazon console under EC2 Security groups. There you need to configure the security group that is assigned to your server to allow connections on ports 20,21, and 1024-1048
Upload a file to Amazon S3 with NodeJS
Uploading a file to AWS s3 and sending the url in response for accessing the file.
Multer is a node.js middleware for handling multipart/form-data, which is primarily used for uploading files. It is written on top of busboy for maximum efficiency. check this npm module here.
When you are sending the request, make sure the headers, have Content-Type is multipart/form-data. We are sending the file location in the response, which will give the url, but if you want to access that url, make the bucket public or else you will not be able to access it.
upload.router.js
const express = require('express');
const router = express.Router();
const AWS = require('aws-sdk');
const multer = require('multer');
const storage = multer.memoryStorage()
const upload = multer({storage: storage});
const s3Client = new AWS.S3({
accessKeyId: 'your_access_key_id',
secretAccessKey: 'your_secret_access_id',
region :'ur region'
});
const uploadParams = {
Bucket: 'ur_bucket_name',
Key: '', // pass key
Body: null, // pass file body
};
router.post('/api/file/upload', upload.single("file"),(req,res) => {
const params = uploadParams;
uploadParams.Key = req.file.originalname;
uploadParams.Body = req.file.buffer;
s3Client.upload(params, (err, data) => {
if (err) {
res.status(500).json({error:"Error -> " + err});
}
res.json({message: 'File uploaded successfully','filename':
req.file.originalname, 'location': data.Location});
});
});
module.exports = router;
app.js
const express = require('express');
const app = express();
const router = require('./app/routers/upload.router.js');
app.use('/', router);
// Create a Server
const server = app.listen(8080, () => {
console.log("App listening at 8080");
})
SQL Update Multiple Fields FROM via a SELECT Statement
Something like this should work (can't test it right now - from memory):
UPDATE SHIPMENT
SET
OrgAddress1 = BD.OrgAddress1,
OrgAddress2 = BD.OrgAddress2,
OrgCity = BD.OrgCity,
OrgState = BD.OrgState,
OrgZip = BD.OrgZip,
DestAddress1 = BD.DestAddress1,
DestAddress2 = BD.DestAddress2,
DestCity = BD.DestCity,
DestState = BD.DestState,
DestZip = BD.DestZip
FROM
BookingDetails BD
WHERE
SHIPMENT.MyID2 = @MyID2
AND
BD.MyID = @MyID
Does that help?
What is a thread exit code?
There actually doesn't seem to be a lot of explanation on this subject apparently but the exit codes are supposed to be used to give an indication on how the thread exited, 0 tends to mean that it exited safely whilst anything else tends to mean it didn't exit as expected. But then this exit code can be set in code by yourself to completely overlook this.
The closest link I could find to be useful for more information is this
Quote from above link:
What ever the method of exiting, the integer that you return from your process or thread must be values from 0-255(8bits). A zero value indicates success, while a non zero value indicates failure. Although, you can attempt to return any integer value as an exit code, only the lowest byte of the integer is returned from your process or thread as part of an exit code. The higher order bytes are used by the operating system to convey special information about the process. The exit code is very useful in batch/shell programs which conditionally execute other programs depending on the success or failure of one.
From the Documentation for GetEXitCodeThread
Important The GetExitCodeThread function returns a valid error code defined by the application only after the thread terminates. Therefore, an application should not use STILL_ACTIVE (259) as an error code. If a thread returns STILL_ACTIVE (259) as an error code, applications that test for this value could interpret it to mean that the thread is still running and continue to test for the completion of the thread after the thread has terminated, which could put the application into an infinite loop.
My understanding of all this is that the exit code doesn't matter all that much if you are using threads within your own application for your own application. The exception to this is possibly if you are running a couple of threads at the same time that have a dependency on each other. If there is a requirement for an outside source to read this error code, then you can set it to let other applications know the status of your thread.
INSTALL_FAILED_USER_RESTRICTED : android studio using redmi 4 device
With Xiaomi Redmi note 8 pro (MIUI 10.4.4), Android 9 -
While connecting to Vysor (2.1.2) from Windows PC (via USB cable), received the error message:
"Error installing APK: Failure [INSTALL_FAILED_USER_RESTRICTED]"
even after turning "USB Debugging" On.
So the following settings were required -
- Developer options (On)
- USB debugging (On)
- Install via USB (On)
Leave the following,
- Turn on MIUI optimization (On)
- Verify apps over USB (On)
String split on new line, tab and some number of spaces
Regex's aren't really the best tool for the job here. As others have said, using a combination of str.strip() and str.split() is the way to go. Here's a one liner to do it:
>>> data = '''\n\tName: John Smith
... \n\t Home: Anytown USA
... \n\t Phone: 555-555-555
... \n\t Other Home: Somewhere Else
... \n\t Notes: Other data
... \n\tName: Jane Smith
... \n\t Misc: Data with spaces'''
>>> {line.strip().split(': ')[0]:line.split(': ')[1] for line in data.splitlines() if line.strip() != ''}
{'Name': 'Jane Smith', 'Other Home': 'Somewhere Else', 'Notes': 'Other data', 'Misc': 'Data with spaces', 'Phone': '555-555-555', 'Home': 'Anytown USA'}
Java unsupported major minor version 52.0
You have to compile with Java 1.7. But if you have *.jsp files, you should also completely remove Java 1.8 from the system. If you use Mac, here is how you can do it.
Http Servlet request lose params from POST body after read it once
So this is basically Lathy's answer BUT updated for newer requirements for ServletInputStream.
Namely (for ServletInputStream), one has to implement:
public abstract boolean isFinished();
public abstract boolean isReady();
public abstract void setReadListener(ReadListener var1);
This is the edited Lathy's object
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import javax.servlet.ServletInputStream;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletRequestWrapper;
public class RequestWrapper extends HttpServletRequestWrapper {
private String _body;
public RequestWrapper(HttpServletRequest request) throws IOException {
super(request);
_body = "";
BufferedReader bufferedReader = request.getReader();
String line;
while ((line = bufferedReader.readLine()) != null){
_body += line;
}
}
@Override
public ServletInputStream getInputStream() throws IOException {
CustomServletInputStream kid = new CustomServletInputStream(_body.getBytes());
return kid;
}
@Override
public BufferedReader getReader() throws IOException {
return new BufferedReader(new InputStreamReader(this.getInputStream()));
}
}
and somewhere (??) I found this (which is a first-class class that deals with the "extra" methods.
import javax.servlet.ReadListener;
import javax.servlet.ServletInputStream;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
public class CustomServletInputStream extends ServletInputStream {
private byte[] myBytes;
private int lastIndexRetrieved = -1;
private ReadListener readListener = null;
public CustomServletInputStream(String s) {
try {
this.myBytes = s.getBytes("UTF-8");
} catch (UnsupportedEncodingException ex) {
throw new IllegalStateException("JVM did not support UTF-8", ex);
}
}
public CustomServletInputStream(byte[] inputBytes) {
this.myBytes = inputBytes;
}
@Override
public boolean isFinished() {
return (lastIndexRetrieved == myBytes.length - 1);
}
@Override
public boolean isReady() {
// This implementation will never block
// We also never need to call the readListener from this method, as this method will never return false
return isFinished();
}
@Override
public void setReadListener(ReadListener readListener) {
this.readListener = readListener;
if (!isFinished()) {
try {
readListener.onDataAvailable();
} catch (IOException e) {
readListener.onError(e);
}
} else {
try {
readListener.onAllDataRead();
} catch (IOException e) {
readListener.onError(e);
}
}
}
@Override
public int read() throws IOException {
int i;
if (!isFinished()) {
i = myBytes[lastIndexRetrieved + 1];
lastIndexRetrieved++;
if (isFinished() && (readListener != null)) {
try {
readListener.onAllDataRead();
} catch (IOException ex) {
readListener.onError(ex);
throw ex;
}
}
return i;
} else {
return -1;
}
}
};
Ultimately, I was just trying to log the requests. And the above frankensteined together pieces helped me create the below.
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.security.Principal;
import java.util.Enumeration;
import java.util.LinkedHashMap;
import java.util.Map;
import javax.servlet.FilterChain;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.io.IOUtils;
//one or the other based on spring version
//import org.springframework.boot.autoconfigure.web.ErrorAttributes;
import org.springframework.boot.web.servlet.error.ErrorAttributes;
import org.springframework.core.Ordered;
import org.springframework.http.HttpStatus;
import org.springframework.stereotype.Component;
import org.springframework.web.context.request.ServletRequestAttributes;
import org.springframework.web.context.request.WebRequest;
import org.springframework.web.filter.OncePerRequestFilter;
/**
* A filter which logs web requests that lead to an error in the system.
*/
@Component
public class LogRequestFilter extends OncePerRequestFilter implements Ordered {
// I tried apache.commons and slf4g loggers. (one or the other in these next 2 lines of declaration */
//private final static org.apache.commons.logging.Log logger = org.apache.commons.logging.LogFactory.getLog(LogRequestFilter.class);
private static final org.slf4j.Logger logger = org.slf4j.LoggerFactory.getLogger(LogRequestFilter.class);
// put filter at the end of all other filters to make sure we are processing after all others
private int order = Ordered.LOWEST_PRECEDENCE - 8;
private ErrorAttributes errorAttributes;
@Override
public int getOrder() {
return order;
}
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain)
throws ServletException, IOException {
String temp = ""; /* for a breakpoint, remove for production/real code */
/* change to true for easy way to comment out this code, remove this if-check for production/real code */
if (false) {
filterChain.doFilter(request, response);
return;
}
/* make a "copy" to avoid issues with body-can-only-read-once issues */
RequestWrapper reqWrapper = new RequestWrapper(request);
int status = HttpStatus.INTERNAL_SERVER_ERROR.value();
// pass through filter chain to do the actual request handling
filterChain.doFilter(reqWrapper, response);
status = response.getStatus();
try {
Map<String, Object> traceMap = getTrace(reqWrapper, status);
// body can only be read after the actual request handling was done!
this.getBodyFromTheRequestCopy(reqWrapper, traceMap);
/* now do something with all the pieces of information gatherered */
this.logTrace(reqWrapper, traceMap);
} catch (Exception ex) {
logger.error("LogRequestFilter FAILED: " + ex.getMessage(), ex);
}
}
private void getBodyFromTheRequestCopy(RequestWrapper rw, Map<String, Object> trace) {
try {
if (rw != null) {
byte[] buf = IOUtils.toByteArray(rw.getInputStream());
//byte[] buf = rw.getInputStream();
if (buf.length > 0) {
String payloadSlimmed;
try {
String payload = new String(buf, 0, buf.length, rw.getCharacterEncoding());
payloadSlimmed = payload.trim().replaceAll(" +", " ");
} catch (UnsupportedEncodingException ex) {
payloadSlimmed = "[unknown]";
}
trace.put("body", payloadSlimmed);
}
}
} catch (IOException ioex) {
trace.put("body", "EXCEPTION: " + ioex.getMessage());
}
}
private void logTrace(HttpServletRequest request, Map<String, Object> trace) {
Object method = trace.get("method");
Object path = trace.get("path");
Object statusCode = trace.get("statusCode");
logger.info(String.format("%s %s produced an status code '%s'. Trace: '%s'", method, path, statusCode,
trace));
}
protected Map<String, Object> getTrace(HttpServletRequest request, int status) {
Throwable exception = (Throwable) request.getAttribute("javax.servlet.error.exception");
Principal principal = request.getUserPrincipal();
Map<String, Object> trace = new LinkedHashMap<String, Object>();
trace.put("method", request.getMethod());
trace.put("path", request.getRequestURI());
if (null != principal) {
trace.put("principal", principal.getName());
}
trace.put("query", request.getQueryString());
trace.put("statusCode", status);
Enumeration headerNames = request.getHeaderNames();
while (headerNames.hasMoreElements()) {
String key = (String) headerNames.nextElement();
String value = request.getHeader(key);
trace.put("header:" + key, value);
}
if (exception != null && this.errorAttributes != null) {
trace.put("error", this.errorAttributes
.getErrorAttributes((WebRequest) new ServletRequestAttributes(request), true));
}
return trace;
}
}
Please take this code with a grain of salt.
The MOST important "test" is if a POST works with a payload. This is what will expose "double read" issues.
pseudo example code
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("myroute")
public class MyController {
@RequestMapping(method = RequestMethod.POST, produces = "application/json")
@ResponseBody
public String getSomethingExample(@RequestBody MyCustomObject input) {
String returnValue = "";
return returnValue;
}
}
You can replace "MyCustomObject" with plain ole "Object" if you just want to test.
This answer is frankensteined from several different SOF posts and examples..but it took a while to pull it all together so I hope it helps a future reader.
Please upvote Lathy's answer before mine. I could have not gotten this far without it.
Below is one/some of the exceptions I got while working this out.
getReader() has already been called for this request
Looks like some of the places I "borrowed" from are here:
http://slackspace.de/articles/log-request-body-with-spring-boot/
https://howtodoinjava.com/servlets/httpservletrequestwrapper-example-read-request-body/
https://www.oodlestechnologies.com/blogs/How-to-create-duplicate-object-of-httpServletRequest-object
January 2021 APPEND.
I have learned the hard way that the above code does NOT work for
x-www-form-urlencoded
Consider the example below:
@CrossOrigin
@ResponseBody
@PostMapping(path = "/mypath", consumes = {MediaType.APPLICATION_FORM_URLENCODED_VALUE})
public ResponseEntity myMethodName(@RequestParam Map<String, String> parameters
) {
/* DO YOU GET ANY PARAMETERS HERE? Or are they empty because of logging/auditing filter ?*/
return new ResponseEntity(HttpStatus.OK);
}
I had to go through several of the other examples here.
I came up with a "wrapper" that works explicitly for APPLICATION_FORM_URLENCODED_VALUE
import org.apache.commons.io.IOUtils;
import org.springframework.http.MediaType;
import org.springframework.web.util.ContentCachingRequestWrapper;
import javax.servlet.ServletInputStream;
import javax.servlet.http.HttpServletRequest;
import java.io.IOException;
/**
* Makes a "copy" of the HttpRequest so the body can be accessed more than 1 time.
* WORKS WITH APPLICATION_FORM_URLENCODED_VALUE
* See : https://stackoverflow.com/questions/44182370/why-do-we-wrap-httpservletrequest-the-api-provides-an-httpservletrequestwrappe/44187955#44187955
*/
public final class AppFormUrlEncodedSpecificContentCachingRequestWrapper extends ContentCachingRequestWrapper {
public static final String ERROR_MSG_CONTENT_TYPE_NOT_SUPPORTED = "ContentType not supported. (Input ContentType(s)=\"%1$s\", Supported ContentType(s)=\"%2$s\")";
public static final String ERROR_MSG_PERSISTED_CONTENT_CACHING_REQUEST_WRAPPER_CONSTRUCTOR_FAILED = "AppFormUrlEncodedSpecificContentCachingRequestWrapper constructor failed";
private static final org.slf4j.Logger LOGGER = org.slf4j.LoggerFactory.getLogger(AppFormUrlEncodedSpecificContentCachingRequestWrapper.class);
private byte[] body;
private ServletInputStream inputStream;
public AppFormUrlEncodedSpecificContentCachingRequestWrapper(HttpServletRequest request) {
super(request);
super.getParameterMap(); // init cache in ContentCachingRequestWrapper. THIS IS THE VITAL CALL so that "@RequestParam Map<String, String> parameters" are populated on the REST Controller. See https://stackoverflow.com/questions/10210645/http-servlet-request-lose-params-from-post-body-after-read-it-once/64924380#64924380
String contentType = request.getContentType();
/* EXPLICTLY check for APPLICATION_FORM_URLENCODED_VALUE and allow nothing else */
if (null == contentType || !contentType.equalsIgnoreCase(MediaType.APPLICATION_FORM_URLENCODED_VALUE)) {
IllegalArgumentException ioex = new IllegalArgumentException(String.format(ERROR_MSG_CONTENT_TYPE_NOT_SUPPORTED, contentType, MediaType.APPLICATION_FORM_URLENCODED_VALUE));
LOGGER.error(ERROR_MSG_PERSISTED_CONTENT_CACHING_REQUEST_WRAPPER_CONSTRUCTOR_FAILED, ioex);
throw ioex;
}
try {
loadBody(request);
} catch (IOException ioex) {
throw new RuntimeException(ioex);
}
}
private void loadBody(HttpServletRequest request) throws IOException {
body = IOUtils.toByteArray(request.getInputStream());
inputStream = new CustomServletInputStream(this.getBody());
}
private byte[] getBody() {
return body;
}
@Override
public ServletInputStream getInputStream() throws IOException {
if (inputStream != null) {
return inputStream;
}
return super.getInputStream();
}
}
Note Andrew Sneck's answer on this same page. It is pretty much this : https://programmersought.com/article/23981013626/
I have not had time to harmonize the two above implementations (my two that is).
So I created a Factory to "choose" from the two:
import org.springframework.http.MediaType;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletRequestWrapper;
import java.io.IOException;
/**
* Factory to return different concretes of HttpServletRequestWrapper. APPLICATION_FORM_URLENCODED_VALUE needs a different concrete.
*/
public class HttpServletRequestWrapperFactory {
public static final String ERROR_MSG_HTTP_SERVLET_REQUEST_WRAPPER_FACTORY_CREATE_HTTP_SERVLET_REQUEST_WRAPPER_FAILED = "HttpServletRequestWrapperFactory createHttpServletRequestWrapper FAILED";
public static HttpServletRequestWrapper createHttpServletRequestWrapper(final HttpServletRequest request) {
HttpServletRequestWrapper returnItem = null;
if (null != request) {
String contentType = request.getContentType();
if (null != contentType && contentType.equalsIgnoreCase(MediaType.APPLICATION_FORM_URLENCODED_VALUE)) {
returnItem = new AppFormUrlEncodedSpecificContentCachingRequestWrapper(request);
} else {
try {
returnItem = new PersistedBodyRequestWrapper(request);
} catch (IOException ioex) {
throw new RuntimeException(ERROR_MSG_HTTP_SERVLET_REQUEST_WRAPPER_FACTORY_CREATE_HTTP_SERVLET_REQUEST_WRAPPER_FAILED, ioex);
}
}
}
return returnItem;
}
}
Below is the "other" one that works with JSON, etc. It is the other concrete that the Factory can output. I put it here so that my Jan 2021 APPEND is consistent..I don't know if the code below is perfect consistent with my original answer:
import org.springframework.http.MediaType;
import javax.servlet.ServletInputStream;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletRequestWrapper;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;
import java.util.Map;
/**
* Makes a "copy" of the HttpRequest so the body can be accessed more than 1 time.
* See : https://stackoverflow.com/questions/44182370/why-do-we-wrap-httpservletrequest-the-api-provides-an-httpservletrequestwrappe/44187955#44187955
* DOES NOT WORK WITH APPLICATION_FORM_URLENCODED_VALUE
*/
public final class PersistedBodyRequestWrapper extends HttpServletRequestWrapper {
public static final String ERROR_MSG_CONTENT_TYPE_NOT_SUPPORTED = "ContentType not supported. (ContentType=\"%1$s\")";
public static final String ERROR_MSG_PERSISTED_BODY_REQUEST_WRAPPER_CONSTRUCTOR_FAILED = "PersistedBodyRequestWrapper constructor FAILED";
private static final org.slf4j.Logger LOGGER = org.slf4j.LoggerFactory.getLogger(PersistedBodyRequestWrapper.class);
private String persistedBody;
private final Map<String, String[]> parameterMap;
public PersistedBodyRequestWrapper(final HttpServletRequest request) throws IOException {
super(request);
String contentType = request.getContentType();
/* Allow everything EXCEPT APPLICATION_FORM_URLENCODED_VALUE */
if (null != contentType && contentType.equalsIgnoreCase(MediaType.APPLICATION_FORM_URLENCODED_VALUE)) {
IllegalArgumentException ioex = new IllegalArgumentException(String.format(ERROR_MSG_CONTENT_TYPE_NOT_SUPPORTED, MediaType.APPLICATION_FORM_URLENCODED_VALUE));
LOGGER.error(ERROR_MSG_PERSISTED_BODY_REQUEST_WRAPPER_CONSTRUCTOR_FAILED, ioex);
throw ioex;
}
parameterMap = request.getParameterMap();
this.persistedBody = "";
BufferedReader bufferedReader = request.getReader();
String line;
while ((line = bufferedReader.readLine()) != null) {
this.persistedBody += line;
}
}
@Override
public ServletInputStream getInputStream() throws IOException {
CustomServletInputStream csis = new CustomServletInputStream(this.persistedBody.getBytes(StandardCharsets.UTF_8));
return csis;
}
@Override
public BufferedReader getReader() throws IOException {
return new BufferedReader(new InputStreamReader(this.getInputStream()));
}
@Override
public Map<String, String[]> getParameterMap() {
return this.parameterMap;
}
}
CSS background image to fit height, width should auto-scale in proportion
background-size: contain;
suits me
A SELECT statement that assigns a value to a variable must not be combined with data-retrieval operations
declare @cur cursor
declare @idx int
declare @Approval_No varchar(50)
declare @ReqNo varchar(100)
declare @M_Id varchar(100)
declare @Mail_ID varchar(100)
declare @temp table
(
val varchar(100)
)
declare @temp2 table
(
appno varchar(100),
mailid varchar(100),
userod varchar(100)
)
declare @slice varchar(8000)
declare @String varchar(100)
--set @String = '1200096,1200095,1200094,1200093,1200092,1200092'
set @String = '20131'
select @idx = 1
if len(@String)<1 or @String is null return
while @idx!= 0
begin
set @idx = charindex(',',@String)
if @idx!=0
set @slice = left(@String,@idx - 1)
else
set @slice = @String
--select @slice
insert into @temp values(@slice)
set @String = right(@String,len(@String) - @idx)
if len(@String) = 0 break
end
-- select distinct(val) from @temp
SET @cur = CURSOR FOR select distinct(val) from @temp
--open cursor
OPEN @cur
--fetchng id into variable
FETCH NEXT
FROM @cur into @Approval_No
--
--loop still the end
while @@FETCH_STATUS = 0
BEGIN
select distinct(Approval_Sr_No) as asd, @ReqNo=Approval_Sr_No,@M_Id=AM_ID,@Mail_ID=Mail_ID from WFMS_PRAO,WFMS_USERMASTER where WFMS_PRAO.AM_ID=WFMS_USERMASTER.User_ID
and Approval_Sr_No=@Approval_No
insert into @temp2 values(@ReqNo,@M_Id,@Mail_ID)
FETCH NEXT
FROM @cur into @Approval_No
end
--close cursor
CLOSE @cur
select * from @tem
MySQL VARCHAR size?
VARCHAR means that it's a variable-length character, so it's only going to take as much space as is necessary. But if you knew something about the underlying structure, it may make sense to restrict VARCHAR to some maximum amount.
For instance, if you were storing comments from the user, you may limit the comment field to only 4000 characters; if so, it doesn't really make any sense to make the sql table have a field that's larger than VARCHAR(4000).
Remove items from one list in another
Solution 1 : You can do like this :
List<car> result = GetSomeOtherList().Except(GetTheList()).ToList();
But in some cases may this solution not work. if it is not work you can use my second solution .
Solution 2 :
List<car> list1 = GetTheList();
List<car> list2 = GetSomeOtherList();
we pretend that list1 is your main list and list2 is your secondry list and you want to get items of list1 without items of list2.
var result = list1.Where(p => !list2.Any(x => x.ID == p.ID && x.property1 == p.property1)).ToList();
Python Socket Multiple Clients
Here is the example from the SocketServer documentation which would make an excellent starting point
import SocketServer
class MyTCPHandler(SocketServer.BaseRequestHandler):
"""
The RequestHandler class for our server.
It is instantiated once per connection to the server, and must
override the handle() method to implement communication to the
client.
"""
def handle(self):
# self.request is the TCP socket connected to the client
self.data = self.request.recv(1024).strip()
print "{} wrote:".format(self.client_address[0])
print self.data
# just send back the same data, but upper-cased
self.request.sendall(self.data.upper())
if __name__ == "__main__":
HOST, PORT = "localhost", 9999
# Create the server, binding to localhost on port 9999
server = SocketServer.TCPServer((HOST, PORT), MyTCPHandler)
# Activate the server; this will keep running until you
# interrupt the program with Ctrl-C
server.serve_forever()
Try it from a terminal like this
$ telnet localhost 9999
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
Hello
HELLOConnection closed by foreign host.
$ telnet localhost 9999
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
Sausage
SAUSAGEConnection closed by foreign host.
You'll probably need to use A Forking or Threading Mixin too
SQL Server Installation - What is the Installation Media Folder?
Check in Administration Tools\Services (or type services.msc in the console if you a service named SQL Server (SQLEXPRESS). If you do then it is installed.
From Visual Studio open Server Explorer (menu View\Server Explorer or CTRL + W, L). Right click Data Connections and choose Create New SQL Server Database. After that create tables and stuff...
If you want the Management Studio to manage the server you must download and install it from:
Chaining multiple filter() in Django, is this a bug?
These two style of filtering are equivalent in most cases, but when query on objects base on ForeignKey or ManyToManyField, they are slightly different.
Examples from the documentation.
model
Blog to Entry is a one-to-many relation.
from django.db import models
class Blog(models.Model):
...
class Entry(models.Model):
blog = models.ForeignKey(Blog)
headline = models.CharField(max_length=255)
pub_date = models.DateField()
...
objects
Assuming there are some blog and entry objects here.
queries
Blog.objects.filter(entry__headline_contains='Lennon',
entry__pub_date__year=2008)
Blog.objects.filter(entry__headline_contains='Lennon').filter(
entry__pub_date__year=2008)
For the 1st query (single filter one), it match only blog1.
For the 2nd query (chained filters one), it filters out blog1 and blog2.
The first filter restricts the queryset to blog1, blog2 and blog5; the second filter restricts the set of blogs further to blog1 and blog2.
And you should realize that
We are filtering the Blog items with each filter statement, not the Entry items.
So, it's not the same, because Blog and Entry are multi-valued relationships.
Reference: https://docs.djangoproject.com/en/1.8/topics/db/queries/#spanning-multi-valued-relationships
If there is something wrong, please correct me.
Edit: Changed v1.6 to v1.8 since the 1.6 links are no longer available.
Difference between ${} and $() in Bash
your understanding is right. For detailed info on {} see bash ref - parameter expansion
'for' and 'while' have different syntax and offer different styles of programmer control for an iteration. Most non-asm languages offer a similar syntax.
With while, you would probably write i=0; while [ $i -lt 10 ]; do echo $i; i=$(( i + 1 )); done in essence manage everything about the iteration yourself
BitBucket - download source as ZIP
I was trying to figure out if it's possible to browse the code of an earlier commit like you can on GitHub and it brought me here. I used the information I found here, and after fiddling around with the urls, I actually found a way to browse code of old commits as well. Even though the question/answer is about downloading the code of an earlier commit, I thought I'd just add an answer for browsing the code also.
When you're browsing your code the URL is something like:
https://bitbucket.org/user/repo/src/
and by adding a commit hash at the end like this:
https://bitbucket.org/user/repo/src/a0328cb
You can browse the code at the point of that commit. I don't understand why there's no dropdown box for choosing a commit directly, the feature is already there. Strange.
Error: Failed to execute 'appendChild' on 'Node': parameter 1 is not of type 'Node'
This can happen if you accidentally are not dragging the element that does have an id assigned (for example you are dragging the surrounding element). In that case the ID is empty and the function drag() is assigning an empty value which is then passed to drop() and fails there.
Try assigning the ids to all of your elements, including the tds, divs, or whatever is around your draggable element.
getting the index of a row in a pandas apply function
To access the index in this case you access the name attribute:
In [182]:
df = pd.DataFrame([[1,2,3],[4,5,6]], columns=['a','b','c'])
def rowFunc(row):
return row['a'] + row['b'] * row['c']
def rowIndex(row):
return row.name
df['d'] = df.apply(rowFunc, axis=1)
df['rowIndex'] = df.apply(rowIndex, axis=1)
df
Out[182]:
a b c d rowIndex
0 1 2 3 7 0
1 4 5 6 34 1
Note that if this is really what you are trying to do that the following works and is much faster:
In [198]:
df['d'] = df['a'] + df['b'] * df['c']
df
Out[198]:
a b c d
0 1 2 3 7
1 4 5 6 34
In [199]:
%timeit df['a'] + df['b'] * df['c']
%timeit df.apply(rowIndex, axis=1)
10000 loops, best of 3: 163 µs per loop
1000 loops, best of 3: 286 µs per loop
EDIT
Looking at this question 3+ years later, you could just do:
In[15]:
df['d'],df['rowIndex'] = df['a'] + df['b'] * df['c'], df.index
df
Out[15]:
a b c d rowIndex
0 1 2 3 7 0
1 4 5 6 34 1
but assuming it isn't as trivial as this, whatever your rowFunc is really doing, you should look to use the vectorised functions, and then use them against the df index:
In[16]:
df['newCol'] = df['a'] + df['b'] + df['c'] + df.index
df
Out[16]:
a b c d rowIndex newCol
0 1 2 3 7 0 6
1 4 5 6 34 1 16
How to read string from keyboard using C?
When reading input from any file (stdin included) where you do not know the length, it is often better to use getline rather than scanf or fgets because getline will handle memory allocation for your string automatically so long as you provide a null pointer to receive the string entered. This example will illustrate:
#include <stdio.h>
#include <stdlib.h>
int main (int argc, char *argv[]) {
char *line = NULL; /* forces getline to allocate with malloc */
size_t len = 0; /* ignored when line = NULL */
ssize_t read;
printf ("\nEnter string below [ctrl + d] to quit\n");
while ((read = getline(&line, &len, stdin)) != -1) {
if (read > 0)
printf ("\n read %zd chars from stdin, allocated %zd bytes for line : %s\n", read, len, line);
printf ("Enter string below [ctrl + d] to quit\n");
}
free (line); /* free memory allocated by getline */
return 0;
}
The relevant parts being:
char *line = NULL; /* forces getline to allocate with malloc */
size_t len = 0; /* ignored when line = NULL */
/* snip */
read = getline (&line, &len, stdin);
Setting line to NULL causes getline to allocate memory automatically. Example output:
$ ./getline_example
Enter string below [ctrl + d] to quit
A short string to test getline!
read 32 chars from stdin, allocated 120 bytes for line : A short string to test getline!
Enter string below [ctrl + d] to quit
A little bit longer string to show that getline will allocated again without resetting line = NULL
read 99 chars from stdin, allocated 120 bytes for line : A little bit longer string to show that getline will allocated again without resetting line = NULL
Enter string below [ctrl + d] to quit
So with getline you do not need to guess how long your user's string will be.
What do the result codes in SVN mean?
I usually use svn through a gui, either my IDE or a client. Because of that, I can never remember the codes when I do have to resort to the command line.
I find this cheat sheet a great help: Subversion Cheat Sheet
Remove characters from a String in Java
Strings in java are immutable. That means you need to create a new string or overwrite your old string to achieve the desired affect:
id = id.replace(".xml", "");
git ignore vim temporary files
Vim temporary files end with ~ so you can add to the file .gitignore the line
*~
Vim also creates swap files that have the swp and swo extensions. to remove those use the lines:
*.swp
*.swo
This will ignore all the vim temporary files in a single project
If you want to do it globally, you can create a .gitignore file in your home (you can give it other name or location), and use the following command:
git config --global core.excludesfile ~/.gitignore
Then you just need to add the files you want to ignore to that file
Suppress InsecureRequestWarning: Unverified HTTPS request is being made in Python2.6
For impatient, a quick way to disable python unverified HTTPS warning:
export PYTHONWARNINGS="ignore:Unverified HTTPS request"
How to add smooth scrolling to Bootstrap's scroll spy function
with this code, the id will not appear on the link
document.querySelectorAll('a[href^="#"]').forEach(anchor => {
anchor.addEventListener('click', function (e) {
e.preventDefault();
document.querySelector(this.getAttribute('href')).scrollIntoView({
behavior: 'smooth'
});
});
});
How to Free Inode Usage?
My situation was that I was out of inodes and I had already deleted about everything I could.
$ df -i
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/sda1 942080 507361 11 100% /
I am on an ubuntu 12.04LTS and could not remove the old linux kernels which took up about 400,000 inodes because apt was broken because of a missing package. And I couldn't install the new package because I was out of inodes so I was stuck.
I ended up deleting a few old linux kernels by hand to free up about 10,000 inodes
$ sudo rm -rf /usr/src/linux-headers-3.2.0-2*
This was enough to then let me install the missing package and fix my apt
$ sudo apt-get install linux-headers-3.2.0-76-generic-pae
and then remove the rest of the old linux kernels with apt
$ sudo apt-get autoremove
things are much better now
$ df -i
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/sda1 942080 507361 434719 54% /
Maven- No plugin found for prefix 'spring-boot' in the current project and in the plugin groups
If you are running the
mvn spring-boot:run
from the command line, make sure you are in the directory that contains the pom.xml file. Otherwise, you will run into the No plugin found for prefix 'spring-boot' in the current project and in the plugin groups error.
Get specific line from text file using just shell script
The standard way to do this sort of thing is to use external tools. Disallowing the use of external tools while writing a shell script is absurd. However, if you really don't want to use external tools, you can print line 5 with:
i=0; while read line; do test $((++i)) = 5 && echo "$line"; done < input-file
Note that this will print logical line 5. That is, if input-file contains line continuations, they will be counted as a single line. You can change this behavior by adding -r to the read command. (Which is probably the desired behavior.)
Create an array of strings
one of the simplest ways to create a string matrix is as follow :
x = [ {'first string'} {'Second parameter} {'Third text'} {'Fourth component'} ]
How to get root view controller?
Unless you have a good reason, in your root controller do this:
[[NSNotificationCenter defaultCenter] addObserver:self
selector:@selector(onTheEvent:)
name:@"ABCMyEvent"
object:nil];
And when you want to notify it:
[[NSNotificationCenter defaultCenter] postNotificationName:@"ABCMyEvent"
object:self];
How to reset radiobuttons in jQuery so that none is checked
I know this is old and that this is a little off topic, but supposing you wanted to uncheck only specific radio buttons in a collection:
$("#go").click(function(){_x000D_
$("input[name='correctAnswer']").each(function(){_x000D_
if($(this).val() !== "1"){_x000D_
$(this).prop("checked",false);_x000D_
}_x000D_
});_x000D_
});<script src="https://ajax.googleapis.com/ajax/libs/jquery/1.11.1/jquery.min.js"></script>_x000D_
<input id="radio1" type="radio" name="correctAnswer" value="1">1</input>_x000D_
<input id="radio2" type="radio" name="correctAnswer" value="2">2</input>_x000D_
<input id="radio3" type="radio" name="correctAnswer" value="3">3</input>_x000D_
<input id="radio4" type="radio" name="correctAnswer" value="4">4</input>_x000D_
<input type="button" id="go" value="go">And if you are dealing with a radiobutton list, you can use the :checked selector to get just the one you want.
$("#go").click(function(){
$("input[name='correctAnswer']:checked").prop("checked",false);
});
<script src="https://ajax.googleapis.com/ajax/libs/jquery/1.11.1/jquery.min.js"></script>
<input id="radio1" type="radio" name="correctAnswer" value="1">1</input>
<input id="radio2" type="radio" name="correctAnswer" value="2">2</input>
<input id="radio3" type="radio" name="correctAnswer" value="3">3</input>
<input id="radio4" type="radio" name="correctAnswer" value="4">4</input>
<input type="button" id="go" value="go">
Portable way to get file size (in bytes) in shell?
There is a trick in Solaris I have used, if you ask for the size of more than one file it returns just the total size with no names - so include an empty file like /dev/null as the second file:
eg command fileyouwant /dev/null
I can't rememebr which size command this works for ls/wc/etc - unfortunately I don't have a solaris box to test it.
hasOwnProperty in JavaScript
hasOwnProperty expects the property name as a string, so it would be shape1.hasOwnProperty("name")
Conditional Formatting (IF not empty)
Does this work for you:
You find this dialog on the Home ribbon, under the Styles group, the Conditional Formatting menu, New rule....
Change the row color in DataGridView based on the quantity of a cell value
This might be helpful
- Use the "RowPostPaint" event
- The name of the column is NOT the "Header" of the column. You have to go to the properties for the DataGridView => then select the column => then look for the "Name" property
I converted this from C# ('From: http://www.dotnetpools.com/Article/ArticleDetiail/?articleId=74)
Private Sub dgv_EmployeeTraining_RowPostPaint(sender As Object, e As System.Windows.Forms.DataGridViewRowPostPaintEventArgs)
Handles dgv_EmployeeTraining.RowPostPaint
If e.RowIndex < Me.dgv_EmployeeTraining.RowCount - 1 Then
Dim dgvRow As DataGridViewRow = Me.dgv_EmployeeTraining.Rows(e.RowIndex)
'<== This is the header Name
'If CInt(dgvRow.Cells("EmployeeStatus_Training_e26").Value) <> 2 Then
'<== But this is the name assigned to it in the properties of the control
If CInt(dgvRow.Cells("DataGridViewTextBoxColumn15").Value.ToString) <> 2 Then
dgvRow.DefaultCellStyle.BackColor = Color.FromArgb(236, 236, 255)
Else
dgvRow.DefaultCellStyle.BackColor = Color.LightPink
End If
End If
End Sub
MySQL pivot table query with dynamic columns
Here's stored procedure, which will generate the table based on data from one table and column and data from other table and column.
The function 'sum(if(col = value, 1,0)) as value ' is used. You can choose from different functions like MAX(if()) etc.
delimiter //
create procedure myPivot(
in tableA varchar(255),
in columnA varchar(255),
in tableB varchar(255),
in columnB varchar(255)
)
begin
set @sql = NULL;
set @sql = CONCAT('select group_concat(distinct concat(
\'SUM(IF(',
columnA,
' = \'\'\',',
columnA,
',\'\'\', 1, 0)) AS \'\'\',',
columnA,
',\'\'\'\') separator \', \') from ',
tableA, ' into @sql');
-- select @sql;
PREPARE stmt FROM @sql;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
-- select @sql;
SET @sql = CONCAT('SELECT p.',
columnB,
', ',
@sql,
' FROM ', tableB, ' p GROUP BY p.',
columnB,'');
-- select @sql;
/* */
PREPARE stmt FROM @sql;
EXECUTE stmt;
/* */
DEALLOCATE PREPARE stmt;
end//
delimiter ;
Python URLLib / URLLib2 POST
u = urllib2.urlopen('http://myserver/inout-tracker', data)
h.request('POST', '/inout-tracker/index.php', data, headers)
Using the path /inout-tracker without a trailing / doesn't fetch index.php. Instead the server will issue a 302 redirect to the version with the trailing /.
Doing a 302 will typically cause clients to convert a POST to a GET request.
"Expected an indented block" error?
I also experienced that for example:
This code doesnt work and get the intended block error.
class Foo(models.Model):
title = models.CharField(max_length=200)
body = models.TextField()
pub_date = models.DateTimeField('date published')
likes = models.IntegerField()
def __unicode__(self):
return self.title
However, when i press tab before typing return self.title statement, the code works.
class Foo(models.Model):
title = models.CharField(max_length=200)
body = models.TextField()
pub_date = models.DateTimeField('date published')
likes = models.IntegerField()
def __unicode__(self):
return self.title
Hope, this will help others.
Concatenate a vector of strings/character
Here is a little utility function that collapses a named or unnamed list of values to a single string for easier printing. It will also print the code line itself. It's from my list examples in R page.
Generate some lists named or unnamed:
# Define Lists
ls_num <- list(1,2,3)
ls_str <- list('1','2','3')
ls_num_str <- list(1,2,'3')
# Named Lists
ar_st_names <- c('e1','e2','e3')
ls_num_str_named <- ls_num_str
names(ls_num_str_named) <- ar_st_names
# Add Element to Named List
ls_num_str_named$e4 <- 'this is added'
Here is the a function that will convert named or unnamed list to string:
ffi_lst2str <- function(ls_list, st_desc, bl_print=TRUE) {
# string desc
if(missing(st_desc)){
st_desc <- deparse(substitute(ls_list))
}
# create string
st_string_from_list = paste0(paste0(st_desc, ':'),
paste(names(ls_list), ls_list, sep="=", collapse=";" ))
if (bl_print){
print(st_string_from_list)
}
}
Testing the function with the lists created prior:
> ffi_lst2str(ls_num)
[1] "ls_num:=1;=2;=3"
> ffi_lst2str(ls_str)
[1] "ls_str:=1;=2;=3"
> ffi_lst2str(ls_num_str)
[1] "ls_num_str:=1;=2;=3"
> ffi_lst2str(ls_num_str_named)
[1] "ls_num_str_named:e1=1;e2=2;e3=3;e4=this is added"
Testing the function with subset of list elements:
> ffi_lst2str(ls_num_str_named[c('e2','e3','e4')])
[1] "ls_num_str_named[c(\"e2\", \"e3\", \"e4\")]:e2=2;e3=3;e4=this is added"
> ffi_lst2str(ls_num[2:3])
[1] "ls_num[2:3]:=2;=3"
> ffi_lst2str(ls_str[2:3])
[1] "ls_str[2:3]:=2;=3"
> ffi_lst2str(ls_num_str[2:4])
[1] "ls_num_str[2:4]:=2;=3;=NULL"
> ffi_lst2str(ls_num_str_named[c('e2','e3','e4')])
[1] "ls_num_str_named[c(\"e2\", \"e3\", \"e4\")]:e2=2;e3=3;e4=this is added"
How to round up the result of integer division?
A generic method, whose result you can iterate over may be of interest:
public static Object[][] chunk(Object[] src, int chunkSize) {
int overflow = src.length%chunkSize;
int numChunks = (src.length/chunkSize) + (overflow>0?1:0);
Object[][] dest = new Object[numChunks][];
for (int i=0; i<numChunks; i++) {
dest[i] = new Object[ (i<numChunks-1 || overflow==0) ? chunkSize : overflow ];
System.arraycopy(src, i*chunkSize, dest[i], 0, dest[i].length);
}
return dest;
}
How to retrieve checkboxes values in jQuery
Try this one..
var listCheck = [];
console.log($("input[name='YourCheckBokName[]']"));
$("input[name='YourCheckBokName[]']:checked").each(function() {
console.log($(this).val());
listCheck .push($(this).val());
});
console.log(listCheck);
What is a user agent stylesheet?
I had the same problem as one of my <div>'s had the margin set by the browser. It was quite annoying but then I figured out as most of the people said, it's a markup error.
I went back and checked my <head> section and my CSS link was like below:
<link rel="stylesheet" href="ex.css">
I included type in it and made it like below:
<link rel="stylesheet" type="text/css" href="ex.css">
My problem was solved.
REST API error code 500 handling
You suggested "Catching any unexpected errors and return some error code signaling "unexpected situation" " but couldn't find an appropriate error code.
Guess what: That's what 5xx is there for.
How do I escape ampersands in batch files?
If you have spaces in the name of the file and you have a character you need to escape:
You can use single AND double quotes to avoid any misnomers in the command.
scp ./'files name with spaces/internal folder with spaces/"text & files stored.txt"' .
The ^ character escapes the quotes otherwise.
how to change the dist-folder path in angular-cli after 'ng build'
For Angular 6+ things have changed a little.
Define where ng build generates app files
Cli setup is now done in angular.json (replaced .angular-cli.json) in your workspace root directory. The output path in default angular.json should look like this (irrelevant lines removed):
{
"projects": {
"my-app-name": {
"architect": {
"options": {
"outputPath": "dist/my-app-name",
Obviously, this will generate your app in WORKSPACE/dist/my-app-name. Modify outputPath if you prefer another directory.
You can overwrite the output path using command line arguments (e.g. for CI jobs):
ng build -op dist/example
ng build --output-path=dist/example
S.a. https://github.com/angular/angular-cli/wiki/build
Hosting angular app in subdirectory
Setting the output path, will tell angular where to place the "compiled" files but however you change the output path, when running the app, angular will still assume that the app is hosted in the webserver's document root.
To make it work in a sub directory, you'll have to set the base href.
In angular.json:
{
"projects": {
"my-app-name": {
"architect": {
"options": {
"baseHref": "/my-folder/",
Cli:
ng build --base-href=/my-folder/
If you don't know where the app will be hosted on build time, you can change base tag in generated index.html.
Here's an example how we do it in our docker container:
entrypoint.sh
if [ -n "${BASE_PATH}" ]
then
files=( $(find . -name "index.html") )
cp -n "${files[0]}" "${files[0]}.org"
cp "${files[0]}.org" "${files[0]}"
sed -i "s*<base href=\"/\">*<base href=\"${BASE_PATH}\">*g" "${files[0]}"
fi
How to install pip for Python 3.6 on Ubuntu 16.10?
This website contains a much cleaner solution, it leaves pip intact as-well and one can easily switch between 3.5 and 3.6 and then whenever 3.7 is released.
http://ubuntuhandbook.org/index.php/2017/07/install-python-3-6-1-in-ubuntu-16-04-lts/
A short summary:
sudo apt-get install python python-pip python3 python3-pip
sudo add-apt-repository ppa:jonathonf/python-3.6
sudo apt-get update
sudo apt-get install python3.6
sudo update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.5 1
sudo update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.6 2
Then
$ pip -V
pip 8.1.1 from /usr/lib/python2.7/dist-packages (python 2.7)
$ pip3 -V
pip 8.1.1 from /usr/local/lib/python3.5/dist-packages (python 3.5)
Then to select python 3.6 run
sudo update-alternatives --config python3
and select '2'. Then
$ pip3 -V
pip 8.1.1 from /usr/local/lib/python3.6/dist-packages (python 3.6)
To update pip select the desired version and
pip3 install --upgrade pip
$ pip3 -V
pip 9.0.1 from /usr/local/lib/python3.6/dist-packages (python 3.6)
Tested on Ubuntu 16.04.
What's the regular expression that matches a square bracket?
How about using backslash \ in front of the square bracket. Normally square brackets match a character class.
How to create a file in a directory in java?
Use:
File f = new File("C:\\a\\b\\test.txt");
f.mkdirs();
f.createNewFile();
Notice I changed the forward slashes to double back slashes for paths in Windows File System. This will create an empty file on the given path.
How can I format decimal property to currency?
You can create an extension method. I find this to be a good practice as you may need to lock down a currency display regardless of the browser setting. For instance you may want to display $5,000.00 always instead of 5 000,00 $ (#CanadaProblems)
public static class DecimalExtensions
{
public static string ToCurrency(this decimal decimalValue)
{
return $"{decimalValue:C}";
}
}
Can linux cat command be used for writing text to file?
simply pipeline echo with cat
For example
echo write something to file.txt | cat > file.txt
What are native methods in Java and where should they be used?
The method is implemented in "native" code. That is, code that does not run in the JVM. It's typically written in C or C++.
Native methods are usually used to interface with system calls or libraries written in other programming languages.
what's the default value of char?
The default value of a char primitive type is '\u0000'(null character) as stated in the Java Language Specification.
The shortcut for 'u0000' is '\0', So the null can be represented either by 'u0000' or '\0'.
The below Java program validates null representations using instance char field 'c'.
public class DefaultValueForchar {
char c;
public static void main(String[] args) {
char c0 = '\0';
char cu0000 = '\u0000';
DefaultValueForchar obj = new DefaultValueForchar();
System.out.println(obj.c);
System.out.println(c0);
System.out.println(cu0000);
System.out.println(c0==cu0000);
System.out.println(obj.c==c0);
System.out.println(obj.c==cu0000);
}
}
IntelliJ: Never use wildcard imports
It's obvious why you'd want to disable this: To force IntelliJ to include each and every import individually. It makes it easier for people to figure out exactly where classes you're using come from.
Click on the Settings "wrench" icon on the toolbar, open "Imports" under "Code Style", and check the "Use single class import" selection. You can also completely remove entries under "Packages to use import with *", or specify a threshold value that only uses the "*" when the individual classes from a package exceeds that threshold.
Update: in IDEA 13 "Use single class import" does not prevent wildcard imports. The solution is to go to Preferences (? + , on macOS / Ctrl + Alt + S on Windows and Linux) > Editor > Code Style > Java > Imports tab set Class count to use import with '*' and Names count to use static import with '*' to a higher value. Any value over 99 seems to work fine.
jQuery: print_r() display equivalent?
console.log is what I most often use when debugging.
I was able to find this jQuery extension though.
How do I get the coordinate position after using jQuery drag and drop?
This worked for me:
$("#element1").droppable(
{
drop: function(event, ui)
{
var currentPos = ui.helper.position();
alert("left="+parseInt(currentPos.left)+" top="+parseInt(currentPos.top));
}
});
How to connect HTML Divs with Lines?
Definitely possible with any number of libraries and/or HTML5 technologies. You could possible hack something together in pure CSS by using something like the border-bottom property, but it would probably be horribly hacky.
If you're serious about this, you should take a look at a JS library for canvas drawing or SVG. For example, something like http://www.graphjs.org/ or http://jsdraw2dx.jsfiction.com/
Laravel form html with PUT method for PUT routes
If you are using HTML Form element instead Laravel Form Builder, you must place method_field between your
form opening tag and closing end. By doing this you may explicitly define form method type.
<form>
{{ method_field('PUT') }}
</form>
How to stop text from taking up more than 1 line?
Sometimes using instead of spaces will work. Clearly it has drawbacks, though.
Send FormData with other field in AngularJS
Using $resource in AngularJS you can do:
task.service.js
$ngTask.factory("$taskService", [
"$resource",
function ($resource) {
var taskModelUrl = 'api/task/';
return {
rest: {
taskUpload: $resource(taskModelUrl, {
id: '@id'
}, {
save: {
method: "POST",
isArray: false,
headers: {"Content-Type": undefined},
transformRequest: angular.identity
}
})
}
};
}
]);
And then use it in a module:
task.module.js
$ngModelTask.controller("taskController", [
"$scope",
"$taskService",
function (
$scope,
$taskService,
) {
$scope.saveTask = function (name, file) {
var newTask,
payload = new FormData();
payload.append("name", name);
payload.append("file", file);
newTask = $taskService.rest.taskUpload.save(payload);
// check if exists
}
}
Android new Bottom Navigation bar or BottomNavigationView
As Sanf0rd mentioned, Google launched the BottomNavigationView as part of the Design Support Library version 25.0.0. The limitations he mentioned are mostly true, except that you CAN change the background color of the view and even the text color and icon tint color. It also has an animation when you add more than 4 items (sadly it cannot be enabled or disabled manually).
I wrote a detailed tutorial about it with examples and an accompanying repository, which you can read here: https://blog.autsoft.hu/now-you-can-use-the-bottom-navigation-view-in-the-design-support-library/
The gist of it
You have to add these in your app level build.gradle:
compile 'com.android.support:appcompat-v7:25.0.0'
compile 'com.android.support:design:25.0.0'
You can include it in your layout like this:
<android.support.design.widget.BottomNavigationView
xmlns:app="http://schemas.android.com/apk/res-auto"
android:id="@+id/bottom_navigation_view"
android:layout_width="match_parent"
android:layout_height="wrap_content"
app:itemBackground="@color/darkGrey"
app:itemIconTint="@color/bottom_navigation_item_background_colors"
app:itemTextColor="@color/bottom_navigation_item_background_colors"
app:menu="@menu/menu_bottom_navigation" />
You can specify the items via a menu resource like this:
<?xml version="1.0" encoding="utf-8"?>
<menu
xmlns:android="http://schemas.android.com/apk/res/android">
<item
android:id="@+id/action_one"
android:icon="@android:drawable/ic_dialog_map"
android:title="One"/>
<item
android:id="@+id/action_two"
android:icon="@android:drawable/ic_dialog_info"
android:title="Two"/>
<item
android:id="@+id/action_three"
android:icon="@android:drawable/ic_dialog_email"
android:title="Three"/>
<item
android:id="@+id/action_four"
android:icon="@android:drawable/ic_popup_reminder"
android:title="Four"/>
</menu>
And you can set the tint and text color as a color list, so the currently selected item is highlighted:
<?xml version="1.0" encoding="utf-8"?>
<selector xmlns:android="http://schemas.android.com/apk/res/android">
<item
android:color="@color/colorAccent"
android:state_checked="false"/>
<item
android:color="@android:color/white"
android:state_checked="true"/>
</selector>
Finally, you can handle the selection of the items with an OnNavigationItemSelectedListener:
bottomNavigationView.setOnNavigationItemSelectedListener(new BottomNavigationView.OnNavigationItemSelectedListener() {
@Override
public boolean onNavigationItemSelected(@NonNull MenuItem item) {
Fragment fragment = null;
switch (item.getItemId()) {
case R.id.action_one:
// Switch to page one
break;
case R.id.action_two:
// Switch to page two
break;
case R.id.action_three:
// Switch to page three
break;
}
return true;
}
});
In Bash, how can I check if a string begins with some value?
Adding a tiny bit more syntax detail to Mark Rushakoff's highest rank answer.
The expression
$HOST == node*
Can also be written as
$HOST == "node"*
The effect is the same. Just make sure the wildcard is outside the quoted text. If the wildcard is inside the quotes it will be interpreted literally (i.e. not as a wildcard).
How to decompile an APK or DEX file on Android platform?
Also you can use Android Multitool. You can make minor changes in the app like hiding GUI elements or modifying small part of Logic and rebuild the apk. Its easy to use and decompile/recompile apk and jar files. Here is the Link you can checkout.
Cheers
How can I pass parameters to a partial view in mvc 4
Your question is hard to understand, but if I'm getting the gist, you simply have some value in your main view that you want to access in a partial being rendered in that view.
If you just render a partial with just the partial name:
@Html.Partial("_SomePartial")
It will actually pass your model as an implicit parameter, the same as if you were to call:
@Html.Partial("_SomePartial", Model)
Now, in order for your partial to actually be able to use this, though, it too needs to have a defined model, for example:
@model Namespace.To.Your.Model
@Html.Action("MemberProfile", "Member", new { id = Model.Id })
Alternatively, if you're dealing with a value that's not on your view's model (it's in the ViewBag or a value generated in the view itself somehow, then you can pass a ViewDataDictionary
@Html.Partial("_SomePartial", new ViewDataDictionary { { "id", someInteger } });
And then:
@Html.Action("MemberProfile", "Member", new { id = ViewData["id"] })
As with the model, Razor will implicitly pass your partial the view's ViewData by default, so if you had ViewBag.Id in your view, then you can reference the same thing in your partial.
jQuery load more data on scroll
The accepted answer of this question has some issue with chrome when the window is zoomed in to a value >100%. Here is the code recommended by chrome developers as part of a bug i had raised on the same.
$(window).scroll(function() {
if($(window).scrollTop() + $(window).height() >= $(document).height()){
//Your code here
}
});
For reference:
Eclipse CDT: Symbol 'cout' could not be resolved
If all else fails, like it did in my case, then just disable annotations. I started a c++11 project with own makefile but couldn't fix all the problems. Even if you disable annotations, eclipse will still be able to help you do some autocompletion. Most importantly, the debugger still works!
Font Awesome & Unicode
For those who may stumble across this post, you need to set
font-family: FontAwesome;
as a property in your CSS selector and then unicode will work fine in CSS
What's the fastest way of checking if a point is inside a polygon in python
Your test is good, but it measures only some specific situation: we have one polygon with many vertices, and long array of points to check them within polygon.
Moreover, I suppose that you're measuring not matplotlib-inside-polygon-method vs ray-method, but matplotlib-somehow-optimized-iteration vs simple-list-iteration
Let's make N independent comparisons (N pairs of point and polygon)?
# ... your code...
lenpoly = 100
polygon = [[np.sin(x)+0.5,np.cos(x)+0.5] for x in np.linspace(0,2*np.pi,lenpoly)[:-1]]
M = 10000
start_time = time()
# Ray tracing
for i in range(M):
x,y = np.random.random(), np.random.random()
inside1 = ray_tracing_method(x,y, polygon)
print "Ray Tracing Elapsed time: " + str(time()-start_time)
# Matplotlib mplPath
start_time = time()
for i in range(M):
x,y = np.random.random(), np.random.random()
inside2 = path.contains_points([[x,y]])
print "Matplotlib contains_points Elapsed time: " + str(time()-start_time)
Result:
Ray Tracing Elapsed time: 0.548588991165
Matplotlib contains_points Elapsed time: 0.103765010834
Matplotlib is still much better, but not 100 times better. Now let's try much simpler polygon...
lenpoly = 5
# ... same code
result:
Ray Tracing Elapsed time: 0.0727779865265
Matplotlib contains_points Elapsed time: 0.105288982391
Python recursive folder read
The pathlib library is really great for working with files. You can do a recursive glob on a Path object like so.
from pathlib import Path
for elem in Path('/path/to/my/files').rglob('*.*'):
print(elem)
What is a 'Closure'?
Closure is very easy. We can consider it as follows : Closure = function + its lexical environment
Consider the following function:
function init() {
var name = “Mozilla”;
}
What will be the closure in the above case ? Function init() and variables in its lexical environment ie name. Closure = init() + name
Consider another function :
function init() {
var name = “Mozilla”;
function displayName(){
alert(name);
}
displayName();
}
What will be the closures here ? Inner function can access variables of outer function. displayName() can access the variable name declared in the parent function, init(). However, the same local variables in displayName() will be used if they exists.
Closure 1 : init function + ( name variable + displayName() function) --> lexical scope
Closure 2 : displayName function + ( name variable ) --> lexical scope
How do I display local image in markdown?
To my knowledge, for VSCode on Linux, the local image can be normally displayed only when you put the image into the same folder as your .md post file.
i.e. only  or  will work.
Even the absolute path like also doesn't work.
Convert absolute path into relative path given a current directory using Bash
Here is my version. It's based on the answer by @Offirmo. I made it Dash-compatible and fixed the following testcase failure:
./compute-relative.sh "/a/b/c/de/f/g" "/a/b/c/def/g/" --> "../..f/g/"
Now:
CT_FindRelativePath "/a/b/c/de/f/g" "/a/b/c/def/g/" --> "../../../def/g/"
See the code:
# both $1 and $2 are absolute paths beginning with /
# returns relative path to $2/$target from $1/$source
CT_FindRelativePath()
{
local insource=$1
local intarget=$2
# Ensure both source and target end with /
# This simplifies the inner loop.
#echo "insource : \"$insource\""
#echo "intarget : \"$intarget\""
case "$insource" in
*/) ;;
*) source="$insource"/ ;;
esac
case "$intarget" in
*/) ;;
*) target="$intarget"/ ;;
esac
#echo "source : \"$source\""
#echo "target : \"$target\""
local common_part=$source # for now
local result=""
#echo "common_part is now : \"$common_part\""
#echo "result is now : \"$result\""
#echo "target#common_part : \"${target#$common_part}\""
while [ "${target#$common_part}" = "${target}" -a "${common_part}" != "//" ]; do
# no match, means that candidate common part is not correct
# go up one level (reduce common part)
common_part=$(dirname "$common_part")/
# and record that we went back
if [ -z "${result}" ]; then
result="../"
else
result="../$result"
fi
#echo "(w) common_part is now : \"$common_part\""
#echo "(w) result is now : \"$result\""
#echo "(w) target#common_part : \"${target#$common_part}\""
done
#echo "(f) common_part is : \"$common_part\""
if [ "${common_part}" = "//" ]; then
# special case for root (no common path)
common_part="/"
fi
# since we now have identified the common part,
# compute the non-common part
forward_part="${target#$common_part}"
#echo "forward_part = \"$forward_part\""
if [ -n "${result}" -a -n "${forward_part}" ]; then
#echo "(simple concat)"
result="$result$forward_part"
elif [ -n "${forward_part}" ]; then
result="$forward_part"
fi
#echo "result = \"$result\""
# if a / was added to target and result ends in / then remove it now.
if [ "$intarget" != "$target" ]; then
case "$result" in
*/) result=$(echo "$result" | awk '{ string=substr($0, 1, length($0)-1); print string; }' ) ;;
esac
fi
echo $result
return 0
}
How do I restart a program based on user input?
You can do this simply with a function. For example:
def script():
# program code here...
restart = raw_input("Would you like to restart this program?")
if restart == "yes" or restart == "y":
script()
if restart == "n" or restart == "no":
print "Script terminating. Goodbye."
script()
Of course you can change a lot of things here. What is said, what the script will accept as a valid input, the variable and function names. You can simply nest the entire program in a user-defined function (Of course you must give everything inside an extra indent) and have it restart at anytime using this line of code: myfunctionname(). More on this here.
How do I display image in Alert/confirm box in Javascript?
Short answer: You can't.
Long answer: You could use a modal to display a popup with the image you need.
You can refer to this as an example to a modal.
Easy way to add drop down menu with 1 - 100 without doing 100 different options?
Not with plain HTML I'm afraid.
You could use some jQuery to do this though:
$(function(){
var $select = $(".1-100");
for (i=1;i<=100;i++){
$select.append($('<option></option>').val(i).html(i))
}
});?
You can download jQuery here
Changing user agent on urllib2.urlopen
I answered a similar question a couple weeks ago.
There is example code in that question, but basically you can do something like this: (Note the capitalization of User-Agent as of RFC 2616, section 14.43.)
opener = urllib2.build_opener()
opener.addheaders = [('User-Agent', 'Mozilla/5.0')]
response = opener.open('http://www.stackoverflow.com')
Multiple axis line chart in excel
Best and Free ( maybe only) solution for this is google sheets. i don't know whether it plots as u expected or not but certainly you can draw multiple axes.
Regards
keerthan
One line if in VB .NET
If (condition, condition_is_true, condition_is_false)
It will look like this in longer version:
If (condition_is_true) Then
Else (condition_is_false)
End If
Gets last digit of a number
You have just created an empty integer array. The array guess does not contain anything to my knowledge. The rest you should work out to get better.
What is the difference between Linear search and Binary search?
Linear Search looks through items until it finds the searched value.
Efficiency: O(n)
Example Python Code:
test_list = [1, 3, 9, 11, 15, 19, 29]
test_val1 = 25
test_val2 = 15
def linear_search(input_array, search_value):
index = 0
while (index < len(input_array)) and (input_array[index] < search_value):
index += 1
if index >= len(input_array) or input_array[index] != search_value:
return -1
return index
print linear_search(test_list, test_val1)
print linear_search(test_list, test_val2)
Binary Search finds the middle element of the array. Checks that middle value is greater or lower than the search value. If it is smaller, it gets the left side of the array and finds the middle element of that part. If it is greater, gets the right part of the array. It loops the operation until it finds the searched value. Or if there is no value in the array finishes the search.
Efficiency: O(logn)
Example Python Code:
test_list = [1, 3, 9, 11, 15, 19, 29]
test_val1 = 25
test_val2 = 15
def binary_search(input_array, value):
low = 0
high = len(input_array) - 1
while low <= high:
mid = (low + high) / 2
if input_array[mid] == value:
return mid
elif input_array[mid] < value:
low = mid + 1
else:
high = mid - 1
return -1
print binary_search(test_list, test_val1)
print binary_search(test_list, test_val2)
Also you can see visualized information about Linear and Binary Search here: https://www.cs.usfca.edu/~galles/visualization/Search.html
Making Maven run all tests, even when some fail
Try to add the following configuration for surefire plugin in your pom.xml of root project:
<project>
[...]
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<configuration>
<testFailureIgnore>true</testFailureIgnore>
</configuration>
</plugin>
</plugins>
</build>
[...]
</project>
About catching ANY exception
To catch all possible exceptions, catch BaseException. It's on top of the Exception hierarchy:
Python 3: https://docs.python.org/3.9/library/exceptions.html#exception-hierarchy
Python 2.7: https://docs.python.org/2.7/library/exceptions.html#exception-hierarchy
try:
something()
except BaseException as error:
print('An exception occurred: {}'.format(error))
But as other people mentioned, you would usually not need this, only for specific cases.
How to scroll UITableView to specific position
Use [tableView scrollToRowAtIndexPath:indexPath atScrollPosition:scrollPosition animated:YES];
Scrolls the receiver until a row identified by index path is at a particular location on the screen.
And
scrollToNearestSelectedRowAtScrollPosition:animated:
Scrolls the table view so that the selected row nearest to a specified position in the table view is at that position.
How to prevent "The play() request was interrupted by a call to pause()" error?
This solution helped me:
n.cloneNode(true).play();
How can I check out a GitHub pull request with git?
Suppose your origin and upstream info is like below
$ git remote -v
origin [email protected]:<yourname>/<repo_name>.git (fetch)
origin [email protected]:<yourname>/<repo_name>.git (push)
upstream [email protected]:<repo_owner>/<repo_name>.git (fetch)
upstream [email protected]:<repo_owner>/<repo_name>.git (push)
and your branch name is like
<repo_owner>:<BranchName>
then
git pull origin <BranchName>
shall do the job
How do I convert a String to a BigInteger?
According to the documentation:
BigInteger(String val)
Translates the decimal String representation of a BigInteger into a BigInteger.
It means that you can use a String to initialize a BigInteger object, as shown in the following snippet:
sum = sum.add(new BigInteger(newNumber));
How to get current time in python and break up into year, month, day, hour, minute?
This is an older question, but I came up with a solution I thought others might like.
def get_current_datetime_as_dict():
n = datetime.now()
t = n.timetuple()
field_names = ["year",
"month",
"day",
"hour",
"min",
"sec",
"weekday",
"md",
"yd"]
return dict(zip(field_names, t))
timetuple() can be zipped with another array, which creates labeled tuples. Cast that to a dictionary and the resultant product can be consumed with get_current_datetime_as_dict()['year'].
This has a little more overhead than some of the other solutions on here, but I've found it's so nice to be able to access named values for clartiy's sake in the code.
Show spinner GIF during an $http request in AngularJS?
create directive with this code:
$scope.$watch($http.pendingRequests, toggleLoader);
function toggleLoader(status){
if(status.length){
element.addClass('active');
} else {
element.removeClass('active');
}
}
How to remove symbols from a string with Python?
Sometimes it takes longer to figure out the regex than to just write it out in python:
import string
s = "how much for the maple syrup? $20.99? That's ricidulous!!!"
for char in string.punctuation:
s = s.replace(char, ' ')
If you need other characters you can change it to use a white-list or extend your black-list.
Sample white-list:
whitelist = string.letters + string.digits + ' '
new_s = ''
for char in s:
if char in whitelist:
new_s += char
else:
new_s += ' '
Sample white-list using a generator-expression:
whitelist = string.letters + string.digits + ' '
new_s = ''.join(c for c in s if c in whitelist)
Convert String value format of YYYYMMDDHHMMSS to C# DateTime
Define your own parse format string to use.
string formatString = "yyyyMMddHHmmss";
string sample = "20100611221912";
DateTime dt = DateTime.ParseExact(sample,formatString,null);
In case you got a datetime having milliseconds, use the following formatString
string format = "yyyyMMddHHmmssfff"
string dateTime = "20140123205803252";
DateTime.ParseExact(dateTime ,format,CultureInfo.InvariantCulture);
Thanks
javascript create empty array of a given size
1) To create new array which, you cannot iterate over, you can use array constructor:
Array(100) or new Array(100)
2) You can create new array, which can be iterated over like below:
a) All JavaScript versions
- Array.apply:
Array.apply(null, Array(100))
b) From ES6 JavaScript version
- Destructuring operator:
[...Array(100)] - Array.prototype.fill
Array(100).fill(undefined) - Array.from
Array.from({ length: 100 })
You can map over these arrays like below.
Array(4).fill(null).map((u, i) => i)[0, 1, 2, 3][...Array(4)].map((u, i) => i)[0, 1, 2, 3]Array.apply(null, Array(4)).map((u, i) => i)[0, 1, 2, 3]Array.from({ length: 4 }).map((u, i) => i)[0, 1, 2, 3]
Convert JSON string to array of JSON objects in Javascript
Using jQuery:
var str = '{"id":1,"name":"Test1"},{"id":2,"name":"Test2"}';
var jsonObj = $.parseJSON('[' + str + ']');
jsonObj is your JSON object.
Android background music service
Create a foreground service with the START_STICKY flag.
@Override
public int onStartCommand(Intent startIntent, int flags, int startId) {
if (startIntent != null) {
String action = startIntent.getAction();
String command = startIntent.getStringExtra(CMD_NAME);
if (ACTION_CMD.equals(action)) {
if (CMD_PAUSE.equals(command)) {
if (mPlayback != null && mPlayback.isPlaying()) {
handlePauseRequest();
}
} else if (CMD_PLAY.equals(command)) {
ArrayList<Track> queue = new ArrayList<>();
for (Parcelable input : startIntent.getParcelableArrayListExtra(ARG_QUEUE)) {
queue.add((Track) Parcels.unwrap(input));
}
int index = startIntent.getIntExtra(ARG_INDEX, 0);
playWithQueue(queue, index);
}
}
}
return START_STICKY;
}
This can then be called from any activity to play some music
Intent intent = new Intent(MusicService.ACTION_CMD, fileUrlToPlay, activity, MusicService::class.java)
intent.putParcelableArrayListExtra(MusicService.ARG_QUEUE, tracks)
intent.putExtra(MusicService.ARG_INDEX, position)
intent.putExtra(MusicService.CMD_NAME, MusicService.CMD_PLAY)
activity.startService(intent)
You can bind to the service using bindService and to make the Service pause/stop from the corresponding activity lifecycle methods.
Here's a good tutorial about Playing music in the background on Android
Putting GridView data in a DataTable
Copying Grid to datatable
if (GridView.Rows.Count != 0)
{
//Forloop for header
for (int i = 0; i < GridView.HeaderRow.Cells.Count; i++)
{
dt.Columns.Add(GridView.HeaderRow.Cells[i].Text);
}
//foreach for datarow
foreach (GridViewRow row in GridView.Rows)
{
DataRow dr = dt.NewRow();
for (int j = 0; j < row.Cells.Count; j++)
{
dr[GridView.HeaderRow.Cells[j].Text] = row.Cells[j].Text;
}
dt.Rows.Add(dr);
}
//Loop for footer
if (GridView.FooterRow.Cells.Count != 0)
{
DataRow dr = dt.NewRow();
for (int i = 0; i < GridView.FooterRow.Cells.Count; i++)
{
//You have to re-do the work if you did anything in databound for footer.
}
dt.Rows.Add(dr);
}
dt.TableName = "tb";
}
How to check if any Checkbox is checked in Angular
You can do something like:
function ChckbxsCtrl($scope, $filter) {
$scope.chkbxs = [{
label: "Led Zeppelin",
val: false
}, {
label: "Electric Light Orchestra",
val: false
}, {
label: "Mark Almond",
val: false
}];
$scope.$watch("chkbxs", function(n, o) {
var trues = $filter("filter")(n, {
val: true
});
$scope.flag = trues.length;
}, true);
}
And a template:
<div ng-controller="ChckbxsCtrl">
<div ng-repeat="chk in chkbxs">
<input type="checkbox" ng-model="chk.val" />
<label>{{chk.label}}</label>
</div>
<div ng-show="flag">I'm ON when band choosed</div>
</div>
Working: http://jsfiddle.net/cherniv/JBwmA/
UPDATE: Or you can go little bit different way , without using $scope's $watch() method, like:
$scope.bandChoosed = function() {
var trues = $filter("filter")($scope.chkbxs, {
val: true
});
return trues.length;
}
And in a template do:
<div ng-show="bandChoosed()">I'm ON when band choosed</div>
Fiddle: http://jsfiddle.net/uzs4sgnp/
Plotting time in Python with Matplotlib
7 years later and this code has helped me. However, my times still were not showing up correctly.
Using Matplotlib 2.0.0 and I had to add the following bit of code from Editing the date formatting of x-axis tick labels in matplotlib by Paul H.
import matplotlib.dates as mdates
myFmt = mdates.DateFormatter('%d')
ax.xaxis.set_major_formatter(myFmt)
I changed the format to (%H:%M) and the time displayed correctly.
All thanks to the community.
Insert node at a certain position in a linked list C++
Insert an element at very beginning position. case-1 when the list is empty. case-2 When the list is not empty.
#include<iostream>
using namespace std;
struct Node{
int data;
Node* next; //link == head =stored the address of the next node
};
Node* head; //pointer to Head node with empty list
void Insert(int y);
void print();
int main(){
head = nullptr; //empty list
int n,y;
cout<<"how many number do you want to enter?"<<endl;
cin>>n;
for (int i=0;i<n;i++){
cout<<"Enter the number "<<i+1<<endl;
cin>>y;
Insert(y);
print();
}
}
void Insert(int y){
Node* temp = new Node(); //create dynamic memory allocation
temp->data = y;
temp->next = head; // temp->next = null; when list is empty
head = temp;
}
void print(){
Node* temp = head;
cout<<"List is: "<<endl;
while(temp!= nullptr){
cout<<temp->data<<" ";
temp = temp->next;
}
cout<<endl;
}
PHP - define constant inside a class
This is and old question, but now on PHP 7.1 you can define constant visibility.
EXAMPLE
<?php
class Foo {
// As of PHP 7.1.0
public const BAR = 'bar';
private const BAZ = 'baz';
}
echo Foo::BAR . PHP_EOL;
echo Foo::BAZ . PHP_EOL;
?>
Output of the above example in PHP 7.1:
bar Fatal error: Uncaught Error: Cannot access private const Foo::BAZ in …
Note: As of PHP 7.1.0 visibility modifiers are allowed for class constants.
More info here
Scroll / Jump to id without jQuery
Maybe You should try scrollIntoView.
document.getElementById('id').scrollIntoView();
This will scroll to your Element.
push() a two-dimensional array
Iterating over two dimensions means you'll need to check over two dimensions.
assuming you're starting with:
var myArray = [
[1,1,1,1,1],
[1,1,1,1,1],
[1,1,1,1,1]
]; //don't forget your semi-colons
You want to expand this two-dimensional array to become:
var myArray = [
[1,1,1,1,1,0,0],
[1,1,1,1,1,0,0],
[1,1,1,1,1,0,0],
[0,0,0,0,0,0,0],
[0,0,0,0,0,0,0],
[0,0,0,0,0,0,0],
];
Which means you need to understand what the difference is.
Start with the outer array:
var myArray = [
[...],
[...],
[...]
];
If you want to make this array longer, you need to check that it's the correct length, and add more inner arrays to make up the difference:
var i,
rows,
myArray;
rows = 8;
myArray = [...]; //see first example above
for (i = 0; i < rows; i += 1) {
//check if the index exists in the outer array
if (!(i in myArray)) {
//if it doesn't exist, we need another array to fill
myArray.push([]);
}
}
The next step requires iterating over every column in every array, we'll build on the original code:
var i,
j,
row,
rows,
cols,
myArray;
rows = 8;
cols = 7; //adding columns in this time
myArray = [...]; //see first example above
for (i = 0; i < rows; i += 1) {
//check if the index exists in the outer array (row)
if (!(i in myArray)) {
//if it doesn't exist, we need another array to fill
myArray[i] = [];
}
row = myArray[i];
for (j = 0; j < cols; j += 1) {
//check if the index exists in the inner array (column)
if (!(i in row)) {
//if it doesn't exist, we need to fill it with `0`
row[j] = 0;
}
}
}
When doing a MERGE in Oracle SQL, how can I update rows that aren't matched in the SOURCE?
merge into x as target using y as Source on target.ID = Source.ID
when not matched by target then insert
when matched then update
when not matched by source and target.ID is not null then
update whatevercolumn = 'isdeleted' ;
How to parse JSON to receive a Date object in JavaScript?
AngularJS couldn't parse .NET JSON date /Date(xxxxxxxxxxxxx)/ string either..
I side stepped this issue by formatting the date to its ISO 8601 string representation instead of dumping the Date object directly...
Here is a sample of ASP.NET MVC code..
return Json(new {
date : DateTime.Now.ToString("O") //ISO 8601 Angular understands this format
});
I tried RFC 1123 but it doesn't work.. Angular treats this as string instead of Date.
return Json(new {
date : DateTime.Now.ToString("R") //RFC 1123 Angular won't parse this
});
How do I remove  from the beginning of a file?
If you need to be able to remove the BOM from UTF-8 encoded files, you first need to get hold of an editor that is aware of them.
I personally use E Text Editor.
In the bottom right, there are options for character encoding, including the BOM tag. Load your file, deselect Byte Order Marker if it is selected, resave, and it should be done.
Alt text http://oth4.com/encoding.png
{kind=link}
E is not free, but there is a free trial, and it is an excellent editor (limited TextMate compatibility).
How to turn a String into a JavaScript function call?
While I like the first answer and I hate eval, I'd like to add that there's another way (similar to eval) so if you can go around it and not use it, you better do. But in some cases you may want to call some javascript code before or after some ajax call and if you have this code in a custom attribute instead of ajax you could use this:
var executeBefore = $(el).attr("data-execute-before-ajax");
if (executeBefore != "") {
var fn = new Function(executeBefore);
fn();
}
Or eventually store this in a function cache if you may need to call it multiple times.
Again - don't use eval or this method if you have another way to do that.
How to query as GROUP BY in django?
You need to do custom SQL as exemplified in this snippet:
Or in a custom manager as shown in the online Django docs:
/lib/ld-linux.so.2: bad ELF interpreter: No such file or directory
yum install glibc.i686
install this.
What is compiler, linker, loader?
Compiler:
It will read source file which may be of type .c or .cpp etc and translates that to .o file called as object file.
Linker:
It combines the several .o files which may be generated for multiple source files into an executable file (ELF format in GCC). There are two type of linking:
- static linking
- dynamic linking
Loader:
A program which loads the executable file to the primary memory of the machine.
For an in-detail study about the these three stages of program execution in Linux, please read this.
Stop fixed position at footer
If your elements are glitching this is probably because when you change the position to relative the Y position of the footer increases which tries to send the item back to fixed which creates a loop. You can avoid this by setting two different cases when scrolling up and down. You don't even need to reference the fixed element, just the footer, and window size.
const footer = document.querySelector('footer');
document.addEventListener("scroll", checkScroll);
let prevY = window.scrollY + window.innerHeight;
function checkScroll() {
let footerTop = getRectTop(footer) + window.scrollY;
let windowBottomY = window.scrollY + window.innerHeight;
if (prevY < windowBottomY) { // Scroll Down
if (windowBottomY > footerTop)
setScrolledToFooter(true) // using React state. Change class or change style in JS.
} else { // Scroll Up
if (windowBottomY <= footerTop)
setScrolledToFooter(false)
}
prevY = windowBottomY
};
function getRectTop(el) {
var rect = el.getBoundingClientRect();
return rect.top;
}
and the position of the element in the style object as follows:
position: scrolledToFooter ? 'relative' : 'fixed'
Visual Studio Code always asking for git credentials
I had a similar problem in Visual Studio Code.
I solved by changing the remote url to https. (in file .git/config)
[remote "origin"]
url = https://[email protected]/plesk-git/project.git
and also
git config --global credential.helper wincred
pulled again, windows credential popup came out, problems solved.
Getting distance between two points based on latitude/longitude
For people (like me) coming here via search engine and just looking for a solution which works out of the box, I recommend installing mpu. Install it via pip install mpu --user and use it like this to get the haversine distance:
import mpu
# Point one
lat1 = 52.2296756
lon1 = 21.0122287
# Point two
lat2 = 52.406374
lon2 = 16.9251681
# What you were looking for
dist = mpu.haversine_distance((lat1, lon1), (lat2, lon2))
print(dist) # gives 278.45817507541943.
An alternative package is gpxpy.
If you don't want dependencies, you can use:
import math
def distance(origin, destination):
"""
Calculate the Haversine distance.
Parameters
----------
origin : tuple of float
(lat, long)
destination : tuple of float
(lat, long)
Returns
-------
distance_in_km : float
Examples
--------
>>> origin = (48.1372, 11.5756) # Munich
>>> destination = (52.5186, 13.4083) # Berlin
>>> round(distance(origin, destination), 1)
504.2
"""
lat1, lon1 = origin
lat2, lon2 = destination
radius = 6371 # km
dlat = math.radians(lat2 - lat1)
dlon = math.radians(lon2 - lon1)
a = (math.sin(dlat / 2) * math.sin(dlat / 2) +
math.cos(math.radians(lat1)) * math.cos(math.radians(lat2)) *
math.sin(dlon / 2) * math.sin(dlon / 2))
c = 2 * math.atan2(math.sqrt(a), math.sqrt(1 - a))
d = radius * c
return d
if __name__ == '__main__':
import doctest
doctest.testmod()
The other alternative package is [haversine][1]
from haversine import haversine, Unit
lyon = (45.7597, 4.8422) # (lat, lon)
paris = (48.8567, 2.3508)
haversine(lyon, paris)
>> 392.2172595594006 # in kilometers
haversine(lyon, paris, unit=Unit.MILES)
>> 243.71201856934454 # in miles
# you can also use the string abbreviation for units:
haversine(lyon, paris, unit='mi')
>> 243.71201856934454 # in miles
haversine(lyon, paris, unit=Unit.NAUTICAL_MILES)
>> 211.78037755311516 # in nautical miles
They claim to have performance optimization for distances between all points in two vectors
from haversine import haversine_vector, Unit
lyon = (45.7597, 4.8422) # (lat, lon)
paris = (48.8567, 2.3508)
new_york = (40.7033962, -74.2351462)
haversine_vector([lyon, lyon], [paris, new_york], Unit.KILOMETERS)
>> array([ 392.21725956, 6163.43638211])
Is there a 'box-shadow-color' property?
No:
http://www.w3.org/TR/css3-background/#the-box-shadow
You can verify this in Chrome and Firefox by checking the list of computed styles. Other properties that have shorthand methods (like border-radius) have their variations defined in the spec.
As with most missing "long-hand" CSS properties, CSS variables can solve this problem:
#el {
--box-shadow-color: palegoldenrod;
box-shadow: 1px 2px 3px var(--box-shadow-color);
}
#el:hover {
--box-shadow-color: goldenrod;
}
C# : assign data to properties via constructor vs. instantiating
Second approach is object initializer in C#
Object initializers let you assign values to any accessible fields or properties of an object at creation time without having to explicitly invoke a constructor.
The first approach
var albumData = new Album("Albumius", "Artistus", 2013);
explicitly calls the constructor, whereas in second approach constructor call is implicit. With object initializer you can leave out some properties as well. Like:
var albumData = new Album
{
Name = "Albumius",
};
Object initializer would translate into something like:
var albumData;
var temp = new Album();
temp.Name = "Albumius";
temp.Artist = "Artistus";
temp.Year = 2013;
albumData = temp;
Why it uses a temporary object (in debug mode) is answered here by Jon Skeet.
As far as advantages for both approaches are concerned, IMO, object initializer would be easier to use specially if you don't want to initialize all the fields. As far as performance difference is concerned, I don't think there would any since object initializer calls the parameter less constructor and then assign the properties. Even if there is going to be performance difference it should be negligible.
Remove gutter space for a specific div only
Since no one has mentioned this, to add to the no-gutter answer above which works, if you want custom spaced gutters, all you have to do is specify the value in px for the margin left and right properties, and padding left and right properties like so;
.row.no-gutter {
margin-left: 4px;
margin-right: 4px;
}
.row.no-gutter [class*='col-']:not(:first-child),
.row.no-gutter [class*='col-']:not(:last-child) {
padding-right: 4px;
padding-left: 4px;
}
How can I conditionally require form inputs with AngularJS?
if you want put a input required if other is written:
<input type='text'
name='name'
ng-model='person.name'/>
<input type='text'
ng-model='person.lastname'
ng-required='person.name' />
Regards.
Getting "Could not find function xmlCheckVersion in library libxml2. Is libxml2 installed?" when installing lxml through pip
I tried install a lib that depends lxml and nothing works. I see a message when build was started: "Building without Cython", so after install cython with apt-get install cython, lxml was installed.
Update Git submodule to latest commit on origin
Note, while the modern form of updating submodule commits would be:
git submodule update --recursive --remote --merge --force
The older form was:
git submodule foreach --quiet git pull --quiet origin
Except... this second form is not really "quiet".
See commit a282f5a (12 Apr 2019) by Nguy?n Thái Ng?c Duy (pclouds).
(Merged by Junio C Hamano -- gitster -- in commit f1c9f6c, 25 Apr 2019)
submodule foreach: fix "<command> --quiet" not being respected
Robin reported that
git submodule foreach --quiet git pull --quiet originis not really quiet anymore.
It should be quiet before fc1b924 (submodule: portsubmodulesubcommand 'foreach' from shell to C, 2018-05-10, Git v2.19.0-rc0) becauseparseoptcan't accidentally eat options then."
git pull" behaves as if--quietis not given.This happens because
parseoptinsubmodule--helperwill try to parse both--quietoptions as if they are foreach's options, notgit-pull's.
The parsed options are removed from the command line. So when we do pull later, we execute just thisgit pull originWhen calling submodule helper, adding "
--" in front of "git pull" will stopparseoptfor parsing options that do not really belong tosubmodule--helper foreach.
PARSE_OPT_KEEP_UNKNOWNis removed as a safety measure.parseoptshould never see unknown options or something has gone wrong. There are also a couple usage string update while I'm looking at them.While at it, I also add "
--" to other subcommands that pass "$@" tosubmodule--helper. "$@" in these cases are paths and less likely to be--something-like-this.
But the point still stands,git-submodulehas parsed and classified what are options, what are paths.
submodule--helpershould never consider paths passed bygit-submoduleto be options even if they look like one.
And Git 2.23 (Q3 2019) fixes another issue: "git submodule foreach" did not protect command line options passed to the command to be run in each submodule correctly, when the "--recursive" option was in use.
See commit 30db18b (24 Jun 2019) by Morian Sonnet (momoson).
(Merged by Junio C Hamano -- gitster -- in commit 968eecb, 09 Jul 2019)
submodule foreach: fix recursion of options
Calling:
git submodule foreach --recursive <subcommand> --<option>leads to an error stating that the option
--<option>is unknown tosubmodule--helper.
That is of course only, when<option>is not a valid option forgit submodule foreach.The reason for this is, that above call is internally translated into a call to submodule--helper:
git submodule--helper foreach --recursive \ -- <subcommand> --<option>This call starts by executing the subcommand with its option inside the first level submodule and continues by calling the next iteration of the
submodule foreachcallgit --super-prefix <submodulepath> submodule--helper \ foreach --recursive <subcommand> --<option>inside the first level submodule. Note that the double dash in front of the subcommand is missing.
This problem starts to arise only recently, as the
PARSE_OPT_KEEP_UNKNOWNflag for the argument parsing ofgit submodule foreachwas removed in commit a282f5a.
Hence, the unknown option is complained about now, as the argument parsing is not properly ended by the double dash.This commit fixes the problem by adding the double dash in front of the subcommand during the recursion.
Note that, before Git 2.29 (Q4 2020), "git submodule update --quiet"(man) did not squelch underlying "rebase" and "pull" commands.
See commit 3ad0401 (30 Sep 2020) by Theodore Dubois (tbodt).
(Merged by Junio C Hamano -- gitster -- in commit 300cd14, 05 Oct 2020)
submodule update: silence underlying merge/rebase with "--quiet"Signed-off-by: Theodore Dubois
Commands such as
$ git pull --rebase --recurse-submodules --quietproduce non-quiet output from the merge or rebase.
Pass the--quietoption down when invoking "rebase" and "merge".Also fix the parsing of
git submodule update(man) -v.When e84c3cf3 ("
git-submodule.sh: accept verbose flag incmd_updateto be non-quiet", 2018-08-14, Git v2.19.0-rc0 -- merge) taught "git submodule update"(man) to take "--quiet", it apparently did not know how${GIT_QUIET:+--quiet} works, and reviewers seem to have missed that setting the variable to "0", rather than unsetting it, still results in "--quiet" being passed to underlying commands.
Python "SyntaxError: Non-ASCII character '\xe2' in file"
I had the same issue but it was because I copied and pasted the string as it is. Later when I manually typed the string as it is the error vanished.
I had the error due to the - sign. When I replaced it with manually inputting a - the error was solved.
Copied string 10 + 3 * 5/(16 - 4)
Manually typed string 10 + 3 * 5/(16 - 4)
you can clearly see there is a bit of difference between both the hyphens.
I think it's because of the different formatting used by different OS or maybe just different software.
SQLAlchemy ORDER BY DESCENDING?
One other thing you might do is:
.order_by("name desc")
This will result in: ORDER BY name desc. The disadvantage here is the explicit column name used in order by.
Java: object to byte[] and byte[] to object converter (for Tokyo Cabinet)
Use serialize and deserialize methods in SerializationUtils from commons-lang.
LogisticRegression: Unknown label type: 'continuous' using sklearn in python
I struggled with the same issue when trying to feed floats to the classifiers. I wanted to keep floats and not integers for accuracy. Try using regressor algorithms. For example:
import numpy as np
from sklearn import linear_model
from sklearn import svm
classifiers = [
svm.SVR(),
linear_model.SGDRegressor(),
linear_model.BayesianRidge(),
linear_model.LassoLars(),
linear_model.ARDRegression(),
linear_model.PassiveAggressiveRegressor(),
linear_model.TheilSenRegressor(),
linear_model.LinearRegression()]
trainingData = np.array([ [2.3, 4.3, 2.5], [1.3, 5.2, 5.2], [3.3, 2.9, 0.8], [3.1, 4.3, 4.0] ])
trainingScores = np.array( [3.4, 7.5, 4.5, 1.6] )
predictionData = np.array([ [2.5, 2.4, 2.7], [2.7, 3.2, 1.2] ])
for item in classifiers:
print(item)
clf = item
clf.fit(trainingData, trainingScores)
print(clf.predict(predictionData),'\n')
Forms authentication timeout vs sessionState timeout
<sessionState timeout="2" />
<authentication mode="Forms">
<forms name="userLogin" path="/" timeout="60" loginUrl="Login.aspx" slidingExpiration="true"/>
</authentication>
This configuration sends me to the login page every two minutes, which seems to controvert the earlier answers