Iterating through a list to render multiple widgets in Flutter?
Basically when you hit 'return' on a function the function will stop and will not continue your iteration, so what you need to do is put it all on a list and then add it as a children of a widget
you can do something like this:
Widget getTextWidgets(List<String> strings)
{
List<Widget> list = new List<Widget>();
for(var i = 0; i < strings.length; i++){
list.add(new Text(strings[i]));
}
return new Row(children: list);
}
or even better, you can use .map() operator and do something like this:
Widget getTextWidgets(List<String> strings)
{
return new Row(children: strings.map((item) => new Text(item)).toList());
}
How to verify if nginx is running or not?
None of the above answers worked for me so let me share my experience. I am running nginx in a docker container that has a port mapping (hostPort:containerPort) - 80:80 The above answers are giving me strange console output. Only the good old 'nmap' is working flawlessly even catching the nginx version. The command working for me is:
nmap -sV localhost -p 80
We are doing nmap using the -ServiceVersion switch on the localhost and port: 80. It works great for me.
Tkinter module not found on Ubuntu
The answer to your question is that Tkinter is renamed to tkinter in python3
that is with lowercase t
In python, how do I cast a class object to a dict
It's hard to say without knowing the whole context of the problem, but I would not override __iter__.
I would implement __what_goes_here__ on the class.
as_dict(self:
d = {...whatever you need...}
return d
Effective way to find any file's Encoding
Check this.
This is a port of Mozilla Universal Charset Detector and you can use it like this...
public static void Main(String[] args)
{
string filename = args[0];
using (FileStream fs = File.OpenRead(filename)) {
Ude.CharsetDetector cdet = new Ude.CharsetDetector();
cdet.Feed(fs);
cdet.DataEnd();
if (cdet.Charset != null) {
Console.WriteLine("Charset: {0}, confidence: {1}",
cdet.Charset, cdet.Confidence);
} else {
Console.WriteLine("Detection failed.");
}
}
}
Calculating time difference between 2 dates in minutes
I am using below code for today and database date.
TIMESTAMPDIFF(MINUTE,T.runTime,NOW()) > 20
According to the documentation, the first argument can be any of the following:
MICROSECOND
SECOND
MINUTE
HOUR
DAY
WEEK
MONTH
QUARTER
YEAR
How to convert Strings to and from UTF8 byte arrays in Java
Charset UTF8_CHARSET = Charset.forName("UTF-8");
String strISO = "{\"name\":\"?\"}";
System.out.println(strISO);
byte[] b = strISO.getBytes();
for (byte c: b) {
System.out.print("[" + c + "]");
}
String str = new String(b, UTF8_CHARSET);
System.out.println(str);
How can I detect when the mouse leaves the window?
I tried one after other and found a best answer at the time:
https://stackoverflow.com/a/3187524/985399
I skip old browsers so I made the code shorter to work on modern browsers (IE9+)
document.addEventListener("mouseout", function(e) {_x000D_
let t = e.relatedTarget || e.toElement;_x000D_
if (!t || t.nodeName == "HTML") {_x000D_
console.log("left window");_x000D_
}_x000D_
});_x000D_
_x000D_
document.write("<br><br>PROBLEM<br><br><div>Mouseout trigg on HTML elements</div>")Here you see the browser support
That was pretty short I thought
But a problem still remained because "mouseout" trigg on all elements in the document.
To prevent it from happen, use mouseleave (IE5.5+). See the good explanation in the link.
The following code works without triggering on elements inside the element to be inside or outside of. Try also drag-release outside the document.
var x = 0_x000D_
_x000D_
document.addEventListener("mouseleave", function(e) { console.log(x++) _x000D_
})_x000D_
_x000D_
document.write("<br><br>SOLUTION<br><br><div>Mouseleave do not trigg on HTML elements</div>")You can set the event on any HTML element. Do not have the event on document.body though, because the windows scrollbar may shrink the body and fire when mouse pointer is abowe the scroll bar when you want to scroll but not want to trigg a mouseLeave event over it. Set it on document instead, as in the example.
How to unpublish an app in Google Play Developer Console
- Go to your "play.google.com" dashboard
- Select your app
- In left menu item select "Store presence"
- Then, select "Pricing & distribution"
- Click "Unpublish" in "App Availability" section
Clear and reset form input fields
state={
name:"",
email:""
}
handalSubmit = () => {
after api call
let resetFrom = {}
fetch('url')
.then(function(response) {
if(response.success){
resetFrom{
name:"",
email:""
}
}
})
this.setState({...resetFrom})
}
DB2 SQL error: SQLCODE: -206, SQLSTATE: 42703
That only means that an undefined column or parameter name was detected. The errror that DB2 gives should point what that may be:
DB2 SQL Error: SQLCODE=-206, SQLSTATE=42703, SQLERRMC=[THE_UNDEFINED_COLUMN_OR_PARAMETER_NAME], DRIVER=4.8.87
Double check your table definition. Maybe you just missed adding something.
I also tried google-ing this problem and saw this:
http://www.coderanch.com/t/515475/JDBC/databases/sql-insert-statement-giving-sqlcode
WordPress - Check if user is logged in
Try following code that worked fine for me
global $current_user;
get_currentuserinfo();
Then, use following code to check whether user has logged in or not.
if ($current_user->ID == '') {
//show nothing to user
}
else {
//write code to show menu here
}
javax.net.ssl.SSLHandshakeException: Received fatal alert: handshake_failure
Issue resolved.!!! Below are the solutions.
For Java 6: Add below jars into {JAVA_HOME}/jre/lib/ext. 1. bcprov-ext-jdk15on-154.jar 2. bcprov-jdk15on-154.jar
Add property into {JAVA_HOME}/jre/lib/security/java.security security.provider.1=org.bouncycastle.jce.provider.BouncyCastleProvider
Java 7:download jar from below link and add to {JAVA_HOME}/jre/lib/security http://www.oracle.com/technetwork/java/javase/downloads/jce-7-download-432124.html
Java 8:download jar from below link and add to {JAVA_HOME}/jre/lib/security http://www.oracle.com/technetwork/java/javase/downloads/jce8-download-2133166.html
Issue is that it is failed to decrypt 256 bits of encryption.
MySQL Workbench Dark Theme
Quoting Yoga...
For Mac users, the code_editor.xml file is in MBP HD/ Applications/MySQLWorkbench.app/Contents/Resources/data/
I just discovered by dumbfounded experimentation (i.e. first thing I tried, worked) that if I copy that file to...
/Users/your.username/Library/Application Support/MySQL/Workbench/code_editor.xml
...and then edit it there, it does indeed override. Just worked perfectly for me on Mac OS X Sierra and MySQL Workbench 6.3.
Python - OpenCV - imread - Displaying Image
This can help you
namedWindow( "Display window", CV_WINDOW_AUTOSIZE );// Create a window for display.
imshow( "Display window", image ); // Show our image inside it.
Android SDK location
If you have downloaded sdk manager zip (from https://developer.android.com/studio/#downloads), then you have Android SDK Location as root of the extracted folder.
So silly, But it took time for me as a beginner.
How do you properly use WideCharToMultiByte
Elaborating on the answer provided by Brian R. Bondy: Here's an example that shows why you can't simply size the output buffer to the number of wide characters in the source string:
#include <windows.h>
#include <stdio.h>
#include <wchar.h>
#include <string.h>
/* string consisting of several Asian characters */
wchar_t wcsString[] = L"\u9580\u961c\u9640\u963f\u963b\u9644";
int main()
{
size_t wcsChars = wcslen( wcsString);
size_t sizeRequired = WideCharToMultiByte( 950, 0, wcsString, -1,
NULL, 0, NULL, NULL);
printf( "Wide chars in wcsString: %u\n", wcsChars);
printf( "Bytes required for CP950 encoding (excluding NUL terminator): %u\n",
sizeRequired-1);
sizeRequired = WideCharToMultiByte( CP_UTF8, 0, wcsString, -1,
NULL, 0, NULL, NULL);
printf( "Bytes required for UTF8 encoding (excluding NUL terminator): %u\n",
sizeRequired-1);
}
And the output:
Wide chars in wcsString: 6
Bytes required for CP950 encoding (excluding NUL terminator): 12
Bytes required for UTF8 encoding (excluding NUL terminator): 18
CSS: How to align vertically a "label" and "input" inside a "div"?
div {_x000D_
display: table-cell;_x000D_
vertical-align: middle;_x000D_
height: 50px;_x000D_
border: 1px solid red;_x000D_
}<div>_x000D_
<label for='name'>Name:</label>_x000D_
<input type='text' id='name' />_x000D_
</div>The advantages of this method is that you can change the height of the div, change the height of the text field and change the font size and everything will always stay in the middle.
Forcing label to flow inline with input that they label
If you want they to be paragraph, then use it.
<p><label for="id1">label1:</label> <input type="text" id="id1"/></p>
<p><label for="id2">label2:</label> <input type="text" id="id2"/></p>
Both <label> and <input> are paragraph and flow content so you can insert as paragraph elements and as block elements.
Delimiters in MySQL
You define a DELIMITER to tell the mysql client to treat the statements, functions, stored procedures or triggers as an entire statement. Normally in a .sql file you set a different DELIMITER like $$. The DELIMITER command is used to change the standard delimiter of MySQL commands (i.e. ;). As the statements within the routines (functions, stored procedures or triggers) end with a semi-colon (;), to treat them as a compound statement we use DELIMITER. If not defined when using different routines in the same file or command line, it will give syntax error.
Note that you can use a variety of non-reserved characters to make your own custom delimiter. You should avoid the use of the backslash (\) character because that is the escape character for MySQL.
DELIMITER isn't really a MySQL language command, it's a client command.
Example
DELIMITER $$
/*This is treated as a single statement as it ends with $$ */
DROP PROCEDURE IF EXISTS `get_count_for_department`$$
/*This routine is a compound statement. It ends with $$ to let the mysql client know to execute it as a single statement.*/
CREATE DEFINER=`student`@`localhost` PROCEDURE `get_count_for_department`(IN the_department VARCHAR(64), OUT the_count INT)
BEGIN
SELECT COUNT(*) INTO the_count FROM employees where department=the_department;
END$$
/*DELIMITER is set to it's default*/
DELIMITER ;
JavaScript seconds to time string with format hh:mm:ss
I'm personally prefer the leading unit (days, hours, minutes) without leading zeros. But seconds should always be leaded by minutes (0:13), this presentation is easily considered as 'duration', without further explanation (marking as min, sec(s), etc.), usable in various languages (internationalization).
// returns (-)d.h:mm:ss(.f)
// (-)h:mm:ss(.f)
// (-)m:ss(.f)
function formatSeconds (value, fracDigits) {
var isNegative = false;
if (isNaN(value)) {
return value;
} else if (value < 0) {
isNegative = true;
value = Math.abs(value);
}
var days = Math.floor(value / 86400);
value %= 86400;
var hours = Math.floor(value / 3600);
value %= 3600;
var minutes = Math.floor(value / 60);
var seconds = (value % 60).toFixed(fracDigits || 0);
if (seconds < 10) {
seconds = '0' + seconds;
}
var res = hours ? (hours + ':' + ('0' + minutes).slice(-2) + ':' + seconds) : (minutes + ':' + seconds);
if (days) {
res = days + '.' + res;
}
return (isNegative ? ('-' + res) : res);
}
//imitating the server side (.net, C#) duration formatting like:
public static string Format(this TimeSpan interval)
{
string pattern;
if (interval.Days > 0) pattern = @"d\.h\:mm\:ss";
else if (interval.Hours > 0) pattern = @"h\:mm\:ss";
else pattern = @"m\:ss";
return string.Format("{0}", interval.ToString(pattern));
}
Merge PDF files with PHP
This worked for me on Windows
- download PDFtk free from https://www.pdflabs.com/tools/pdftk-the-pdf-toolkit/
- drop folder (PDFtk) into the root of c:
add the following to your php code where $file1 is the location and name of the first PDF file, $file2 is the location and name of the second and $newfile is the location and name of the destination file
$file1 = ' c:\\\www\\\folder1\\\folder2\\\file1.pdf'; $file2 = ' c:\\\www\\\folder1\\\folder2\\\file2.pdf'; $file3 = ' c:\\\www\\\folder1\\\folder2\\\file3.pdf'; $command = 'cmd /c C:\\\pdftk\\\bin\\\pdftk.exe '.$file1.$file2.$newfile; $result = exec($command);
Error: Argument is not a function, got undefined
I had the same error with a big mistake:
appFormid.controller('TreeEditStepControlsCtrl', [$scope, function($scope){
}]);
You see ? i forgot the '' around the first $scope, the right syntax is of course:
appFormid.controller('TreeEditStepControlsCtrl', ['$scope', function($scope){
}]);
A first error i didn't see immediatly was: "$scope is not defined", followed by "Error: [ng:areq] Argument 'TreeEditStepControlsCtrl' is not a function, got undefined"
Quickly getting to YYYY-mm-dd HH:MM:SS in Perl
Use strftime in the standard POSIX module. The arguments to strftime in Perl’s binding were designed to align with the return values from localtime and gmtime. Compare
strftime(fmt, sec, min, hour, mday, mon, year, wday = -1, yday = -1, isdst = -1)
with
my ($sec,$min,$hour,$mday,$mon,$year,$wday, $yday, $isdst) = gmtime(time);
Example command-line use is
$ perl -MPOSIX -le 'print strftime "%F %T", localtime $^T'
or from a source file as in
use POSIX;
print strftime "%F %T", localtime time;
Some systems do not support the %F and %T shorthands, so you will have to be explicit with
print strftime "%Y-%m-%d %H:%M:%S", localtime time;
or
print strftime "%Y-%m-%d %H:%M:%S", gmtime time;
Note that time returns the current time when called whereas $^T is fixed to the time when your program started. With gmtime, the return value is the current time in GMT. Retrieve time in your local timezone with localtime.
Run jQuery function onclick
There's several things you can improve upon here. To start, there's no reason to use an <a> (anchor) tag since you don't have a link.
Every element can be bound to click and hover events... divs, spans, labels, inputs, etc.
I can't really identify what it is you're trying to do, though. You're mixing the goal with your own implementation and, from what I've seen so far, you're not really sure how to do it. Could you better illustrate what it is you're trying to accomplish?
== EDIT ==
The requirements are still very vague. I've implemented a very quick version of what I'm imagining you're saying ... or something close that illustrates how you might be able to do it. Left me know if I'm on the right track.
Add string in a certain position in Python
I think the above answers are fine, but I would explain that there are some unexpected-but-good side effects to them...
def insert(string_s, insert_s, pos_i=0):
return string_s[:pos_i] + insert_s + string_s[pos_i:]
If the index pos_i is very small (too negative), the insert string gets prepended. If too long, the insert string gets appended. If pos_i is between -len(string_s) and +len(string_s) - 1, the insert string gets inserted into the correct place.
string decode utf-8
the core functions are getBytes(String charset) and new String(byte[] data). you can use these functions to do UTF-8 decoding.
UTF-8 decoding actually is a string to string conversion, the intermediate buffer is a byte array. since the target is an UTF-8 string, so the only parameter for new String() is the byte array, which calling is equal to new String(bytes, "UTF-8")
Then the key is the parameter for input encoded string to get internal byte array, which you should know beforehand. If you don't, guess the most possible one, "ISO-8859-1" is a good guess for English user.
The decoding sentence should be
String decoded = new String(encoded.getBytes("ISO-8859-1"));
How do I simulate placeholder functionality on input date field?
The HTML5 date input field actually does not support the attribute for placeholder. It will always be ignored by the browser, at least as per the current spec.
How to use foreach with a hash reference?
In Perl 5.14 (it works in now in Perl 5.13), we'll be able to just use keys on the hash reference
use v5.13.7;
foreach my $key (keys $ad_grp_ref) {
...
}
What does the construct x = x || y mean?
|| is the boolean OR operator. As in javascript, undefined, null, 0, false are considered as falsy values.
It simply means
true || true = true
false || true = true
true || false = true
false || false = false
undefined || "value" = "value"
"value" || undefined = "value"
null || "value" = "value"
"value" || null = "value"
0 || "value" = "value"
"value" || 0 = "value"
false || "value" = "value"
"value" || false = "value"
How to add image background to btn-default twitter-bootstrap button?
<!-- Latest compiled and minified CSS -->_x000D_
<link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.5/css/bootstrap.min.css">_x000D_
_x000D_
<!-- Optional theme -->_x000D_
<link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.5/css/bootstrap-theme.min.css">_x000D_
_x000D_
<!-- Latest compiled and minified JavaScript -->_x000D_
<script src="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.5/js/bootstrap.min.js"></script>_x000D_
_x000D_
_x000D_
<style type="text/css">_x000D_
.sign-in-facebook_x000D_
{_x000D_
background-image: url('http://i.stack.imgur.com/e2S63.png');_x000D_
background-position: -9px -7px;_x000D_
background-repeat: no-repeat;_x000D_
background-size: 39px 43px;_x000D_
padding-left: 41px;_x000D_
color: #000;_x000D_
}_x000D_
.sign-in-facebook:hover_x000D_
{_x000D_
background-image: url('http://i.stack.imgur.com/e2S63.png');_x000D_
background-position: -9px -7px;_x000D_
background-repeat: no-repeat;_x000D_
background-size: 39px 43px;_x000D_
padding-left: 41px;_x000D_
color: #000;_x000D_
}_x000D_
</style>_x000D_
<p>My current button got white background<br/>_x000D_
<input type="button" value="Sign In with Facebook" class="sign-in-facebook btn btn-secondary" style="margin-top:2px; margin-bottom:2px;" >_x000D_
</p>_x000D_
<p>I need the current btn-default style like below<br/>_x000D_
<input type="button" class="btn btn-default" value="Sign In with Facebook" />_x000D_
</p>_x000D_
<strong>NOTE:</strong> facebook icon at left side of the button.How do you simulate Mouse Click in C#?
I use the InvokeOnClick() method. It takes two arguments: Control and EventArgs. If you need the EventArgs, then create an instance of it and pass it in, else use InvokeOnClick(controlToClick, null);. You can use a variety of Mouse event related arguments that derive from EventArgs such as MouseEventArgs.
How to sum up an array of integers in C#
In one of my apps I used :
public class ClassBlock
{
public int[] p;
public int Sum
{
get { int s = 0; Array.ForEach(p, delegate (int i) { s += i; }); return s; }
}
}
How to return a boolean method in java?
Best way would be to declare Boolean variable within the code block and return it at end of code, like this:
public boolean Test(){
boolean booleanFlag= true;
if (A>B)
{booleanFlag= true;}
else
{booleanFlag = false;}
return booleanFlag;
}
I find this the best way.
How to open/run .jar file (double-click not working)?
I was having this same issue for both Windows 8 and Windows Server 2012 configurations.
I had installed the latest version of JDK Java 7 and had set my **JAVA_HOME**system env variable to the jre folder: *C:\Program Files (x86)\Java\jre7*
I also added the bin folder to my **Path** system env variable: *%JAVA_HOME%\bin*
But I was still having problems with double clicking the executable jar files. I found another system env variable OPENDS_JAVA_ARGS that can be used to set the optional properties for javaw.exe. So I added this variable and set it to: -jar
Now I am able to run the executable jar files when double clicking them.
Mapping a JDBC ResultSet to an object
Complete solution using @TEH-EMPRAH ideas and Generic casting from Cast Object to Generic Type for returning
import annotations.Column;
import java.lang.reflect.Field;
import java.lang.reflect.InvocationTargetException;
import java.sql.SQLException;
import java.util.*;
public class ObjectMapper<T> {
private Class clazz;
private Map<String, Field> fields = new HashMap<>();
Map<String, String> errors = new HashMap<>();
public DataMapper(Class clazz) {
this.clazz = clazz;
List<Field> fieldList = Arrays.asList(clazz.getDeclaredFields());
for (Field field : fieldList) {
Column col = field.getAnnotation(Column.class);
if (col != null) {
field.setAccessible(true);
fields.put(col.name(), field);
}
}
}
public T map(Map<String, Object> row) throws SQLException {
try {
T dto = (T) clazz.getConstructor().newInstance();
for (Map.Entry<String, Object> entity : row.entrySet()) {
if (entity.getValue() == null) {
continue; // Don't set DBNULL
}
String column = entity.getKey();
Field field = fields.get(column);
if (field != null) {
field.set(dto, convertInstanceOfObject(entity.getValue()));
}
}
return dto;
} catch (IllegalAccessException | InstantiationException | NoSuchMethodException | InvocationTargetException e) {
e.printStackTrace();
throw new SQLException("Problem with data Mapping. See logs.");
}
}
public List<T> map(List<Map<String, Object>> rows) throws SQLException {
List<T> list = new LinkedList<>();
for (Map<String, Object> row : rows) {
list.add(map(row));
}
return list;
}
private T convertInstanceOfObject(Object o) {
try {
return (T) o;
} catch (ClassCastException e) {
return null;
}
}
}
and then in terms of how it ties in with the database, I have the following:
// connect to database (autocloses)
try (DataConnection conn = ds1.getConnection()) {
// fetch rows
List<Map<String, Object>> rows = conn.nativeSelect("SELECT * FROM products");
// map rows to class
ObjectMapper<Product> objectMapper = new ObjectMapper<>(Product.class);
List<Product> products = objectMapper.map(rows);
// display the rows
System.out.println(rows);
// display it as products
for (Product prod : products) {
System.out.println(prod);
}
} catch (Exception e) {
e.printStackTrace();
}
How do you install Boost on MacOS?
Just get the source, and compile Boost yourself; it has become very easy. Here is an example for the current version of Boost on the current macOS as of this writing:
- Download the the .tar.gz from https://www.boost.org/users/download/#live
Unpack and go into the directory:
tar -xzf boost_1_50_0.tar.gz cd boost_1_50_0Configure (and build
bjam):./bootstrap.sh --prefix=/some/dir/you/would/like/to/prefixBuild:
./b2Install:
./b2 install
Depending on the prefix you choose in Step 3, you might need to sudo Step 5, if the script tries copy files to a protected location.
Convert from ASCII string encoded in Hex to plain ASCII?
>>> txt = '7061756c'
>>> ''.join([chr(int(''.join(c), 16)) for c in zip(txt[0::2],txt[1::2])])
'paul'
i'm just having fun, but the important parts are:
>>> int('0a',16) # parse hex
10
>>> ''.join(['a', 'b']) # join characters
'ab'
>>> 'abcd'[0::2] # alternates
'ac'
>>> zip('abc', '123') # pair up
[('a', '1'), ('b', '2'), ('c', '3')]
>>> chr(32) # ascii to character
' '
will look at binascii now...
>>> print binascii.unhexlify('7061756c')
paul
cool (and i have no idea why other people want to make you jump through hoops before they'll help).
Cross-platform way of getting temp directory in Python
The simplest way, based on @nosklo's comment and answer:
import tempfile
tmp = tempfile.mkdtemp()
But if you want to manually control the creation of the directories:
import os
from tempfile import gettempdir
tmp = os.path.join(gettempdir(), '.{}'.format(hash(os.times())))
os.makedirs(tmp)
That way you can easily clean up after yourself when you are done (for privacy, resources, security, whatever) with:
from shutil import rmtree
rmtree(tmp, ignore_errors=True)
This is similar to what applications like Google Chrome and Linux systemd do. They just use a shorter hex hash and an app-specific prefix to "advertise" their presence.
How to get .pem file from .key and .crt files?
What I have observed is: if you use openssl to generate certificates, it captures both the text part and the base64 certificate part in the crt file. The strict pem format says (wiki definition) that the file should start and end with BEGIN and END.
.pem – (Privacy Enhanced Mail) Base64 encoded DER certificate, enclosed between "-----BEGIN CERTIFICATE-----" and "-----END CERTIFICATE-----"
So for some libraries (I encountered this in java) that expect strict pem format, the generated crt would fail the validation as an 'invalid pem format'.
Even if you copy or grep the lines with BEGIN/END CERTIFICATE, and paste it in a cert.pem file, it should work.
Here is what I do, not very clean, but works for me, basically it filters the text starting from BEGIN line:
grep -A 1000 BEGIN cert.crt > cert.pem
SQL how to increase or decrease one for a int column in one command
If my understanding is correct, updates should be pretty simple. I would just do the following.
UPDATE TABLE SET QUANTITY = QUANTITY + 1 and
UPDATE TABLE SET QUANTITY = QUANTITY - 1 where QUANTITY > 0
You may need additional filters to just update a single row instead of all the rows.
For inserts, you can cache some unique id related to your record locally and check against this cache and decide whether to insert or not. The alternative approach is to always insert and check for PK violation error and ignore since this is a redundant insert.
How can I use std::maps with user-defined types as key?
Keys must be comparable, but you haven't defined a suitable operator< for your custom class.
How do you exit from a void function in C++?
You mean like this?
void foo ( int i ) {
if ( i < 0 ) return; // do nothing
// do something
}
How to retrieve Key Alias and Key Password for signed APK in android studio(migrated from Eclipse)
Android Studio 3.0 below working method:
Find your old zipped project.
If you have built the apk, you'll find the password in file:
Project\.gradle\2.14.1\taskArtifacts\taskArtifacts.bin
Pandroid.injected.signing.store.password=password
If you don't have zipped project, search your git repositories if you have .gradle folder pushed or not.
Otherwise you'll have to recover files and search files by content "Pandroid.injected.signing.store.password".
Extract string between two strings in java
I have answered this question here: https://stackoverflow.com/a/38238785/1773972
Basically use
StringUtils.substringBetween(str, "<%=", "%>");
This requirs using "Apache commons lang" library: https://mvnrepository.com/artifact/org.apache.commons/commons-lang3/3.4
This library has a lot of useful methods for working with string, you will really benefit from exploring this library in other areas of your java code !!!
How can I determine the current CPU utilization from the shell?
Maybe something like this
ps -eo pid,pcpu,comm
And if you like to parse and maybe only look at some processes.
#!/bin/sh
ps -eo pid,pcpu,comm | awk '{if ($2 > 4) print }' >> ~/ps_eo_test.txt
CSS hexadecimal RGBA?
RGB='#ffabcd';
A='0.5';
RGBA='('+parseInt(RGB.substring(1,3),16)+','+parseInt(RGB.substring(3,5),16)+','+parseInt(RGB.substring(5,7),16)+','+A+')';
How do you update a DateTime field in T-SQL?
The string literal is pased according to the current dateformat setting, see SET DATEFORMAT. One format which will always work is the '20090525' one.
Now, of course, you need to define 'does not work'. No records gets updated? Perhaps the Id=1 doesn't match any record...
If it says 'One record changed' then perhaps you need to show us how you verify...
What is the current choice for doing RPC in Python?
There are some attempts at making SOAP work with python, but I haven't tested it much so I can't say if it is good or not.
SOAPy is one example.
document.getElementById().value and document.getElementById().checked not working for IE
Jin Yong - IE has an issue with polluting the global scope with object references to any DOM elements with a "name" or "id" attribute set on the "initial" page load.
Thus you may have issues due to your variable name.
Try this and see if it works.
var someOtherName="abc";
// ^^^^^^^^^^^^^
document.getElementById('msg').value = someOtherName;
document.getElementById('sp_100').checked = true;
There is a chance (in your original code) that IE attempts to set the value of the input to a reference to that actual element (ignores the error) but leaves you with no new value.
Keep in mind that in IE6/IE7 case doesn't matter for naming objects. IE believes that "foo" "Foo" and "FOO" are all the same object.
How do I find where JDK is installed on my windows machine?
In Windows at the command prompt
where javac
Remove a string from the beginning of a string
str_replace ( mixed $search , mixed $replace , mixed $subject [, int &$count ] )
now does what you want.
$str = "bla_string_bla_bla_bla";
str_replace("bla_","",$str,1);
Two dimensional array list
If your platform matrix supports Java 7 then you can use like below
List<List<String>> myList = new ArrayList<>();
How to add an event after close the modal window?
If you're using version 3.x of Bootstrap, the correct way to do this now is:
$('#myModal').on('hidden.bs.modal', function (e) {
// do something...
})
Scroll down to the events section to learn more.
http://getbootstrap.com/javascript/#modals-usage
This appears to remain unchanged for whenever version 4 releases (http://v4-alpha.getbootstrap.com/components/modal/#events), but if it does I'll be sure to update this post with the relevant information.
Delete rows from multiple tables using a single query (SQL Express 2005) with a WHERE condition
DELETE TB1, TB2
FROM customer_details
LEFT JOIN customer_booking on TB1.cust_id = TB2.fk_cust_id
WHERE TB1.cust_id = $id
PHP XML Extension: Not installed
In Centos
sudo yum install php-xml
and restart apache
sudo service httpd restart
Android ListView with onClick items
for what kind of Hell implementing Parcelable ?
he is passing to adapter String[] so
- get item(String) at position
- create intent
- put it as extra
- start activity
- in activity get extra
to store product list you can use here HashMap (for example as STATIC object)
example class describing product:
public class Product {
private String _name;
private String _description;
private int _id
public Product(String name, String description,int id) {
_name = name;
_desctription = description;
_id = id;
}
public String getName() {
return _name;
}
public String getDescription() {
return _description;
}
}
Product dell = new Product("dell","this is dell",1);
HashMap<String,Product> _hashMap = new HashMap<>();
_hashMap.put(dell.getName(),dell);
then u pass to adapter set of keys as:
String[] productNames = _hashMap.keySet().toArray(new String[_hashMap.size()]);
when in adapter u return view u set listener like this for example:
@Override
public View getView(int position, View convertView, ViewGroup parent) {
Context context = parent.getContext();
String itemName = getItem(position)
someView.setOnClikListener(new MyOnClickListener(context, itemName));
}
private class MyOnClickListener implements View.OnClickListener {
private String _itemName;
private Context _context
public MyOnClickListener(Context context, String itemName) {
_context = context;
_itemName = itemName;
}
@Override
public void onClick(View view) {
//------listener onClick example method body ------
Intent intent = new Intent(_context, SomeClassToHandleData.class);
intent.putExtra(key_to_product_name,_itemName);
_context.startActivity(intent);
}
}
then in other activity:
@Override
public void onCreate(Bundle) {
String productName = getIntent().getExtra(key_to_product_name);
Product product = _hashMap.get(productName);
}
*key_to_product_name is a public static String to serve as key for extra
ps. sorry for typo i was in hurry :) ps2. this shoud give you a idea how to do it ps3. when i will have more time i I'll add a detailed description
MY COMMENT:
- DO NOT USE ANY SWITCH STATEMENT
- DO NOT CREATE SEPARATE ACTIVITIES FOR EACH PRODUCT ( U NEED ONLY ONE)
vba: get unique values from array
The Collection and Dictionary solutions are all nice and shine for a short approach, but if you want speed try using a more direct approach:
Function ArrayUnique(ByVal aArrayIn As Variant) As Variant
''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''
' ArrayUnique
' This function removes duplicated values from a single dimension array
''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''
Dim aArrayOut() As Variant
Dim bFlag As Boolean
Dim vIn As Variant
Dim vOut As Variant
Dim i%, j%, k%
ReDim aArrayOut(LBound(aArrayIn) To UBound(aArrayIn))
i = LBound(aArrayIn)
j = i
For Each vIn In aArrayIn
For k = j To i - 1
If vIn = aArrayOut(k) Then bFlag = True: Exit For
Next
If Not bFlag Then aArrayOut(i) = vIn: i = i + 1
bFlag = False
Next
If i <> UBound(aArrayIn) Then ReDim Preserve aArrayOut(LBound(aArrayIn) To i - 1)
ArrayUnique = aArrayOut
End Function
Calling it:
Sub Test()
Dim aReturn As Variant
Dim aArray As Variant
aArray = Array(1, 2, 3, 1, 2, 3, "Test", "Test")
aReturn = ArrayUnique(aArray)
End Sub
For speed comparasion, this will be 100x to 130x faster then the dictionary solution, and about 8000x to 13000x faster than the collection one.
Pandas Merging 101
This post will go through the following topics:
- how to correctly generalize to multiple DataFrames (and why
mergehas shortcomings here) - merging on unique keys
- merging on non-unqiue keys
Generalizing to multiple DataFrames
Oftentimes, the situation arises when multiple DataFrames are to be merged together. Naively, this can be done by chaining merge calls:
df1.merge(df2, ...).merge(df3, ...)
However, this quickly gets out of hand for many DataFrames. Furthermore, it may be necessary to generalise for an unknown number of DataFrames.
Here I introduce pd.concat for multi-way joins on unique keys, and DataFrame.join for multi-way joins on non-unique keys. First, the setup.
# Setup.
np.random.seed(0)
A = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'valueA': np.random.randn(4)})
B = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'valueB': np.random.randn(4)})
C = pd.DataFrame({'key': ['D', 'E', 'J', 'C'], 'valueC': np.ones(4)})
dfs = [A, B, C]
# Note, the "key" column values are unique, so the index is unique.
A2 = A.set_index('key')
B2 = B.set_index('key')
C2 = C.set_index('key')
dfs2 = [A2, B2, C2]
Multiway merge on unique keys
If your keys (here, the key could either be a column or an index) are unique, then you can use pd.concat. Note that pd.concat joins DataFrames on the index.
# merge on `key` column, you'll need to set the index before concatenating
pd.concat([
df.set_index('key') for df in dfs], axis=1, join='inner'
).reset_index()
key valueA valueB valueC
0 D 2.240893 -0.977278 1.0
# merge on `key` index
pd.concat(dfs2, axis=1, sort=False, join='inner')
valueA valueB valueC
key
D 2.240893 -0.977278 1.0
Omit join='inner' for a FULL OUTER JOIN. Note that you cannot specify LEFT or RIGHT OUTER joins (if you need these, use join, described below).
Multiway merge on keys with duplicates
concat is fast, but has its shortcomings. It cannot handle duplicates.
A3 = pd.DataFrame({'key': ['A', 'B', 'C', 'D', 'D'], 'valueA': np.random.randn(5)})
pd.concat([df.set_index('key') for df in [A3, B, C]], axis=1, join='inner')
ValueError: Shape of passed values is (3, 4), indices imply (3, 2)
In this situation, we can use join since it can handle non-unique keys (note that join joins DataFrames on their index; it calls merge under the hood and does a LEFT OUTER JOIN unless otherwise specified).
# join on `key` column, set as the index first
# For inner join. For left join, omit the "how" argument.
A.set_index('key').join(
[df.set_index('key') for df in (B, C)], how='inner').reset_index()
key valueA valueB valueC
0 D 2.240893 -0.977278 1.0
# join on `key` index
A3.set_index('key').join([B2, C2], how='inner')
valueA valueB valueC
key
D 1.454274 -0.977278 1.0
D 0.761038 -0.977278 1.0
Continue Reading
Jump to other topics in Pandas Merging 101 to continue learning:
* you are here
How to set the margin or padding as percentage of height of parent container?
This is a very interesting bug. (In my opinion, it is a bug anyway) Nice find!
Regarding how to set it, I would recommend Camilo Martin's answer. But as to why, I'd like to explain this a bit if you guys don't mind.
In the CSS specs I found:
'padding'
Percentages: refer to width of containing block
… which is weird, but okay.
So, with a parent width: 210px and a child padding-top: 50%, I get a calculated/computed value of padding-top: 96.5px – which is not the expected 105px.
That is because in Windows (I'm not sure about other OSs), the size of common scrollbars is per default 17px × 100% (or 100% × 17px for horizontal bars). Those 17px are substracted before calculating the 50%, hence 50% of 193px = 96.5px.
How to pass parameters to the DbContext.Database.ExecuteSqlCommand method?
For entity Framework Core 2.0 or above, the correct way to do this is:
var firstName = "John";
var id = 12;
ctx.Database.ExecuteSqlCommand($"Update [User] SET FirstName = {firstName} WHERE Id = {id}";
Note that Entity Framework will produce the two parameters for you, so you are protected from Sql Injection.
Also note that it is NOT:
var firstName = "John";
var id = 12;
var sql = $"Update [User] SET FirstName = {firstName} WHERE Id = {id}";
ctx.Database.ExecuteSqlCommand(sql);
because this does NOT protect you from Sql Injection, and no parameters are produced.
See this for more.
What version of JBoss I am running?
If it helps there is also a jar-versions.xml in my JBoss installation in JBoss root folder. This doesn't require you to wget or jar xvf.
E.g.
$ grep jboss-system.jar /opt/jboss-5.1.0.GA/jar-versions.xml | fold
<jar name="jboss-system.jar" specVersion="5.1.0.GA" specVendor="JBoss (http://
www.jboss.org/)" specTitle="JBoss" implVersion="5.1.0.GA (build: SVNTag=JBoss_5_
1_0_GA date=200905221634)" implVendor="JBoss Inc." implTitle="JBoss [The Oracle]
" implVendorID="http://www.jboss.org/" implURL="http://www.jboss.org/" sealed="f
alse" md5Digest="c97e8a3dde7433b6c26d723413e17dbc"/>
$
Aligning text and image on UIButton with imageEdgeInsets and titleEdgeInsets
A small addition to Riley Avron answer to account locale changes:
extension UIButton {
func centerTextAndImage(spacing: CGFloat) {
let insetAmount = spacing / 2
let writingDirection = UIApplication.sharedApplication().userInterfaceLayoutDirection
let factor: CGFloat = writingDirection == .LeftToRight ? 1 : -1
self.imageEdgeInsets = UIEdgeInsets(top: 0, left: -insetAmount*factor, bottom: 0, right: insetAmount*factor)
self.titleEdgeInsets = UIEdgeInsets(top: 0, left: insetAmount*factor, bottom: 0, right: -insetAmount*factor)
self.contentEdgeInsets = UIEdgeInsets(top: 0, left: insetAmount, bottom: 0, right: insetAmount)
}
}
Change the Theme in Jupyter Notebook?
This is easy to do using the jupyter-themes package by Kyle Dunovan. You may be able to install it using conda. Otherwise, you will need to use pip.
Install it with conda:
conda install -c conda-forge jupyterthemes
or pip:
pip install jupyterthemes
You can get the list of available themes with:
jt -l
So change your theme with:
jt -t theme-name
To load a theme, finally, reload the page. The docs and source code are here.
Header set Access-Control-Allow-Origin in .htaccess doesn't work
Be careful on:
Header add Access-Control-Allow-Origin "*"
This is not judicious at all to grant access to everybody. It's preferable to allow a list of know trusted host only...
Header add Access-Control-Allow-Origin "http://aaa.example"
Header add Access-Control-Allow-Origin "http://bbb.example"
Header add Access-Control-Allow-Origin "http://ccc.example"
Regards,
Difference Between Schema / Database in MySQL
Depends on the database server. MySQL doesn't care, its basically the same thing.
Oracle, DB2, and other enterprise level database solutions make a distinction. Usually a schema is a collection of tables and a Database is a collection of schemas.
Session 'app': Error Launching activity
I got the same error. This issue was caused by uninstalling the app from the device (uninstalled from only 1 user)
Solved by logging into the other user and uninstall the app from there.
and it solved.
How to validate an email address using a regular expression?
A regex that does exactly what the standards say is allowed, according to what I've seen about them, is this:
/^(?!(^[.-].*|.*[.-]@|.*\.{2,}.*)|^.{254}.+@)([a-z\xC0-\xFF0-9!#$%&'*+\/=?^_`{|}~.-]+@)(?!.{253}.+$)((?!-.*|.*-\.)([a-z0-9-]{1,63}\.)+[a-z]{2,63}|(([01]?[0-9]{2}|2([0-4][0-9]|5[0-5])|[0-9])\.){3}([01]?[0-9]{2}|2([0-4][0-9]|5[0-5])|[0-9]))$/gim
Demo / Debuggex analysis (interactive)
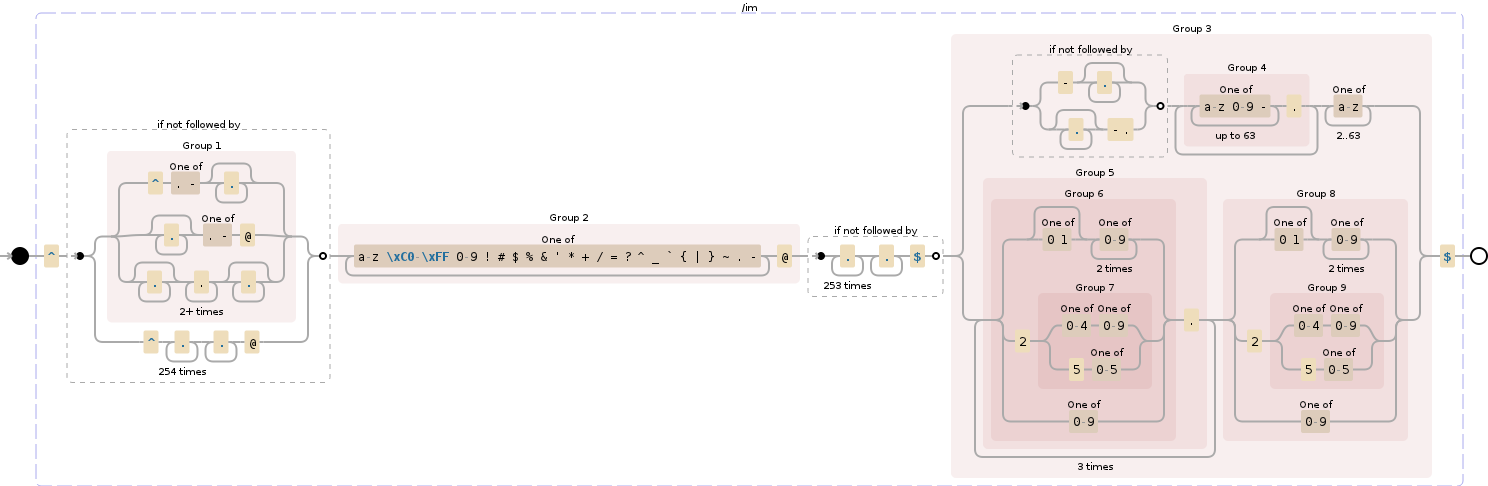{kind=link}
Split up:
^(?!(^[.-].*|.*[.-]@|.*\.{2,}.*)|^.{254}.+@)
([a-z\xC0-\xFF0-9!#$%&'*+\/=?^_`{|}~.-]+@)
(?!.{253}.+$)
(
(?!-.*|.*-\.)
([a-z0-9-]{1,63}\.)+
[a-z]{2,63}
|
(([01]?[0-9]{2}|2([0-4][0-9]|5[0-5])|[0-9])\.){3}
([01]?[0-9]{2}|2([0-4][0-9]|5[0-5])|[0-9])
)$
Analysis:
(?!(^[.-].*|.*[.-]@|.*\.{2,}.*)|^.{254}.+@)
Negative lookahead for either an address starting with a ., ending with one, having .. in it, or exceeding the 254 character max length
([a-z\xC0-\xFF0-9!#$%&'*+\/=?^_`{|}~.-]+@)
matching 1 or more of the permitted characters, with the negative look applying to it
(?!.{253}.+$)
Negative lookahead for the domain name part, restricting it to 253 characters in total
(?!-.*|.*-\.)
Negative lookahead for each of the domain names, which are don't allow starting or ending with .
([a-z0-9-]{1,63}\.)+
simple group match for the allowed characters in a domain name, which are limited to 63 characters each
[a-zA-Z]{2,63}
simple group match for the allowed top-level domain, which currently still is restricted to letters only, but does include >4 letter TLDs.
(([01]?[0-9]{2}|2([0-4][0-9]|5[0-5])|[0-9])\.){3}
([01]?[0-9]{2}|2([0-4][0-9]|5[0-5])|[0-9])
the alternative for domain names: this matches the first 3 numbers in an IP address with a . behind it, and then the fourth number in the IP address without . behind it.
Can I add color to bootstrap icons only using CSS?
Yes, if you use Font Awesome with Bootstrap! The icons are slightly different, but there are more of them, they look great at any size, and you can change the colors of them.
Basically the icons are fonts and you can change the color of them just with the CSS color property. Integration instructions are at the bottom of the page in the provided link.
Edit: Bootstrap 3.0.0 icons are now fonts!
As some other people have also mentioned with the release of Bootstrap 3.0.0, the default icon glyphs are now fonts like Font Awesome, and the color can be changed simply by changing the color CSS property. Changing the size can be done via font-size property.
Missing styles. Is the correct theme chosen for this layout?
For me, it was occurring on menu.xml file as i was using android:Theme.Light as my theme, So what i did was -
Added new Folder in res directory named values-v21.
Added android:Theme.Material.Light as AppTheme in
styles.xml.
How do I change Bootstrap 3's glyphicons to white?
You can just create your own .white class and add it to the glyphicon element.
.white, .white a {
color: #fff;
}
<i class="glyphicon glyphicon-home white"></i>
Python object deleting itself
Indeed, Python does garbage collection through reference counting. As soon as the last reference to an object falls out of scope, it is deleted. In your example:
a = A()
a.kill()
I don't believe there's any way for variable 'a' to implicitly set itself to None.
How to convert a Scikit-learn dataset to a Pandas dataset?
Basically what you need is the "data", and you have it in the scikit bunch, now you need just the "target" (prediction) which is also in the bunch.
So just need to concat these two to make the data complete
data_df = pd.DataFrame(cancer.data,columns=cancer.feature_names)
target_df = pd.DataFrame(cancer.target,columns=['target'])
final_df = data_df.join(target_df)
When is the finalize() method called in Java?
An Object becomes eligible for Garbage collection or GC if its not reachable from any live threads or any static refrences in other words you can say that an object becomes eligible for garbage collection if its all references are null. Cyclic dependencies are not counted as reference so if Object A has reference of object B and object B has reference of Object A and they don't have any other live reference then both Objects A and B will be eligible for Garbage collection. Generally an object becomes eligible for garbage collection in Java on following cases:
- All references of that object explicitly set to null e.g. object = null
- Object is created inside a block and reference goes out scope once control exit that block.
- Parent object set to null, if an object holds reference of another object and when you set container object's reference null, child or contained object automatically becomes eligible for garbage collection.
- If an object has only live references via WeakHashMap it will be eligible for garbage collection.
How to disable or enable viewpager swiping in android
Best solution for me. -First, you create a class like this:
public class CustomViewPager extends ViewPager {
private Boolean disable = false;
public CustomViewPager(Context context) {
super(context);
}
public CustomViewPager(Context context, AttributeSet attrs){
super(context,attrs);
}
@Override
public boolean onInterceptTouchEvent(MotionEvent event) {
return !disable && super.onInterceptTouchEvent(event);
}
@Override
public boolean onTouchEvent(MotionEvent event) {
return !disable && super.onTouchEvent(event);
}
public void disableScroll(Boolean disable){
//When disable = true not work the scroll and when disble = false work the scroll
this.disable = disable;
}
}
-Then change this in your layout:<android.support.v4.view.ViewPager
for this<com.mypackage.CustomViewPager
-Finally, you can disable it:view_pager.disableScroll(true);
or enable it: view_pager.disableScroll(false);
I hope that this help you :)
How do I remove/delete a folder that is not empty?
With os.walk I would propose the solution which consists of 3 one-liner Python calls:
python -c "import sys; import os; [os.chmod(os.path.join(rs,d), 0o777) for rs,ds,fs in os.walk(_path_) for d in ds]"
python -c "import sys; import os; [os.chmod(os.path.join(rs,f), 0o777) for rs,ds,fs in os.walk(_path_) for f in fs]"
python -c "import os; import shutil; shutil.rmtree(_path_, ignore_errors=False)"
The first script chmod's all sub-directories, the second script chmod's all files. Then the third script removes everything with no impediments.
I have tested this from the "Shell Script" in a Jenkins job (I did not want to store a new Python script into SCM, that's why searched for a one-line solution) and it worked for Linux and Windows.
Easy way to build Android UI?
I found that using the http://pencil.evolus.vn/ together with the pencil-stencils from the http://code.google.com/p/android-ui-utils/ project works exceptionally well. Very simple to use, its very easy to mock up elaborate designs
Remove a modified file from pull request
Removing a file from pull request but not from your local repository.
- Go to your branch from where you created the request use the following commands
git checkout -- c:\temp..... next git checkout origin/master -- c:\temp... u replace origin/master with any other branch. Next git commit -m c:\temp..... Next git push origin
Note : no single quote or double quotes for the filepath
How to get all files under a specific directory in MATLAB?
You're looking for dir to return the directory contents.
To loop over the results, you can simply do the following:
dirlist = dir('.');
for i = 1:length(dirlist)
dirlist(i)
end
This should give you output in the following format, e.g.:
name: 'my_file'
date: '01-Jan-2010 12:00:00'
bytes: 56
isdir: 0
datenum: []
Subtracting two lists in Python
Here's a relatively long but efficient and readable solution. It's O(n).
def list_diff(list1, list2):
counts = {}
for x in list1:
try:
counts[x] += 1
except:
counts[x] = 1
for x in list2:
try:
counts[x] -= 1
if counts[x] < 0:
raise ValueError('All elements of list2 not in list2')
except:
raise ValueError('All elements of list2 not in list1')
result = []
for k, v in counts.iteritems():
result += v*[k]
return result
a = [0, 1, 1, 2, 0]
b = [0, 1, 1]
%timeit list_diff(a, b)
%timeit list_diff(1000*a, 1000*b)
%timeit list_diff(1000000*a, 1000000*b)
100000 loops, best of 3: 4.8 µs per loop
1000 loops, best of 3: 1.18 ms per loop
1 loops, best of 3: 1.21 s per loop
JavaScript post request like a form submit
This works perfectly in my case:
document.getElementById("form1").submit();
You can use it in function like:
function formSubmit() {
document.getElementById("frmUserList").submit();
}
Using this you can post all the values of inputs.
Why am I getting an error "Object literal may only specify known properties"?
As of TypeScript 1.6, properties in object literals that do not have a corresponding property in the type they're being assigned to are flagged as errors.
Usually this error means you have a bug (typically a typo) in your code, or in the definition file. The right fix in this case would be to fix the typo. In the question, the property callbackOnLoactionHash is incorrect and should have been callbackOnLocationHash (note the mis-spelling of "Location").
This change also required some updates in definition files, so you should get the latest version of the .d.ts for any libraries you're using.
Example:
interface TextOptions {
alignment?: string;
color?: string;
padding?: number;
}
function drawText(opts: TextOptions) { ... }
drawText({ align: 'center' }); // Error, no property 'align' in 'TextOptions'
But I meant to do that
There are a few cases where you may have intended to have extra properties in your object. Depending on what you're doing, there are several appropriate fixes
Type-checking only some properties
Sometimes you want to make sure a few things are present and of the correct type, but intend to have extra properties for whatever reason. Type assertions (<T>v or v as T) do not check for extra properties, so you can use them in place of a type annotation:
interface Options {
x?: string;
y?: number;
}
// Error, no property 'z' in 'Options'
let q1: Options = { x: 'foo', y: 32, z: 100 };
// OK
let q2 = { x: 'foo', y: 32, z: 100 } as Options;
// Still an error (good):
let q3 = { x: 100, y: 32, z: 100 } as Options;
These properties and maybe more
Some APIs take an object and dynamically iterate over its keys, but have 'special' keys that need to be of a certain type. Adding a string indexer to the type will disable extra property checking
Before
interface Model {
name: string;
}
function createModel(x: Model) { ... }
// Error
createModel({name: 'hello', length: 100});
After
interface Model {
name: string;
[others: string]: any;
}
function createModel(x: Model) { ... }
// OK
createModel({name: 'hello', length: 100});
This is a dog or a cat or a horse, not sure yet
interface Animal { move; }
interface Dog extends Animal { woof; }
interface Cat extends Animal { meow; }
interface Horse extends Animal { neigh; }
let x: Animal;
if(...) {
x = { move: 'doggy paddle', woof: 'bark' };
} else if(...) {
x = { move: 'catwalk', meow: 'mrar' };
} else {
x = { move: 'gallop', neigh: 'wilbur' };
}
Two good solutions come to mind here
Specify a closed set for x
// Removes all errors
let x: Dog|Cat|Horse;
or Type assert each thing
// For each initialization
x = { move: 'doggy paddle', woof: 'bark' } as Dog;
This type is sometimes open and sometimes not
A clean solution to the "data model" problem using intersection types:
interface DataModelOptions {
name?: string;
id?: number;
}
interface UserProperties {
[key: string]: any;
}
function createDataModel(model: DataModelOptions & UserProperties) {
/* ... */
}
// findDataModel can only look up by name or id
function findDataModel(model: DataModelOptions) {
/* ... */
}
// OK
createDataModel({name: 'my model', favoriteAnimal: 'cat' });
// Error, 'ID' is not correct (should be 'id')
findDataModel({ ID: 32 });
See also https://github.com/Microsoft/TypeScript/issues/3755
Add UIPickerView & a Button in Action sheet - How?
To add to marcio's awesome solution, dismissActionSheet: can be implemented as follows.
- Add an ActionSheet object to your .h file, synthesize it and reference it in your .m file.
Add this method to your code.
- (void)dismissActionSheet:(id)sender{ [_actionSheet dismissWithClickedButtonIndex:0 animated:YES]; [_myButton setTitle:@"new title"]; //set to selected text if wanted }
nginx - client_max_body_size has no effect
I'm setting up a dev server to play with that mirrors our outdated live one, I used The Perfect Server - Ubuntu 14.04 (nginx, BIND, MySQL, PHP, Postfix, Dovecot and ISPConfig 3)
After experiencing the same issue, I came across this post and nothing was working. I changed the value in every recommended file (nginx.conf, ispconfig.vhost, /sites-available/default, etc.)
Finally, changing client_max_body_size in my /etc/nginx/sites-available/apps.vhost and restarting nginx is what did the trick. Hopefully it helps someone else.
Getting HTTP code in PHP using curl
Here is my solution need get Status Http for checking status of server regularly
$url = 'http://www.example.com'; // Your server link
while(true) {
$strHeader = get_headers($url)[0];
$statusCode = substr($strHeader, 9, 3 );
if($statusCode != 200 ) {
echo 'Server down.';
// Send email
}
else {
echo 'oK';
}
sleep(30);
}
Pointer to class data member "::*"
One way I've used it is if I have two implementations of how to do something in a class and I want to choose one at run-time without having to continually go through an if statement i.e.
class Algorithm
{
public:
Algorithm() : m_impFn( &Algorithm::implementationA ) {}
void frequentlyCalled()
{
// Avoid if ( using A ) else if ( using B ) type of thing
(this->*m_impFn)();
}
private:
void implementationA() { /*...*/ }
void implementationB() { /*...*/ }
typedef void ( Algorithm::*IMP_FN ) ();
IMP_FN m_impFn;
};
Obviously this is only practically useful if you feel the code is being hammered enough that the if statement is slowing things done eg. deep in the guts of some intensive algorithm somewhere. I still think it's more elegant than the if statement even in situations where it has no practical use but that's just my opnion.
Why am I suddenly getting a "Blocked loading mixed active content" issue in Firefox?
In the relevant page which makes a mixed content https to http call which is not accessible we can add the following entry in the relevant and get rid of the mixed content error.
<meta http-equiv="Content-Security-Policy" content="upgrade-insecure-requests">
How can I embed a YouTube video on GitHub wiki pages?
It's not possible to embed videos directly, but you can put an image which links to a YouTube video:
[](https://www.youtube.com/watch?v=YOUTUBE_VIDEO_ID_HERE)
- For more information about Markdown look at this Markdown cheatsheet on GitHub.
- For more information about Youtube image links look this question.
ValueError: could not broadcast input array from shape (224,224,3) into shape (224,224)
I was facing the same problem because some of the images are grey scale images in my data set, so i solve my problem by doing this
from PIL import Image
img = Image.open('my_image.jpg').convert('RGB')
# a line from my program
positive_images_array = np.array([np.array(Image.open(img).convert('RGB').resize((150, 150), Image.ANTIALIAS)) for img in images_in_yes_directory])
Can't specify the 'async' modifier on the 'Main' method of a console app
To avoid freezing when you call a function somewhere down the call stack that tries to re-join the current thread (which is stuck in a Wait), you need to do the following:
class Program
{
static void Main(string[] args)
{
Bootstrapper bs = new Bootstrapper();
List<TvChannel> list = Task.Run((Func<Task<List<TvChannel>>>)bs.GetList).Result;
}
}
(the cast is only required to resolve ambiguity)
Excel column number from column name
In my opinion the simpliest way to get column number is:
Sub Sample()
ColName = ActiveCell.Column
MsgBox ColName
End Sub
Maven home (M2_HOME) not being picked up by IntelliJ IDEA
If M2_HOME is configured to point to the Maven home directory then:
- Go to
File -> Settings - Search for
Maven - Select
Runner Insert in the field
VM Optionsthe following string:Dmaven.multiModuleProjectDirectory=$M2_HOME
Click Apply and OK
How to avoid .pyc files?
As far as I know python will compile all modules you "import". However python will NOT compile a python script run using: "python script.py" (it will however compile any modules that the script imports).
The real questions is why you don't want python to compile the modules? You could probably automate a way of cleaning these up if they are getting in the way.
Bulk Insert Correctly Quoted CSV File in SQL Server
I've spent half a day on this problem. It's best to import using SQL Server Import & Export data wizard. There is a setting in that wizard which solves this problem. Detailed screenshots here: https://www.mssqltips.com/sqlservertip/1316/strip-double-quotes-from-an-import-file-in-integration-services-ssis/ Thanks
how to align all my li on one line?
I think the NOBR tag might be overkill, and as you said, unreliable.
There are 2 options available depending on how you are displaying the text.
If you are displaying text in a table cell you would do Long Text Here. If you are using a div or a span, you can use the style="white-space: nowrap;"
How can I force users to access my page over HTTPS instead of HTTP?
The PHP way:
$is_https=false;
if (isset($_SERVER['HTTPS'])) $is_https=$_SERVER['HTTPS'];
if ($is_https !== "on")
{
header("Location: https://".$_SERVER['HTTP_HOST'].$_SERVER['REQUEST_URI']);
exit(1);
}
The Apache mod_rewrite way:
RewriteCond %{HTTPS} !=on
RewriteRule ^ https://%{HTTP_HOST}%{REQUEST_URI} [L,R=301]
Statically rotate font-awesome icons
This works perfectly
<i class="fa fa-power-off text-gray" style="transform: rotate(90deg);"></i>
How to put space character into a string name in XML?
xml:space="preserve"
Works like a charm.
Edit: Wrong. Actually, it only works when the content is comprised of white spaces only.
Assigning out/ref parameters in Moq
I'm sure Scott's solution worked at one point,
But it's a good argument for not using reflection to peek at private apis. It's broken now.
I was able to set out parameters using a delegate
delegate void MockOutDelegate(string s, out int value);
public void SomeMethod()
{
....
int value;
myMock.Setup(x => x.TryDoSomething(It.IsAny<string>(), out value))
.Callback(new MockOutDelegate((string s, out int output) => output = userId))
.Returns(true);
}
Delete last N characters from field in a SQL Server database
UPDATE mytable SET column=LEFT(column, LEN(column)-5)
Removes the last 5 characters from the column (every row in mytable)
mvn clean install vs. deploy vs. release
The clean, install and deploy phases are valid lifecycle phases and invoking them will trigger all the phases preceding them, and the goals bound to these phases.
mvn clean install
This command invokes the clean phase and then the install phase sequentially:
clean: removes files generated at build-time in a project's directory (targetby default)install: installs the package into the local repository, for use as a dependency in other projects locally.
mvn deploy
This command invokes the deploy phase:
deploy: copies the final package to the remote repository for sharing with other developers and projects.
mvn release
This is not a valid phase nor a goal so this won't do anything. But if refers to the Maven Release Plugin that is used to automate release management. Releasing a project is done in two steps: prepare and perform. As documented:
Preparing a release goes through the following release phases:
- Check that there are no uncommitted changes in the sources
- Check that there are no SNAPSHOT dependencies
- Change the version in the POMs from x-SNAPSHOT to a new version (you will be prompted for the versions to use)
- Transform the SCM information in the POM to include the final destination of the tag
- Run the project tests against the modified POMs to confirm everything is in working order
- Commit the modified POMs
- Tag the code in the SCM with a version name (this will be prompted for)
- Bump the version in the POMs to a new value y-SNAPSHOT (these values will also be prompted for)
- Commit the modified POMs
And then:
Performing a release runs the following release phases:
- Checkout from an SCM URL with optional tag
- Run the predefined Maven goals to release the project (by default, deploy site-deploy)
See also
How to write data to a JSON file using Javascript
Unfortunatelly, today (September 2018) you can not find cross-browser solution for client side file writing.
For example: in some browser like a Chrome we have today this possibility and we can write with FileSystemFileEntry.createWriter() with client side call, but according to the docu:
This feature is obsolete. Although it may still work in some browsers, its use is discouraged since it could be removed at any time. Try to avoid using it.
For IE (but not MS Edge) we could use ActiveX too, but this is only for this client.
If you want update your JSON file cross-browser you have to use server and client side together.
The client side script
On client side you can make a request to the server and then you have to read the response from server. Or you could read a file with FileReader too. For the cross-browser writing to the file you have to have some server (see below on server part).
var xhr = new XMLHttpRequest(),
jsonArr,
method = "GET",
jsonRequestURL = "SOME_PATH/jsonFile/";
xhr.open(method, jsonRequestURL, true);
xhr.onreadystatechange = function()
{
if(xhr.readyState == 4 && xhr.status == 200)
{
// we convert your JSON into JavaScript object
jsonArr = JSON.parse(xhr.responseText);
// we add new value:
jsonArr.push({"nissan": "sentra", "color": "green"});
// we send with new request the updated JSON file to the server:
xhr.open("POST", jsonRequestURL, true);
xhr.setRequestHeader("Content-Type", "application/x-www-form-urlencoded");
// if you want to handle the POST response write (in this case you do not need it):
// xhr.onreadystatechange = function(){ /* handle POST response */ };
xhr.send("jsonTxt="+JSON.stringify(jsonArr));
// but on this place you have to have a server for write updated JSON to the file
}
};
xhr.send(null);
Server side scripts
You can use a lot of different servers, but I would like to write about PHP and Node.js servers.
By using searching machine you could find "free PHP Web Hosting*" or "free Node.js Web Hosting". For PHP server I would recommend 000webhost.com and for Node.js I would recommend to see and to read this list.
PHP server side script solution
The PHP script for reading and writing from JSON file:
<?php
// This PHP script must be in "SOME_PATH/jsonFile/index.php"
$file = 'jsonFile.txt';
if($_SERVER['REQUEST_METHOD'] === 'POST')
// or if(!empty($_POST))
{
file_put_contents($file, $_POST["jsonTxt"]);
//may be some error handeling if you want
}
else if($_SERVER['REQUEST_METHOD'] === 'GET')
// or else if(!empty($_GET))
{
echo file_get_contents($file);
//may be some error handeling if you want
}
?>
Node.js server side script solution
I think that Node.js is a little bit complex for beginner. This is not normal JavaScript like in browser. Before you start with Node.js I would recommend to read one from two books:
The Node.js script for reading and writing from JSON file:
var http = require("http"),
fs = require("fs"),
port = 8080,
pathToJSONFile = '/SOME_PATH/jsonFile.txt';
http.createServer(function(request, response)
{
if(request.method == 'GET')
{
response.writeHead(200, {"Content-Type": "application/json"});
response.write(fs.readFile(pathToJSONFile, 'utf8'));
response.end();
}
else if(request.method == 'POST')
{
var body = [];
request.on('data', function(chunk)
{
body.push(chunk);
});
request.on('end', function()
{
body = Buffer.concat(body).toString();
var myJSONdata = body.split("=")[1];
fs.writeFileSync(pathToJSONFile, myJSONdata); //default: 'utf8'
});
}
}).listen(port);
Related links for Node.js:
Create an Android GPS tracking application
The source code for the Android mobile application open-gpstracker which you appreciated is available here.
You can checkout the code using SVN client application or via Git:
- svn checkout http://open-gpstracker.googlecode.com/svn/trunk/ open-gpstracker-read-only
- git clone https://code.google.com/p/open-gpstracker/
Debugging the source code will surely help you.
Relative frequencies / proportions with dplyr
Here is a general function implementing Henrik's solution on dplyr 0.7.1.
freq_table <- function(x,
group_var,
prop_var) {
group_var <- enquo(group_var)
prop_var <- enquo(prop_var)
x %>%
group_by(!!group_var, !!prop_var) %>%
summarise(n = n()) %>%
mutate(freq = n /sum(n)) %>%
ungroup
}
C99 stdint.h header and MS Visual Studio
Visual Studio 2003 - 2008 (Visual C++ 7.1 - 9) don't claim to be C99 compatible. (Thanks to rdentato for his comment.)
How to download and save a file from Internet using Java?
1st Method using the new channel
ReadableByteChannel aq = Channels.newChannel(new url("https//asd/abc.txt").openStream());
FileOutputStream fileOS = new FileOutputStream("C:Users/local/abc.txt")
FileChannel writech = fileOS.getChannel();
2nd Method using FileUtils
FileUtils.copyURLToFile(new url("https//asd/abc.txt",new local file on system("C":/Users/system/abc.txt"));
3rd Method using
InputStream xy = new ("https//asd/abc.txt").openStream();
This is how we can download file by using basic java code and other third-party libraries. These are just for quick reference. Please google with the above keywords to get detailed information and other options.
How to include "zero" / "0" results in COUNT aggregate?
You want an outer join for this (and you need to use person as the "driving" table)
SELECT person.person_id, COUNT(appointment.person_id) AS "number_of_appointments"
FROM person
LEFT JOIN appointment ON person.person_id = appointment.person_id
GROUP BY person.person_id;
The reason why this is working, is that the outer (left) join will return NULL for those persons that do not have an appointment. The aggregate function count() will not count NULL values and thus you'll get a zero.
If you want to learn more about outer joins, here is a nice tutorial: http://sqlzoo.net/wiki/Using_Null
Select element by exact match of its content
No, there's no jQuery (or CSS) selector that does that.
You can readily use filter:
$("p").filter(function() {
return $(this).text() === "hello";
}).css("font-weight", "bold");
It's not a selector, but it does the job. :-)
If you want to handle whitespace before or after the "hello", you might throw a $.trim in there:
return $.trim($(this).text()) === "hello";
For the premature optimizers out there, if you don't care that it doesn't match <p><span>hello</span></p> and similar, you can avoid the calls to $ and text by using innerHTML directly:
return this.innerHTML === "hello";
...but you'd have to have a lot of paragraphs for it to matter, so many that you'd probably have other issues first. :-)
Scope 'session' is not active for the current thread; IllegalStateException: No thread-bound request found
You just need to define in your bean where you need a different scope than default singleton scope except prototype. For example:
<bean id="shoppingCart"
class="com.xxxxx.xxxx.ShoppingCartBean" scope="session">
<aop:scoped-proxy/>
</bean>
"std::endl" vs "\n"
I've always had a habit of just using std::endl because it is easy for me to see.
Parsing JSON using Json.net
Edit: Thanks Marc, read up on the struct vs class issue and you're right, thank you!
I tend to use the following method for doing what you describe, using a static method of JSon.Net:
MyObject deserializedObject = JsonConvert.DeserializeObject<MyObject>(json);
Link: Serializing and Deserializing JSON with Json.NET
For the Objects list, may I suggest using generic lists out made out of your own small class containing attributes and position class. You can use the Point struct in System.Drawing (System.Drawing.Point or System.Drawing.PointF for floating point numbers) for you X and Y.
After object creation it's much easier to get the data you're after vs. the text parsing you're otherwise looking at.
Java SecurityException: signer information does not match
This also happens if you include one file with different names or from different locations twice, especially if these are two different versions of the same file.
How can we convert an integer to string in AngularJs
.toString() is available, or just add "" to the end of the int
var x = 3,
toString = x.toString(),
toConcat = x + "";
Angular is simply JavaScript at the core.
What is the difference between a string and a byte string?
Assuming Python 3 (in Python 2, this difference is a little less well-defined) - a string is a sequence of characters, ie unicode codepoints; these are an abstract concept, and can't be directly stored on disk. A byte string is a sequence of, unsurprisingly, bytes - things that can be stored on disk. The mapping between them is an encoding - there are quite a lot of these (and infinitely many are possible) - and you need to know which applies in the particular case in order to do the conversion, since a different encoding may map the same bytes to a different string:
>>> b'\xcf\x84o\xcf\x81\xce\xbdo\xcf\x82'.decode('utf-16')
'?????'
>>> b'\xcf\x84o\xcf\x81\xce\xbdo\xcf\x82'.decode('utf-8')
'to??o?'
Once you know which one to use, you can use the .decode() method of the byte string to get the right character string from it as above. For completeness, the .encode() method of a character string goes the opposite way:
>>> 'to??o?'.encode('utf-8')
b'\xcf\x84o\xcf\x81\xce\xbdo\xcf\x82'
Bootstrap - Removing padding or margin when screen size is smaller
The problem here is much more complex than removing the container padding since the grid structure relies on this padding when applying negative margins for the enclosed rows.
Removing the container padding in this case will cause an x-axis overflow caused by all the rows inside of this container class, this is one of the most stupid things about the Bootstrap Grid.
Logically it should be approached by
- Never using the
.containerclass for anything other than rows - Make a clone of the
.containerclass that has no padding for use with non-grid html - For removing the
.containerpadding on mobile you can manually remove it with media queries thenoverflow-x: hidden;which is not very reliable but works in most cases.
If you are using LESS the end result will look like this
@media (max-width: @screen-md-max) {
.container{
padding: 0;
overflow-x: hidden;
}
}
Change the media query to whatever size you want to target.
Final thoughts, I would highly recommend using the Foundation Framework Grid as its way more advanced
How to Auto resize HTML table cell to fit the text size
If you want the cells to resize depending on the content, then you must not specify a width to the table, the rows, or the cells.
If you don't want word wrap, assign the CSS style white-space: nowrap to the cells.
Generate a sequence of numbers in Python
Includes some guessing on the exact sequence you are expecting:
>>> l = list(range(1, 100, 4)) + list(range(2, 100, 4))
>>> l.sort()
>>> ','.join(map(str, l))
'1,2,5,6,9,10,13,14,17,18,21,22,25,26,29,30,33,34,37,38,41,42,45,46,49,50,53,54,57,58,61,62,65,66,69,70,73,74,77,78,81,82,85,86,89,90,93,94,97,98'
As one-liner:
>>> ','.join(map(str, sorted(list(range(1, 100, 4))) + list(range(2, 100, 4))))
(btw. this is Python 3 compatible)
Can dplyr join on multiple columns or composite key?
Updating to use tibble()
You can pass a named vector of length greater than 1 to the by argument of left_join():
library(dplyr)
d1 <- tibble(
x = letters[1:3],
y = LETTERS[1:3],
a = rnorm(3)
)
d2 <- tibble(
x2 = letters[3:1],
y2 = LETTERS[3:1],
b = rnorm(3)
)
left_join(d1, d2, by = c("x" = "x2", "y" = "y2"))
Python: can't assign to literal
I got the same error: SyntaxError: can't assign to literal when I was trying to assign multiple variables in a single line.
I was assigning the values as shown below:
score = 0, isDuplicate = None
When I shifted them to another line, it got resolved:
score = 0
isDuplicate = None
I don't know why python does not allow multiple assignments at the same line but that's how it is done.
There is one more way to asisgn it in single line ie. Separate them with a semicolon in place of comma. Check the code below:
score = 0 ; duplicate = None
How to read a single character from the user?
The ActiveState's recipe seems to contain a little bug for "posix" systems that prevents Ctrl-C from interrupting (I'm using Mac). If I put the following code in my script:
while(True):
print(getch())
I will never be able to terminate the script with Ctrl-C, and I have to kill my terminal to escape.
I believe the following line is the cause, and it's also too brutal:
tty.setraw(sys.stdin.fileno())
Asides from that, package tty is not really needed, termios is enough to handle it.
Below is the improved code that works for me (Ctrl-C will interrupt), with the extra getche function that echo the char as you type:
if sys.platform == 'win32':
import msvcrt
getch = msvcrt.getch
getche = msvcrt.getche
else:
import sys
import termios
def __gen_ch_getter(echo):
def __fun():
fd = sys.stdin.fileno()
oldattr = termios.tcgetattr(fd)
newattr = oldattr[:]
try:
if echo:
# disable ctrl character printing, otherwise, backspace will be printed as "^?"
lflag = ~(termios.ICANON | termios.ECHOCTL)
else:
lflag = ~(termios.ICANON | termios.ECHO)
newattr[3] &= lflag
termios.tcsetattr(fd, termios.TCSADRAIN, newattr)
ch = sys.stdin.read(1)
if echo and ord(ch) == 127: # backspace
# emulate backspace erasing
# https://stackoverflow.com/a/47962872/404271
sys.stdout.write('\b \b')
finally:
termios.tcsetattr(fd, termios.TCSADRAIN, oldattr)
return ch
return __fun
getch = __gen_ch_getter(False)
getche = __gen_ch_getter(True)
References:
ARM compilation error, VFP registers used by executable, not object file
I was facing the same issue. I was trying to build linux application for Cyclone V FPGA-SoC. I faced the problem as below:
Error: <application_name> uses VFP register arguments, main.o does not
I was using the toolchain arm-linux-gnueabihf-g++ provided by embedded software design tool of altera.
It is solved by exporting:
mfloat-abi=hard to flags, then arm-linux-gnueabihf-g++ compiles without errors. Also include the flags in both CC & LD.
Remove all special characters with RegExp
The first solution does not work for any UTF-8 alphabet. (It will cut text such as ????). I have managed to create a function which does not use RegExp and use good UTF-8 support in the JavaScript engine. The idea is simple if a symbol is equal in uppercase and lowercase it is a special character. The only exception is made for whitespace.
function removeSpecials(str) {
var lower = str.toLowerCase();
var upper = str.toUpperCase();
var res = "";
for(var i=0; i<lower.length; ++i) {
if(lower[i] != upper[i] || lower[i].trim() === '')
res += str[i];
}
return res;
}
Update: Please note, that this solution works only for languages where there are small and capital letters. In languages like Chinese, this won't work.
Update 2: I came to the original solution when I was working on a fuzzy search. If you also trying to remove special characters to implement search functionality, there is a better approach. Use any transliteration library which will produce you string only from Latin characters and then the simple Regexp will do all magic of removing special characters. (This will work for Chinese also and you also will receive side benefits by making Tromsø == Tromso).
How to run a C# application at Windows startup?
I did not find any of the above code worked. Maybe that's because my app is running .NET 3.5. I don't know. The following code worked perfectly for me. I got this from a senior level .NET app developer on my team.
Write(Microsoft.Win32.Registry.LocalMachine, @"SOFTWARE\Microsoft\Windows\CurrentVersion\Run\", "WordWatcher", "\"" + Application.ExecutablePath.ToString() + "\"");
public bool Write(RegistryKey baseKey, string keyPath, string KeyName, object Value)
{
try
{
// Setting
RegistryKey rk = baseKey;
// I have to use CreateSubKey
// (create or open it if already exits),
// 'cause OpenSubKey open a subKey as read-only
RegistryKey sk1 = rk.CreateSubKey(keyPath);
// Save the value
sk1.SetValue(KeyName.ToUpper(), Value);
return true;
}
catch (Exception e)
{
// an error!
MessageBox.Show(e.Message, "Writing registry " + KeyName.ToUpper());
return false;
}
}
creating Hashmap from a JSON String
This worked for me:
JSONObject jsonObj = new JSONObject();
jsonObj.put("phonetype","N95");
jsonObj.put("cat","WP");
jsonObj to Hashmap as following using gson
HashMap<String, Object> hashmap = new Gson().fromJson(jsonObj.toString(), HashMap.class);
package used
<dependencies>
<dependency>
<groupId>org.json</groupId>
<artifactId>json</artifactId>
<version>20180813</version>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.6</version>
</dependency>
</dependencies>
How can I find the last element in a List<>?
In C# 8.0 you can get the last item with ^ operator full explanation
List<char> list = ...;
var value = list[^1];
// Gets translated to
var value = list[list.Count - 1];
Create an empty list in python with certain size
I'm a bit surprised that the easiest way to create an initialised list is not in any of these answers. Just use a generator in the list function:
list(range(9))
How to find an available port?
If your server starts up, then that socket was not used.
EDIT
Something like:
ServerSocket s = null ;
try {
s = new ServerSocket( 0 );
} catch( IOException ioe ){
for( int i = START; i < END ; i++ ) try {
s = new ServerSocket( i );
} catch( IOException ioe ){}
}
// At this point if s is null we are helpless
if( s == null ) {
throw new IOException(
Strings.format("Unable to open server in port range(%d-%d)",START,END));
}
Difference between "move" and "li" in MIPS assembly language
The move instruction copies a value from one register to another. The li instruction loads a specific numeric value into that register.
For the specific case of zero, you can use either the constant zero or the zero register to get that:
move $s0, $zero
li $s0, 0
There's no register that generates a value other than zero, though, so you'd have to use li if you wanted some other number, like:
li $s0, 12345678
OTP (token) should be automatically read from the message
I implemented something of that such. But, here is what I did when the message comes in, I retrieve only the six digit code, bundle it in an intent and send it to the activity or fragment needing it and verifies the code. The example shows you the way to get the sms already. Look at the code below for illustration on how to send using LocalBrodcastManager and if your message contains more texts E.g Greetings, standardize it to help you better. E.g "Your verification code is: 84HG73" you can create a regex pattern like this ([0-9]){2}([A-Z]){2}([0-9]){2} which means two ints, two [capital] letters and two ints. Good Luck!
After discarding all un needed info from the message
Intent intent = new Intent("AddedItem");
intent.putExtra("items", code);
LocalBroadcastManager.getInstance(getActivity()).sendBroadcast(intent);
And the Fragment/Activity receiving it
@Override
public void onResume() {
LocalBroadcastManager.getInstance(getActivity()).registerReceiver(receiver, new IntentFilter("AddedItem"));
super.onResume();
}
@Override
public void onPause() {
super.onDestroy();
LocalBroadcastManager.getInstance(getActivity()).unregisterReceiver(receiver);
}
And the code meant to handle the payload you collected
private BroadcastReceiver receiver = new BroadcastReceiver() {
@Override
public void onReceive(Context context, Intent intent) {
if (intent.getAction()) {
final String message = intent.getStringExtra("message");
//Do whatever you want with the code here
}
}
};
Does that help a little bit. I did it better by using Callbacks
how to open a url in python
On window
import os
os.system("start \"\" https://example.com")
On macOS
import os
os.system("open \"\" https://example.com")
On Linux
import os
os.system("xdg-open \"\" https://example.com")
Cross-Platform
import webbrowser
webbrowser.open('https://example.com')
Display PDF file inside my android application
This is the perfect solution that worked for me without any 3rd party library.
Rendering a PDF Document in Android Activity/Fragment (Using PdfRenderer)
Where is body in a nodejs http.get response?
I also want to add that the http.ClientResponse returned by http.get() has an end event, so here is another way that I receive the body response:
var options = {
host: 'www.google.com',
port: 80,
path: '/index.html'
};
http.get(options, function(res) {
var body = '';
res.on('data', function(chunk) {
body += chunk;
});
res.on('end', function() {
console.log(body);
});
}).on('error', function(e) {
console.log("Got error: " + e.message);
});
Where do I configure log4j in a JUnit test class?
I use system properties in log4j.xml:
...
<param name="File" value="${catalina.home}/logs/root.log"/>
...
and start tests with:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.16</version>
<configuration>
<systemProperties>
<property>
<name>catalina.home</name>
<value>${project.build.directory}</value>
</property>
</systemProperties>
</configuration>
</plugin>
Using :: in C++
The :: is called scope resolution operator.
Can be used like this:
:: identifier
class-name :: identifier
namespace :: identifier
You can read about it here
https://docs.microsoft.com/en-us/cpp/cpp/scope-resolution-operator?view=vs-2017
How to create Windows EventLog source from command line?
you can create your own custom event by using diagnostics.Event log class. Open a windows application and on a button click do the following code.
System.Diagnostics.EventLog.CreateEventSource("ApplicationName", "MyNewLog");
"MyNewLog" means the name you want to give to your log in event viewer.
for more information check this link [ http://msdn.microsoft.com/en-in/library/49dwckkz%28v=vs.90%29.aspx]
batch file to list folders within a folder to one level
Dir
Use the dir command. Type in dir /? for help and options.
dir /a:d /b
Redirect
Then use a redirect to save the list to a file.
> list.txt
Together
dir /a:d /b > list.txt
This will output just the names of the directories. if you want the full path of the directories use this below.
Full Path
for /f "delims=" %%D in ('dir /a:d /b') do echo %%~fD
Alternative
other method just using the for command. See for /? for help and options. This can output just the name %%~nxD or the full path %%~fD
for /d %%D in (*) do echo %%~fD
Notes
To use these commands directly on the command line, change the double percent signs to single percent signs. %% to %
To redirect the for methods, just add the redirect after the echo statements. Use the double arrow >> redirect here to append to the file, else only the last statement will be written to the file due to overwriting all the others.
... echo %%~fD>> list.txt
How to use Apple's new .p8 certificate for APNs in firebase console
You can create the .p8 file for it in https://developer.apple.com/account/
Then go to Certificates, Identifiers & Profiles > Keys > add
Select Apple Push Notification service (APNs), put a Key Name (whatever).
Then click on "continue", after "register" and you get it and you can download it.
Is there a "theirs" version of "git merge -s ours"?
A simple and intuitive (in my opinion) two-step way of doing it is
git checkout branchB .
git commit -m "Picked up the content from branchB"
followed by
git merge -s ours branchB
(which marks the two branches as merged)
The only disadvantage is that it does not remove files which have been deleted in branchB from your current branch. A simple diff between the two branches afterwards will show if there are any such files.
This approach also makes it clear from the revision log afterwards what was done - and what was intended.
Iterating through a variable length array
here is an example, where the length of the array is changed during execution of the loop
import java.util.ArrayList;
public class VariableArrayLengthLoop {
public static void main(String[] args) {
//create new ArrayList
ArrayList<String> aListFruits = new ArrayList<String>();
//add objects to ArrayList
aListFruits.add("Apple");
aListFruits.add("Banana");
aListFruits.add("Orange");
aListFruits.add("Strawberry");
//iterate ArrayList using for loop
for(int i = 0; i < aListFruits.size(); i++){
System.out.println( aListFruits.get(i) + " i = "+i );
if ( i == 2 ) {
aListFruits.add("Pineapple");
System.out.println( "added now a Fruit to the List ");
}
}
}
}
How to perform mouseover function in Selenium WebDriver using Java?
None of these answers work when trying to do the following:
- Hover over a menu item.
- Find the hidden element that is ONLY available after the hover.
- Click the sub-menu item.
If you insert a 'perform' command after the moveToElement, it moves to the element, and the sub-menu item shows for a brief period, but that is not a hover. The hidden element immediately disappears before it can be found resulting in a ElementNotFoundException. I tried two things:
Actions builder = new Actions(driver);
builder.moveToElement(hoverElement).perform();
builder.moveToElement(clickElement).click().perform();
This did not work for me. The following worked for me:
Actions builder = new Actions(driver);
builder.moveToElement(hoverElement).perform();
By locator = By.id("clickElementID");
driver.click(locator);
Using the Actions to hover and the standard WebDriver click, I could hover and then click.
How do I remove trailing whitespace using a regular expression?
The platform is not specified, but in C# (.NET) it would be:
Regular expression (presumes the multiline option - the example below uses it):
[ \t]+(\r?$)
Replacement:
$1
For an explanation of "\r?$", see Regular Expression Options, Multiline Mode (MSDN).
Code example
This will remove all trailing spaces and all trailing TABs in all lines:
string inputText = " Hello, World! \r\n" +
" Some other line\r\n" +
" The last line ";
string cleanedUpText = Regex.Replace(inputText,
@"[ \t]+(\r?$)", @"$1",
RegexOptions.Multiline);
What is ' and why does Google search replace it with apostrophe?
It's HTML character references for encoding a character by its decimal code point
Look at the ASCII table here and you'll see that 39 (hex 0x27, octal 47) is the code for apostrophe

ggplot with 2 y axes on each side and different scales
You can create a scaling factor which is applied to the second geom and right y-axis. This is derived from Sebastian's solution.
library(ggplot2)
scaleFactor <- max(mtcars$cyl) / max(mtcars$hp)
ggplot(mtcars, aes(x=disp)) +
geom_smooth(aes(y=cyl), method="loess", col="blue") +
geom_smooth(aes(y=hp * scaleFactor), method="loess", col="red") +
scale_y_continuous(name="cyl", sec.axis=sec_axis(~./scaleFactor, name="hp")) +
theme(
axis.title.y.left=element_text(color="blue"),
axis.text.y.left=element_text(color="blue"),
axis.title.y.right=element_text(color="red"),
axis.text.y.right=element_text(color="red")
)
Note: using ggplot2 v3.0.0
How to select specified node within Xpath node sets by index with Selenium?
//img[@title='Modify'][i]
is short for
/descendant-or-self::node()/img[@title='Modify'][i]
hence is returning the i'th node under the same parent node.
You want
/descendant-or-self::img[@title='Modify'][i]
JavaScript/jQuery: replace part of string?
You need to set the text after the replace call:
$('.element span').each(function() {_x000D_
console.log($(this).text());_x000D_
var text = $(this).text().replace('N/A, ', '');_x000D_
$(this).text(text);_x000D_
});<script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.3.1/jquery.min.js"></script>_x000D_
<div class="element">_x000D_
<span>N/A, Category</span>_x000D_
</div>Here's another cool way you can do it (hat tip @Felix King):
$(".element span").text(function(index, text) {
return text.replace("N/A, ", "");
});
MySQL JOIN ON vs USING?
For those experimenting with this in phpMyAdmin, just a word:
phpMyAdmin appears to have a few problems with USING. For the record this is phpMyAdmin run on Linux Mint, version: "4.5.4.1deb2ubuntu2", Database server: "10.2.14-MariaDB-10.2.14+maria~xenial - mariadb.org binary distribution".
I have run SELECT commands using JOIN and USING in both phpMyAdmin and in Terminal (command line), and the ones in phpMyAdmin produce some baffling responses:
1) a LIMIT clause at the end appears to be ignored.
2) the supposed number of rows as reported at the top of the page with the results is sometimes wrong: for example 4 are returned, but at the top it says "Showing rows 0 - 24 (2503 total, Query took 0.0018 seconds.)"
Logging on to mysql normally and running the same queries does not produce these errors. Nor do these errors occur when running the same query in phpMyAdmin using JOIN ... ON .... Presumably a phpMyAdmin bug.
How to delete cookies on an ASP.NET website
I just want to point out that the Session ID cookie is not removed when using Session.Abandon as others said.
When you abandon a session, the session ID cookie is not removed from the browser of the user. Therefore, as soon as the session has been abandoned, any new requests to the same application will use the same session ID but will have a new session state instance. At the same time, if the user opens another application within the same DNS domain, the user will not lose their session state after the Abandon method is called from one application.
Sometimes, you may not want to reuse the session ID. If you do and if you understand the ramifications of not reusing the session ID, use the following code example to abandon a session and to clear the session ID cookie:
Session.Abandon(); Response.Cookies.Add(new HttpCookie("ASP.NET_SessionId", ""));This code example clears the session state from the server and sets the session state cookie to null. The null value effectively clears the cookie from the browser.
How to make a checkbox checked with jQuery?
$('#test').prop('checked', true);
Note only in jQuery 1.6+
Datatables Select All Checkbox
The solution given by @annoyingmouse works for me.
But to use the checkbox in the header cell, I also had to fix select.dataTables.css.
It seems that they used :
table.dataTable tbody th.select-checkbox
instead of :
table.dataTable thead th.select-checkbox
So I had to add this to my css :
table.dataTable thead th.select-checkbox {
position: relative;
}
table.dataTable thead th.select-checkbox:before,
table.dataTable thead th.select-checkbox:after {
display: block;
position: absolute;
top: 1.2em;
left: 50%;
width: 12px;
height: 12px;
box-sizing: border-box;
}
table.dataTable tbody td.select-checkbox:before,
table.dataTable thead th.select-checkbox:before {
content: ' ';
margin-top: -6px;
margin-left: -6px;
border: 1px solid black;
border-radius: 3px;
}
Simplest way to set image as JPanel background
Simplest way to set image as JPanel background
Don't use a JPanel. Just use a JLabel with an Icon then you don't need custom code.
See Background Panel for more information as well as a solution that will paint the image on a JPanel with 3 different painting options:
- scaled
- tiled
- actual
How can the error 'Client found response content type of 'text/html'.. be interpreted
Delete web.config file and insert again. http://forums.asp.net/post/916808.aspx
ConnectionTimeout versus SocketTimeout
A connection timeout is the maximum amount of time that the program is willing to wait to setup a connection to another process. You aren't getting or posting any application data at this point, just establishing the connection, itself.
A socket timeout is the timeout when waiting for individual packets. It's a common misconception that a socket timeout is the timeout to receive the full response. So if you have a socket timeout of 1 second, and a response comprised of 3 IP packets, where each response packet takes 0.9 seconds to arrive, for a total response time of 2.7 seconds, then there will be no timeout.
Python IndentationError unindent does not match any outer indentation level
I had the same problem quite a few times. It happened especially when i tried to paste a few lines of code from an editor online, the spaces are not registered properly as 'tabs' or 'spaces'.
However the fix was quite simple. I just had to remove the spacing across all the lines of code in that specific set and space it again with the tabs correctly. This fixed my problem.
The matching wildcard is strict, but no declaration can be found for element 'context:component-scan
Add This Two Schema locations. That's enough and Efficient instead of adding all the unnecessary schema
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
How to set caret(cursor) position in contenteditable element (div)?
Based on Tim Down's answer, but it checks for the last known "good" text row. It places the cursor at the very end.
Furthermore, I could also recursively/iteratively check the last child of each consecutive last child to find the absolute last "good" text node in the DOM.
function onClickHandler() {_x000D_
setCaret(document.getElementById("editable"));_x000D_
}_x000D_
_x000D_
function setCaret(el) {_x000D_
let range = document.createRange(),_x000D_
sel = window.getSelection(),_x000D_
lastKnownIndex = -1;_x000D_
for (let i = 0; i < el.childNodes.length; i++) {_x000D_
if (isTextNodeAndContentNoEmpty(el.childNodes[i])) {_x000D_
lastKnownIndex = i;_x000D_
}_x000D_
}_x000D_
if (lastKnownIndex === -1) {_x000D_
throw new Error('Could not find valid text content');_x000D_
}_x000D_
let row = el.childNodes[lastKnownIndex],_x000D_
col = row.textContent.length;_x000D_
range.setStart(row, col);_x000D_
range.collapse(true);_x000D_
sel.removeAllRanges();_x000D_
sel.addRange(range);_x000D_
el.focus();_x000D_
}_x000D_
_x000D_
function isTextNodeAndContentNoEmpty(node) {_x000D_
return node.nodeType == Node.TEXT_NODE && node.textContent.trim().length > 0_x000D_
}<div id="editable" contenteditable="true">_x000D_
text text text<br>text text text<br>text text text<br>_x000D_
</div>_x000D_
<button id="button" onclick="onClickHandler()">focus</button>Most simple code to populate JTable from ResultSet
I think this is the Easiest way to populate/model a table with ResultSet.. Download and include rs2xml.jar Get rs2xml.jar in your libraries..
import net.proteanit.sql.DbUtils;
try
{
CreateConnection();
PreparedStatement st =conn.prepareStatement("Select * from ABC;");
ResultSet rs = st.executeQuery();
tblToBeFilled.setModel(DbUtils.resultSetToTableModel(rs));
conn.close();
}
catch(Exception ex)
{
JOptionPane.showMessageDialog(null, ex.toString());
}
How do I deploy Node.js applications as a single executable file?
Meanwhile I have found the (for me) perfect solution: nexe, which creates a single executable from a Node.js application including all of its modules.
It's the next best thing to an ideal solution.
Install an apk file from command prompt?
- Press Win+R > cmd
- Navigate to platform-tools\ in the android-sdk windows folder
- Type adb
- now follow the steps writte by Mohit Kanada (ensure that you mention the entire path of the .apk file for eg. d:\android-apps\test.apk)
How to stop text from taking up more than 1 line?
Using ellipsis will add the ... at the last.
<style type="text/css">
div {
white-space: nowrap;
overflow: hidden;
text-overflow: ellipsis;
}
</style>
HREF="" automatically adds to current page URL (in PHP). Can't figure it out
Add http:// in front of url
Incorrect
<a href="www.example.com">www.example.com</span></p>
Correct
<a href="http://www.example.com">www.example.com</span></p>
How to reverse an std::string?
Try
string reversed(temp.rbegin(), temp.rend());
EDIT: Elaborating as requested.
string::rbegin() and string::rend(), which stand for "reverse begin" and "reverse end" respectively, return reverse iterators into the string. These are objects supporting the standard iterator interface (operator* to dereference to an element, i.e. a character of the string, and operator++ to advance to the "next" element), such that rbegin() points to the last character of the string, rend() points to the first one, and advancing the iterator moves it to the previous character (this is what makes it a reverse iterator).
Finally, the constructor we are passing these iterators into is a string constructor of the form:
template <typename Iterator>
string(Iterator first, Iterator last);
which accepts a pair of iterators of any type denoting a range of characters, and initializes the string to that range of characters.
Concrete Javascript Regex for Accented Characters (Diacritics)
The XRegExp library has a plugin named Unicode that helps solve tasks like this.
<script src="xregexp.js"></script>
<script src="addons/unicode/unicode-base.js"></script>
<script>
var unicodeWord = XRegExp("^\\p{L}+$");
unicodeWord.test("???????"); // true
unicodeWord.test("???"); // true
unicodeWord.test("???????"); // true
</script>
It's mentioned in the comments to the question, but it's easy to miss. I've noticed it only after I submitted this answer.
Register 32 bit COM DLL to 64 bit Windows 7
I was getting the error "The module may compatible with this version of windows" for both version of RegSvr32 (32 bit and 64 bit). I was trying to register a DLL that was built for XP (32 bit) in Server 2008 R2 (x64) and none of the Regsr32 resolutions worked for me. However, registering the assembly in the appropriate .Net worked perfect for me. C:\Windows\Microsoft.NET\Framework\v2.0.50727\RegAsm.exe
How can I get this ASP.NET MVC SelectList to work?
It's very simple to get SelectList and SelectedValue working together, even if your property isn't a simple object like a Int, String or a Double value.
Example:
Assuming our Region object is something like this:
public class Region {
public Guid ID { get; set; }
public Guid Name { get; set; }
}
And your view model is something like:
public class ContactViewModel {
public DateTime Date { get; set; }
public Region Region { get; set; }
public List<Region> Regions { get; set; }
}
You can have the code below:
@Html.DropDownListFor(x => x.Region, new SelectList(Model.Regions, "ID", "Name"))
Only if you override the ToString method of Region object to something like:
public class Region {
public Guid ID { get; set; }
public Guid Name { get; set; }
public override string ToString()
{
return ID.ToString();
}
}
This have 100% garantee to work.
But I really believe the best way to get SelectList 100% working in all circustances is by using the Equals method to test DropDownList or ListBox property value against each item on items collection.
Where is the Global.asax.cs file?
It don't create normally; you need to add it by yourself.
After adding Global.asax by
- Right clicking your website -> Add New Item -> Global Application Class -> Add
You need to add a class
- Right clicking App_Code -> Add New Item -> Class -> name it Global.cs -> Add
Inherit the newly generated by System.Web.HttpApplication and copy all the method created Global.asax to Global.cs and also add an inherit attribute to the Global.asax file.
Your Global.asax will look like this: -
<%@ Application Language="C#" Inherits="Global" %>
Your Global.cs in App_Code will look like this: -
public class Global : System.Web.HttpApplication
{
public Global()
{
//
// TODO: Add constructor logic here
//
}
void Application_Start(object sender, EventArgs e)
{
// Code that runs on application startup
}
/// Many other events like begin request...e.t.c, e.t.c
}
How to fix date format in ASP .NET BoundField (DataFormatString)?
The following links will help you:
In Client side design page you can try this: {0:G}
OR
You can convert that datetime format inside the query itself from the database:
How to subtract one month using moment.js?
For substracting in moment.js:
moment().subtract(1, 'months').format('MMM YYYY');
Documentation:
http://momentjs.com/docs/#/manipulating/subtract/
Before version 2.8.0, the moment#subtract(String, Number) syntax was also supported. It has been deprecated in favor of moment#subtract(Number, String).
moment().subtract('seconds', 1); // Deprecated in 2.8.0
moment().subtract(1, 'seconds');
As of 2.12.0 when decimal values are passed for days and months, they are rounded to the nearest integer. Weeks, quarters, and years are converted to days or months, and then rounded to the nearest integer.
moment().subtract(1.5, 'months') == moment().subtract(2, 'months')
moment().subtract(.7, 'years') == moment().subtract(8, 'months') //.7*12 = 8.4, rounded to 8
'str' object does not support item assignment in Python
How about this solution:
str="Hello World" (as stated in problem) srr = str+ ""
Using Server.MapPath in external C# Classes in ASP.NET
The server.mappath("") will work on aspx page,if you want to get the absolute path from a class file you have to use this-
HttpContext.Current.Server.MapPath("~/EmailLogic/RegistrationTemplate.html")
Should I test private methods or only public ones?
If you are developing test driven (TDD), you will test your private methods.
MVC: How to Return a String as JSON
You just need to return standard ContentResult and set ContentType to "application/json". You can create custom ActionResult for it:
public class JsonStringResult : ContentResult
{
public JsonStringResult(string json)
{
Content = json;
ContentType = "application/json";
}
}
And then return it's instance:
[HttpPost]
public JsonResult UpdateBatchSearchMembers()
{
string returntext;
if (!System.IO.File.Exists(path))
returntext = Properties.Settings.Default.EmptyBatchSearchUpdate;
else
returntext = Properties.Settings.Default.ResponsePath;
return new JsonStringResult(returntext);
}
How do I change the color of radio buttons?
A radio button is a native element specific to each OS/browser. There is no way to change its color/style, unless you want to implement custom images or use a custom Javascript library which includes images (e.g. this - cached link)
What is the `data-target` attribute in Bootstrap 3?
data-target is used by bootstrap to make your life easier. You (mostly) do not need to write a single line of Javascript to use their pre-made JavaScript components.
The data-target attribute should contain a CSS selector that points to the HTML Element that will be changed.
<!-- Button trigger modal -->
<button class="btn btn-primary btn-lg" data-toggle="modal" data-target="#myModal">
Launch demo modal
</button>
<!-- Modal -->
<div class="modal fade" id="myModal" tabindex="-1" role="dialog" aria-labelledby="myModalLabel" aria-hidden="true">
[...]
</div>
In this example, the button has data-target="#myModal", if you click on it, <div id="myModal">...</div> will be modified (in this case faded in).
This happens because #myModal in CSS selectors points to elements that have an id attribute with the myModal value.
Further information about the HTML5 "data-" attribute: https://developer.mozilla.org/en-US/docs/Web/Guide/HTML/Using_data_attributes
Logging in Scala
I find very convenient using some kind of java logger, sl4j for example, with simple scala wrapper, which brings me such syntax
val #! = new Logger(..) // somewhere deep in dsl.logging.
object User with dsl.logging {
#! ! "info message"
#! dbg "debug message"
#! trace "var a=true"
}
In my opinion very usefull mixin of java proven logging frameworks and scala's fancy syntax.
What is the correct way to check for string equality in JavaScript?
always Until you fully understand the differences and implications of using the == and === operators, use the === operator since it will save you from obscure (non-obvious) bugs and WTFs. The "regular" == operator can have very unexpected results due to the type-coercion internally, so using === is always the recommended approach.
For insight into this, and other "good vs. bad" parts of Javascript read up on Mr. Douglas Crockford and his work. There's a great Google Tech Talk where he summarizes lots of good info: http://www.youtube.com/watch?v=hQVTIJBZook
Update:
The You Don't Know JS series by Kyle Simpson is excellent (and free to read online). The series goes into the commonly misunderstood areas of the language and explains the "bad parts" that Crockford suggests you avoid. By understanding them you can make proper use of them and avoid the pitfalls.
The "Up & Going" book includes a section on Equality, with this specific summary of when to use the loose (==) vs strict (===) operators:
To boil down a whole lot of details to a few simple takeaways, and help you know whether to use
==or===in various situations, here are my simple rules:
- If either value (aka side) in a comparison could be the
trueorfalsevalue, avoid==and use===.- If either value in a comparison could be of these specific values (
0,"", or[]-- empty array), avoid==and use===.- In all other cases, you're safe to use
==. Not only is it safe, but in many cases it simplifies your code in a way that improves readability.
I still recommend Crockford's talk for developers who don't want to invest the time to really understand Javascript—it's good advice for a developer who only occasionally works in Javascript.
Unit Testing: DateTime.Now
We were using a static SystemTime object, but ran into problems running parallel unit tests. I attempted to use Henk van Boeijen's solution but had problems across spawned asynchronous threads, ended up using using AsyncLocal in a manner similar to this below:
public static class Clock
{
private static Func<DateTime> _utcNow = () => DateTime.UtcNow;
static AsyncLocal<Func<DateTime>> _override = new AsyncLocal<Func<DateTime>>();
public static DateTime UtcNow => (_override.Value ?? _utcNow)();
public static void Set(Func<DateTime> func)
{
_override.Value = func;
}
public static void Reset()
{
_override.Value = null;
}
}
Sourced from https://gist.github.com/CraftyFella/42f459f7687b0b8b268fc311e6b4af08
Deleting a pointer in C++
I believe you're not fully understanding how pointers work.
When you have a pointer pointing to some memory there are three different things you must understand:
- there is "what is pointed" by the pointer (the memory)
- this memory address
- not all pointers need to have their memory deleted: you only need to delete memory that was dynamically allocated (used new operator).
Imagine:
int *ptr = new int;
// ptr has the address of the memory.
// at this point, the actual memory doesn't have anything.
*ptr = 8;
// you're assigning the integer 8 into that memory.
delete ptr;
// you are only deleting the memory.
// at this point the pointer still has the same memory address (as you could
// notice from your 2nd test) but what inside that memory is gone!
When you did
ptr = NULL;
// you didn't delete the memory
// you're only saying that this pointer is now pointing to "nowhere".
// the memory that was pointed by this pointer is now lost.
C++ allows that you try to delete a pointer that points to null but it doesn't actually do anything, just doesn't give any error.
Run text file as commands in Bash
Execute
. example.txt
That does exactly what you ask for, without setting an executable flag on the file or running an extra bash instance.
For a detailed explanation see e.g. https://unix.stackexchange.com/questions/43882/what-is-the-difference-between-sourcing-or-source-and-executing-a-file-i
Sort a Map<Key, Value> by values
If you have duplicate keys and only a small set of data (<1000) and your code is not performance critical you can just do the following:
Map<String,Integer> tempMap=new HashMap<String,Integer>(inputUnsortedMap);
LinkedHashMap<String,Integer> sortedOutputMap=new LinkedHashMap<String,Integer>();
for(int i=0;i<inputUnsortedMap.size();i++){
Map.Entry<String,Integer> maxEntry=null;
Integer maxValue=-1;
for(Map.Entry<String,Integer> entry:tempMap.entrySet()){
if(entry.getValue()>maxValue){
maxValue=entry.getValue();
maxEntry=entry;
}
}
tempMap.remove(maxEntry.getKey());
sortedOutputMap.put(maxEntry.getKey(),maxEntry.getValue());
}
inputUnsortedMap is the input to the code.
The variable sortedOutputMap will contain the data in decending order when iterated over. To change order just change > to a < in the if statement.
Is not the fastest sort but does the job without any additional dependencies.
Reading values from DataTable
For VB.Net is
Dim con As New OleDb.OleDbConnection("Provider=Microsoft.Jet.OLEDB.4.0;Data Source=" + "database path")
Dim cmd As New OleDb.OleDbCommand
Dim dt As New DataTable
Dim da As New OleDb.OleDbDataAdapter
con.Open()
cmd.Connection = con
cmd.CommandText = sql
da.SelectCommand = cmd
da.Fill(dt)
For i As Integer = 0 To dt.Rows.Count
someVar = dt.Rows(i)("fieldName")
Next
Unable to resolve host "<URL here>" No address associated with host name
You probably don't have the INTERNET permission. Try adding this to your AndroidManifest.xml file, right before </manifest>:
<uses-permission android:name="android.permission.INTERNET" />
Note: the above doesn't have to be right before the </manifest> tag, but that is a good / correct place to put it.
Note: if this answer doesn't help in your case, read the other answers!
Python to print out status bar and percentage
The '\r' character (carriage return) resets the cursor to the beginning of the line and allows you to write over what was previously on the line.
from time import sleep
import sys
for i in range(21):
sys.stdout.write('\r')
# the exact output you're looking for:
sys.stdout.write("[%-20s] %d%%" % ('='*i, 5*i))
sys.stdout.flush()
sleep(0.25)
I'm not 100% sure if this is completely portable across all systems, but it works on Linux and OSX at the least.
Argument list too long error for rm, cp, mv commands
You could use a bash array:
files=(*.pdf)
for((I=0;I<${#files[@]};I+=1000)); do
rm -f "${files[@]:I:1000}"
done
This way it will erase in batches of 1000 files per step.
How to Diff between local uncommitted changes and origin
If you want to compare files visually you can use:
git difftool
It will start your diff app automatically for each changed file.
PS: If you did not set a diff app, you can do it like in the example below(I use Winmerge):
git config --global merge.tool winmerge
git config --replace --global mergetool.winmerge.cmd "\"C:\Program Files (x86)\WinMerge\WinMergeU.exe\" -e -u -dl \"Base\" -dr \"Mine\" \"$LOCAL\" \"$REMOTE\" \"$MERGED\""
git config --global mergetool.prompt false
How do I set <table> border width with CSS?
<table style='border:1px solid black'>
<tr>
<td>Derp</td>
</tr>
</table>
This should work. I use the shorthand syntax for borders.
How to get cookie expiration date / creation date from javascript?
One possibility is to delete to cookie you are looking for the expiration date from and rewrite it. Then you'll know the expiration date.
Replacing a character from a certain index
You can't replace a letter in a string. Convert the string to a list, replace the letter, and convert it back to a string.
>>> s = list("Hello world")
>>> s
['H', 'e', 'l', 'l', 'o', ' ', 'W', 'o', 'r', 'l', 'd']
>>> s[int(len(s) / 2)] = '-'
>>> s
['H', 'e', 'l', 'l', 'o', '-', 'W', 'o', 'r', 'l', 'd']
>>> "".join(s)
'Hello-World'
How to solve could not create the virtual machine error of Java Virtual Machine Launcher?
Install latest java jdk and your problem will be solved.
how to get the one entry from hashmap without iterating
If you are using Java 8, it is as simple as findFirst():
Quick example:
Optional<Car> theCarFoundOpt = carMap.values().stream().findFirst();
if(theCarFoundOpt.isPresent()) {
return theCarFoundOpt.get().startEngine();
}
how to convert object to string in java
Might not be so related to the issue above. However if you are looking for a way to serialize Java object as string, this could come in hand
package pt.iol.security;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.util.zip.GZIPInputStream;
import java.util.zip.GZIPOutputStream;
import org.apache.commons.codec.binary.Base64;
public class ObjectUtil {
static final Base64 base64 = new Base64();
public static String serializeObjectToString(Object object) throws IOException {
try (
ByteArrayOutputStream arrayOutputStream = new ByteArrayOutputStream();
GZIPOutputStream gzipOutputStream = new GZIPOutputStream(arrayOutputStream);
ObjectOutputStream objectOutputStream = new ObjectOutputStream(gzipOutputStream);) {
objectOutputStream.writeObject(object);
objectOutputStream.flush();
return new String(base64.encode(arrayOutputStream.toByteArray()));
}
}
public static Object deserializeObjectFromString(String objectString) throws IOException, ClassNotFoundException {
try (
ByteArrayInputStream arrayInputStream = new ByteArrayInputStream(base64.decode(objectString));
GZIPInputStream gzipInputStream = new GZIPInputStream(arrayInputStream);
ObjectInputStream objectInputStream = new ObjectInputStream(gzipInputStream)) {
return objectInputStream.readObject();
}
}
}
Converting string to date in mongodb
Using MongoDB 4.0 and newer
The $toDate operator will convert the value to a date. If the value cannot be converted to a date, $toDate errors. If the value is null or missing, $toDate returns null:
You can use it within an aggregate pipeline as follows:
db.collection.aggregate([
{ "$addFields": {
"created_at": {
"$toDate": "$created_at"
}
} }
])
The above is equivalent to using the $convert operator as follows:
db.collection.aggregate([
{ "$addFields": {
"created_at": {
"$convert": {
"input": "$created_at",
"to": "date"
}
}
} }
])
Using MongoDB 3.6 and newer
You cab also use the $dateFromString operator which converts the date/time string to a date object and has options for specifying the date format as well as the timezone:
db.collection.aggregate([
{ "$addFields": {
"created_at": {
"$dateFromString": {
"dateString": "$created_at",
"format": "%m-%d-%Y" /* <-- option available only in version 4.0. and newer */
}
}
} }
])
Using MongoDB versions >= 2.6 and < 3.2
If MongoDB version does not have the native operators that do the conversion, you would need to manually iterate the cursor returned by the find() method by either using the forEach() method
or the cursor method next() to access the documents. Withing the loop, convert the field to an ISODate object and then update the field using the $set operator, as in the following example where the field is called created_at and currently holds the date in string format:
var cursor = db.collection.find({"created_at": {"$exists": true, "$type": 2 }});
while (cursor.hasNext()) {
var doc = cursor.next();
db.collection.update(
{"_id" : doc._id},
{"$set" : {"created_at" : new ISODate(doc.created_at)}}
)
};
For improved performance especially when dealing with large collections, take advantage of using the Bulk API for bulk updates as you will be sending the operations to the server in batches of say 1000 which gives you a better performance as you are not sending every request to the server, just once in every 1000 requests.
The following demonstrates this approach, the first example uses the Bulk API available in MongoDB versions >= 2.6 and < 3.2. It updates all
the documents in the collection by changing the created_at fields to date fields:
var bulk = db.collection.initializeUnorderedBulkOp(),
counter = 0;
db.collection.find({"created_at": {"$exists": true, "$type": 2 }}).forEach(function (doc) {
var newDate = new ISODate(doc.created_at);
bulk.find({ "_id": doc._id }).updateOne({
"$set": { "created_at": newDate}
});
counter++;
if (counter % 1000 == 0) {
bulk.execute(); // Execute per 1000 operations and re-initialize every 1000 update statements
bulk = db.collection.initializeUnorderedBulkOp();
}
})
// Clean up remaining operations in queue
if (counter % 1000 != 0) { bulk.execute(); }
Using MongoDB 3.2
The next example applies to the new MongoDB version 3.2 which has since deprecated the Bulk API and provided a newer set of apis using bulkWrite():
var bulkOps = [],
cursor = db.collection.find({"created_at": {"$exists": true, "$type": 2 }});
cursor.forEach(function (doc) {
var newDate = new ISODate(doc.created_at);
bulkOps.push(
{
"updateOne": {
"filter": { "_id": doc._id } ,
"update": { "$set": { "created_at": newDate } }
}
}
);
if (bulkOps.length === 500) {
db.collection.bulkWrite(bulkOps);
bulkOps = [];
}
});
if (bulkOps.length > 0) db.collection.bulkWrite(bulkOps);
What is C# equivalent of <map> in C++?
std::map<Key, Value> ? SortedDictionary<TKey, TValue>
std::unordered_map<Key, Value> ? Dictionary<TKey, TValue>
CORS Access-Control-Allow-Headers wildcard being ignored?
I found that Access-Control-Allow-Headers: * should be set ONLY for OPTIONS request.
If you return it for POST request then browser cancel the request (at least for chrome)
The following PHP code works for me
// Allow CORS
if (isset($_SERVER['HTTP_ORIGIN'])) {
header("Access-Control-Allow-Origin: {$_SERVER['HTTP_ORIGIN']}");
header('Access-Control-Allow-Credentials: true');
header("Access-Control-Allow-Methods: GET, POST, OPTIONS");
}
// Access-Control headers are received during OPTIONS requests
if ($_SERVER['REQUEST_METHOD'] == 'OPTIONS') {
header("Access-Control-Allow-Headers: *");
}
I found similar questions with some misleading response:
- Server thread says that this is 2 years bug of chrome:
Access-Control-Allow-Headersdoes not match with localhost. It's wrong: I can use CORS to my local server with Post normally Access-Control-Allow-Headersdoes accept wildcards. It's also wrong, wildcard works for me (I tested only with Chrome)
This take me half day to figure out the issue.
Happy coding
Python: Remove division decimal
if val % 1 == 0:
val = int(val)
else:
val = float(val)
This worked for me.
How it works: if the remainder of the quotient of val and 1 is 0, val has to be an integer and can, therefore, be declared to be int without having to worry about losing decimal numbers.
Compare these two situations:
A:
val = 12.00
if val % 1 == 0:
val = int(val)
else:
val = float(val)
print(val)
In this scenario, the output is 12, because 12.00 divided by 1 has the remainder of 0. With this information we know, that val doesn't have any decimals and we can declare val to be int.
B:
val = 13.58
if val % 1 == 0:
val = int(val)
else:
val = float(val)
print(val)
This time the output is 13.58, because when val is divided by 1 there is a remainder (0.58) and therefore val is declared to be a float.
By just declaring the number to be an int (without testing the remainder) decimal numbers will be cut off.
This way there are no zeros in the end and no other than the zeros will be ignored.
Is it possible to use Visual Studio on macOS?
I recently purchased a MacBook Air (mid-2011 model) and was really happy to find that Apple officially supports Windows 7. If you purchase Windows 7 (I got DSP), you can use the Boot Camp assistant in OSX to designate part of your hard drive to Windows. Then you can install and run Windows 7 natively as if it were as Windows notebook.
I use Visual Studio 2010 on Windows 7 on my MacBook Air (I kept OSX as well) and I could not be happier. Heck, the initial start-up of the program only takes 3 seconds thanks to the SSD.
As others have mentions, you can run it on OSX using Parallels, etc. but I prefer to run it natively.
Check whether a value exists in JSON object
Check for a value single level
const hasValue = Object.values(json).includes("bar");
Check for a value multi-level
function hasValueDeep(json, findValue) {
const values = Object.values(json);
let hasValue = values.includes(findValue);
values.forEach(function(value) {
if (typeof value === "object") {
hasValue = hasValue || hasValueDeep(value, findValue);
}
})
return hasValue;
}
onchange event for input type="number"
The oninput event (.bind('input', fn)) covers any changes from keystrokes to arrow clicks and keyboard/mouse paste, but is not supported in IE <9.
jQuery(function($) {_x000D_
$('#mirror').text($('#alice').val());_x000D_
_x000D_
$('#alice').on('input', function() {_x000D_
$('#mirror').text($('#alice').val());_x000D_
});_x000D_
});<script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.3.1/jquery.min.js"></script>_x000D_
_x000D_
<input id="alice" type="number" step="any" value="99">_x000D_
_x000D_
<p id="mirror"></p>Unable to copy ~/.ssh/id_rsa.pub
This was too good of an answer not to post it here. It's from a Gilles, a fellow user from askubuntu:
The clipboard is provided by the X server. It doesn't matter whether the server is headless or not, what matters is that your local graphical session is available to programs running on the remote machine. Thanks to X's network-transparent design, this is possible.
I assume that you're connecting to the remote server with SSH from a machine running Linux. Make sure that X11 forwarding is enabled both in the client configuration and in the server configuration. In the client configuration, you need to have the line
ForwardX11 yesin~/.ssh/configto have it on by default, or pass the option-Xto thesshcommand just for that session. In the server configuration, you need to have the lineX11Forwarding yesin/etc/ssh/sshd_config(it is present by default on Ubuntu).To check whether X11 forwarding is enabled, look at the value of the
DISPLAYenvironment variable:echo $DISPLAY. You should see a value likelocalhost:10(applications running on the remote machine are told to connect to a display running on the same machine, but that display connection is in fact forwarded by SSH to your client-side display). Note that ifDISPLAYisn't set, it's no use setting it manually: the environment variable is always set correctly if the forwarding is in place. If you need to diagnose SSH connection issues, pass the option-vvvtosshto get a detailed trace of what's happening.If you're connecting through some other means, you may or may not be able to achieve X11 forwarding. If your client is running Windows, PuTTY supports X11 forwarding; you'll have to run an X server on the Windows machine such as Xming.
By Gilles from askubuntu
How can I send mail from an iPhone application
Swift 2.2. Adapted from Esq's answer
import Foundation
import MessageUI
class MailSender: NSObject, MFMailComposeViewControllerDelegate {
let parentVC: UIViewController
init(parentVC: UIViewController) {
self.parentVC = parentVC
super.init()
}
func send(title: String, messageBody: String, toRecipients: [String]) {
if MFMailComposeViewController.canSendMail() {
let mc: MFMailComposeViewController = MFMailComposeViewController()
mc.mailComposeDelegate = self
mc.setSubject(title)
mc.setMessageBody(messageBody, isHTML: false)
mc.setToRecipients(toRecipients)
parentVC.presentViewController(mc, animated: true, completion: nil)
} else {
print("No email account found.")
}
}
func mailComposeController(controller: MFMailComposeViewController,
didFinishWithResult result: MFMailComposeResult, error: NSError?) {
switch result.rawValue {
case MFMailComposeResultCancelled.rawValue: print("Mail Cancelled")
case MFMailComposeResultSaved.rawValue: print("Mail Saved")
case MFMailComposeResultSent.rawValue: print("Mail Sent")
case MFMailComposeResultFailed.rawValue: print("Mail Failed")
default: break
}
parentVC.dismissViewControllerAnimated(false, completion: nil)
}
}
Client code :
var ms: MailSender?
@IBAction func onSendPressed(sender: AnyObject) {
ms = MailSender(parentVC: self)
let title = "Title"
let messageBody = "https://stackoverflow.com/questions/310946/how-can-i-send-mail-from-an-iphone-application this question."
let toRecipents = ["[email protected]"]
ms?.send(title, messageBody: messageBody, toRecipents: toRecipents)
}