Hiding button using jQuery
It depends on the jQuery selector that you use. Since id should be unique within the DOM, the first one would be simple:
$('#Comanda').hide();
The second one might require something more, depending on the other elements and how to uniquely identify it. If the name of that particular input is unique, then this would work:
$('input[name="Vizualizeaza"]').hide();
How to store NULL values in datetime fields in MySQL?
I just tested in MySQL v5.0.6 and the datetime column accepted null without issue.
What does Visual Studio mean by normalize inconsistent line endings?
It's not just Visual Studio... It'd be any tools that read the files, compilers, linkers, etc. that would have to be able to handle it.
In general (for software development) we accept the multiplatform line ending issue, but let the version control software deal with it.
How to find all links / pages on a website
Another alternative might be
Array.from(document.querySelectorAll("a")).map(x => x.href)
With your $$( its even shorter
Array.from($$("a")).map(x => x.href)
write() versus writelines() and concatenated strings
writelinesexpects an iterable of stringswriteexpects a single string.
line1 + "\n" + line2 merges those strings together into a single string before passing it to write.
Note that if you have many lines, you may want to use "\n".join(list_of_lines).
Difference between MEAN.js and MEAN.io
First of all, MEAN is an acronym for MongoDB, Express, Angular and Node.js.
It generically identifies the combined used of these technologies in a "stack". There is no such a thing as "The MEAN framework".
Lior Kesos at Linnovate took advantage of this confusion. He bought the domain MEAN.io and put some code at https://github.com/linnovate/mean
They luckily received a lot of publicity, and theree are more and more articles and video about MEAN. When you Google "mean framework", mean.io is the first in the list.
Unfortunately the code at https://github.com/linnovate/mean seems poorly engineered.
In February I fell in the trap myself. The site mean.io had a catchy design and the Github repo had 1000+ stars. The idea of questioning the quality did not even pass through my mind. I started experimenting with it but it did not take too long to stumble upon things that were not working, and puzzling pieces of code.
The commit history was also pretty concerning. They re-engineered the code and directory structure multiple times, and merging the new changes is too time consuming.
The nice things about both mean.io and mean.js code is that they come with Bootstrap integration. They also come with Facebook, Github, Linkedin etc authentication through PassportJs and an example of a model (Article) on the backend on MongoDB that sync with the frontend model with AngularJS.
According to Linnovate's website:
Linnovate is the leading Open Source company in Israel, with the most experienced team in the country, dedicated to the creation of high-end open source solutions. Linnovate is the only company in Israel which gives an A-Z services for enterprises for building and maintaining their next web project.
From the website it looks like that their core skill set is Drupal (a PHP content management system) and only lately they started using Node.js and AngularJS.
Lately I was reading the Mean.js Blog and things became clearer. My understanding is that the main Javascript developer (Amos Haviv) left Linnovate to work on Mean.js leaving MEAN.io project with people that are novice Node.js developers that are slowing understanding how things are supposed to work.
In the future things may change but for now I would avoid to use mean.io. If you are looking for a boilerplate for a quickstart Mean.js seems a better option than mean.io.
Syncing Android Studio project with Gradle files
EDIT
Starting with Android Studio 3.1, you should go to:
File -> Sync Project with Gradle Files
OLD
Clicking the button 'Sync Project With Gradle Files' should do the trick:
Tools -> Android -> Sync Project with Gradle Files
If that fails, try running 'Rebuild project':
Build -> Rebuild Project
How do I make a transparent canvas in html5?
Just set the background of the canvas to transparent.
#canvasID{
background:transparent;
}
Select top 2 rows in Hive
Yes, here you can use LIMIT.
You can try it by the below query:
SELECT * FROM employee_list SORT BY salary DESC LIMIT 2
What is the size of column of int(11) in mysql in bytes?
Though this answer is unlikely to be seen, I think the following clarification is worth making:
- the (n) behind an integer data type in MySQL is specifying the display width
- the display width does NOT limit the length of the number returned from a query
- the display width DOES limit the number of zeroes filled for a zero filled column so the total number matches the display width (so long as the actual number does not exceed the display width, in which case the number is shown as is)
- the display width is also meant as a useful tool for developers to know what length the value should be padded to
A BIT OF DETAIL
the display width is, apparently, intended to provide some metadata about how many zeros to display in a zero filled number.
It does NOT actually limit the length of a number returned from a query if that number goes above the display width specified.
To know what length/width is actually allowed for an integer data type in MySQL see the list & link: (types: TINYINT, SMALLINT, MEDIUMINT, INT, BIGINT);
So having said the above, you can expect the display width to have no affect on the results from a standard query, unless the columns are specified as ZEROFILL columns
OR
in the case the data is being pulled into an application & that application is collecting the display width to use for some other sort of padding.
Primary Reference: https://blogs.oracle.com/jsmyth/entry/what_does_the_11_mean
Retrieve last 100 lines logs
You can use tail command as follows:
tail -100 <log file> > newLogfile
Now last 100 lines will be present in newLogfile
EDIT:
More recent versions of tail as mentioned by twalberg use command:
tail -n 100 <log file> > newLogfile
How to click an element in Selenium WebDriver using JavaScript
You can't use WebDriver to do it in JavaScript, as WebDriver is a Java tool. However, you can execute JavaScript from Java using WebDriver, and you could call some JavaScript code that clicks a particular button.
WebDriver driver; // Assigned elsewhere
JavascriptExecutor js = (JavascriptExecutor) driver;
js.executeScript("window.document.getElementById('gbqfb').click()");
Fatal error: Maximum execution time of 30 seconds exceeded in C:\xampp\htdocs\wordpress\wp-includes\class-http.php on line 1610
If you are simply testing a local dev version of WordPress as I was an hitting timeouts when WordPress tries to update itself you can always disable updates for your local version like so: https://www.wpbeginner.com/wp-tutorials/how-to-disable-automatic-updates-in-wordpress/
Don't do this for a production site!
Two column div layout with fluid left and fixed right column
#wrapper {_x000D_
margin-right: 50%;_x000D_
}_x000D_
#content {_x000D_
float: left;_x000D_
width: 50%;_x000D_
background-color: #CCF;_x000D_
}_x000D_
#sidebar {_x000D_
float: right;_x000D_
width: 200px;_x000D_
margin-right: -200px;_x000D_
background-color: #FFA;_x000D_
}_x000D_
#cleared {_x000D_
clear: both;_x000D_
}<div id="wrapper">_x000D_
<div id="content">Column 1 (fluid)</div>_x000D_
<div id="sidebar">Column 2 (fixed)</div>_x000D_
<div id="cleared"></div>_x000D_
</div>Python re.sub(): how to substitute all 'u' or 'U's with 'you'
Another possible solution I came up with was:
re.sub(r'([uU]+(.)?\s)',' you ', text)
c# - How to get sum of the values from List?
You can use LINQ for this
var list = new List<int>();
var sum = list.Sum();
and for a List of strings like Roy Dictus said you have to convert
list.Sum(str => Convert.ToInt32(str));
How to copy java.util.list Collection
Use the ArrayList copy constructor, then sort that.
List oldList;
List newList = new ArrayList(oldList);
Collections.sort(newList);
After making the copy, any changes to newList do not affect oldList.
Note however that only the references are copied, so the two lists share the same objects, so changes made to elements of one list affect the elements of the other.
numpy division with RuntimeWarning: invalid value encountered in double_scalars
You can't solve it. Simply answer1.sum()==0, and you can't perform a division by zero.
This happens because answer1 is the exponential of 2 very large, negative numbers, so that the result is rounded to zero.
nan is returned in this case because of the division by zero.
Now to solve your problem you could:
- go for a library for high-precision mathematics, like mpmath. But that's less fun.
- as an alternative to a bigger weapon, do some math manipulation, as detailed below.
- go for a tailored
scipy/numpyfunction that does exactly what you want! Check out @Warren Weckesser answer.
Here I explain how to do some math manipulation that helps on this problem. We have that for the numerator:
exp(-x)+exp(-y) = exp(log(exp(-x)+exp(-y)))
= exp(log(exp(-x)*[1+exp(-y+x)]))
= exp(log(exp(-x) + log(1+exp(-y+x)))
= exp(-x + log(1+exp(-y+x)))
where above x=3* 1089 and y=3* 1093. Now, the argument of this exponential is
-x + log(1+exp(-y+x)) = -x + 6.1441934777474324e-06
For the denominator you could proceed similarly but obtain that log(1+exp(-z+k)) is already rounded to 0, so that the argument of the exponential function at the denominator is simply rounded to -z=-3000. You then have that your result is
exp(-x + log(1+exp(-y+x)))/exp(-z) = exp(-x+z+log(1+exp(-y+x))
= exp(-266.99999385580668)
which is already extremely close to the result that you would get if you were to keep only the 2 leading terms (i.e. the first number 1089 in the numerator and the first number 1000 at the denominator):
exp(3*(1089-1000))=exp(-267)
For the sake of it, let's see how close we are from the solution of Wolfram alpha (link):
Log[(exp[-3*1089]+exp[-3*1093])/([exp[-3*1000]+exp[-3*4443])] -> -266.999993855806522267194565420933791813296828742310997510523
The difference between this number and the exponent above is +1.7053025658242404e-13, so the approximation we made at the denominator was fine.
The final result is
'exp(-266.99999385580668) = 1.1050349147204485e-116
From wolfram alpha is (link)
1.105034914720621496.. × 10^-116 # Wolfram alpha.
and again, it is safe to use numpy here too.
SQL Error: ORA-00922: missing or invalid option
there's nothing wrong with using CHAR like that..
I think your problem is that you have a space in your tablename. It should be: charteredflight or chartered_flight..
How to disable a button when an input is empty?
Using constants allows to combine multiple fields for verification:
class LoginFrm extends React.Component {_x000D_
constructor() {_x000D_
super();_x000D_
this.state = {_x000D_
email: '',_x000D_
password: '',_x000D_
};_x000D_
}_x000D_
_x000D_
handleEmailChange = (evt) => {_x000D_
this.setState({ email: evt.target.value });_x000D_
}_x000D_
_x000D_
handlePasswordChange = (evt) => {_x000D_
this.setState({ password: evt.target.value });_x000D_
}_x000D_
_x000D_
handleSubmit = () => {_x000D_
const { email, password } = this.state;_x000D_
alert(`Welcome ${email} password: ${password}`);_x000D_
}_x000D_
_x000D_
render() {_x000D_
const { email, password } = this.state;_x000D_
const enabled =_x000D_
email.length > 0 &&_x000D_
password.length > 0;_x000D_
return (_x000D_
<form onSubmit={this.handleSubmit}>_x000D_
<input_x000D_
type="text"_x000D_
placeholder="Email"_x000D_
value={this.state.email}_x000D_
onChange={this.handleEmailChange}_x000D_
/>_x000D_
_x000D_
<input_x000D_
type="password"_x000D_
placeholder="Password"_x000D_
value={this.state.password}_x000D_
onChange={this.handlePasswordChange}_x000D_
/>_x000D_
<button disabled={!enabled}>Login</button>_x000D_
</form>_x000D_
)_x000D_
}_x000D_
}_x000D_
_x000D_
ReactDOM.render(<LoginFrm />, document.body);<script src="https://cdnjs.cloudflare.com/ajax/libs/react/15.1.0/react.min.js"></script>_x000D_
<script src="https://cdnjs.cloudflare.com/ajax/libs/react/15.1.0/react-dom.min.js"></script>_x000D_
<body>_x000D_
_x000D_
_x000D_
</body>A long bigger than Long.MAX_VALUE
That method can't return true. That's the point of Long.MAX_VALUE. It would be really confusing if its name were... false. Then it should be just called Long.SOME_FAIRLY_LARGE_VALUE and have literally zero reasonable uses. Just use Android's isUserAGoat, or you may roll your own function that always returns false.
Note that a long in memory takes a fixed number of bytes. From Oracle:
long: The long data type is a 64-bit signed two's complement integer. It has a minimum value of -9,223,372,036,854,775,808 and a maximum value of 9,223,372,036,854,775,807 (inclusive). Use this data type when you need a range of values wider than those provided by int.
As you may know from basic computer science or discrete math, there are 2^64 possible values for a long, since it is 64 bits. And as you know from discrete math or number theory or common sense, if there's only finitely many possibilities, one of them has to be the largest. That would be Long.MAX_VALUE. So you are asking something similar to "is there an integer that's >0 and < 1?" Mathematically nonsensical.
If you actually need this for something for real then use BigInteger class.
Difference between two DateTimes C#?
int hours = (int)Math.Round((b - a).TotalHours)
Pandas dataframe get first row of each group
>>> df.groupby('id').first()
value
id
1 first
2 first
3 first
4 second
5 first
6 first
7 fourth
If you need id as column:
>>> df.groupby('id').first().reset_index()
id value
0 1 first
1 2 first
2 3 first
3 4 second
4 5 first
5 6 first
6 7 fourth
To get n first records, you can use head():
>>> df.groupby('id').head(2).reset_index(drop=True)
id value
0 1 first
1 1 second
2 2 first
3 2 second
4 3 first
5 3 third
6 4 second
7 4 fifth
8 5 first
9 6 first
10 6 second
11 7 fourth
12 7 fifth
Hiding an Excel worksheet with VBA
You can do this programmatically using a VBA macro. You can make the sheet hidden or very hidden:
Sub HideSheet()
Dim sheet As Worksheet
Set sheet = ActiveSheet
' this hides the sheet but users will be able
' to unhide it using the Excel UI
sheet.Visible = xlSheetHidden
' this hides the sheet so that it can only be made visible using VBA
sheet.Visible = xlSheetVeryHidden
End Sub
How to set cursor to input box in Javascript?
In my experience
document.getElementById(frmObj.id).focus();
is good on a browser running on a PC. But on mobile if you want the keyboard to show up so the user can input directly then you also need:
document.getElementById(frmObj.id).select();
Event handlers for Twitter Bootstrap dropdowns?
Here is a working example of how you could implement custom functions for your anchors.
You can attach an id to your anchor:
<li><a id="alertMe" href="#">Action</a></li>
And then use jQuery's click event listener to listen for the click action and fire you function:
$('#alertMe').click(function(e) {
alert('alerted');
e.preventDefault();// prevent the default anchor functionality
});
Disable/Enable button in Excel/VBA
This is working for me (Excel 2016) with a new ActiveX button, assign a control to you button and you're all set.
Sub deactivate_buttons()
ActiveSheet.Shapes.Item("CommandButton1").ControlFormat.Enabled = False
End Sub
It changes the "Enabled" property in the ActiveX button Properties box to False and the button becomes inactive and greyed out.
The remote host closed the connection. The error code is 0x800704CD
I too got this same error on my image handler that I wrote. I got it like 30 times a day on site with heavy traffic, managed to reproduce it also. You get this when a user cancels the request (closes the page or his internet connection is interrupted for example), in my case in the following row:
myContext.Response.OutputStream.Write(buffer, 0, bytesRead);
I can’t think of any way to prevent it but maybe you can properly handle this. Ex:
try
{
…
myContext.Response.OutputStream.Write(buffer, 0, bytesRead);
…
}catch (HttpException ex)
{
if (ex.Message.StartsWith("The remote host closed the connection."))
;//do nothing
else
//handle other errors
}
catch (Exception e)
{
//handle other errors
}
finally
{//close streams etc..
}
How do you convert a byte array to a hexadecimal string, and vice versa?
You can use the BitConverter.ToString method:
byte[] bytes = {0, 1, 2, 4, 8, 16, 32, 64, 128, 256}
Console.WriteLine( BitConverter.ToString(bytes));
Output:
00-01-02-04-08-10-20-40-80-FF
More information: BitConverter.ToString Method (Byte[])
PHP PDO: charset, set names?
This is probably the most elegant way to do it.
Right in the PDO constructor call, but avoiding the buggy charset option (as mentioned above):
$connect = new PDO(
"mysql:host=$host;dbname=$db",
$user,
$pass,
array(
PDO::ATTR_ERRMODE => PDO::ERRMODE_EXCEPTION,
PDO::MYSQL_ATTR_INIT_COMMAND => "SET NAMES utf8"
)
);
Works great for me.
How to post JSON to PHP with curl
I believe you are getting an empty array because PHP is expecting the posted data to be in a Querystring format (key=value&key1=value1).
Try changing your curl request to:
curl -i -X POST -d 'json={"screencast":{"subject":"tools"}}' \
http://localhost:3570/index.php/trainingServer/screencast.json
and see if that helps any.
A process crashed in windows .. Crash dump location
a core dump is usually only made when the Windows kernel crashes (aka blue screen). A servicecrash will most of the times only leave some logging behind (in the event viewer probably).
If it is the bluescreen crash dump you are looking for, look in C:\Windows\Minidump or C:\windows\MEMORY.DMP
Get the new record primary key ID from MySQL insert query?
simply use "$last_id = mysqli_insert_id($conn);"
How to check the exit status using an if statement
Just to add to the helpful and detailed answer:
If you have to check the exit code explicitly, it is better to use the arithmetic operator, (( ... )), this way:
run_some_command
(($? != 0)) && { printf '%s\n' "Command exited with non-zero"; exit 1; }
Or, use a case statement:
run_some_command; ec=$? # grab the exit code into a variable so that it can
# be reused later, without the fear of being overwritten
case $ec in
0) ;;
1) printf '%s\n' "Command exited with non-zero"; exit 1;;
*) do_something_else;;
esac
Related answer about error handling in Bash:
Delete specified file from document directory
Instead of having the error set to NULL, have it set to
NSError *error;
[fileManager removeItemAtPath:filePath error:&error];
if (error){
NSLog(@"%@", error);
}
this will tell you if it's actually deleting the file
How to undo "git commit --amend" done instead of "git commit"
Find your amended commits by:
git log --reflog
Note: You may add --patch to see the body of the commits for clarity. Same as git reflog.
then reset your HEAD to any previous commit at the point it was fine by:
git reset SHA1 --hard
Note: Replace SHA1 with your real commit hash. Also note that this command will lose any uncommitted changes, so you may stash them before. Alternatively, use --soft instead to retain the latest changes and then commit them.
Then cherry-pick the other commit that you need on top of it:
git cherry-pick SHA1
How to add a constant column in a Spark DataFrame?
Spark 2.2+
Spark 2.2 introduces typedLit to support Seq, Map, and Tuples (SPARK-19254) and following calls should be supported (Scala):
import org.apache.spark.sql.functions.typedLit
df.withColumn("some_array", typedLit(Seq(1, 2, 3)))
df.withColumn("some_struct", typedLit(("foo", 1, 0.3)))
df.withColumn("some_map", typedLit(Map("key1" -> 1, "key2" -> 2)))
Spark 1.3+ (lit), 1.4+ (array, struct), 2.0+ (map):
The second argument for DataFrame.withColumn should be a Column so you have to use a literal:
from pyspark.sql.functions import lit
df.withColumn('new_column', lit(10))
If you need complex columns you can build these using blocks like array:
from pyspark.sql.functions import array, create_map, struct
df.withColumn("some_array", array(lit(1), lit(2), lit(3)))
df.withColumn("some_struct", struct(lit("foo"), lit(1), lit(.3)))
df.withColumn("some_map", create_map(lit("key1"), lit(1), lit("key2"), lit(2)))
Exactly the same methods can be used in Scala.
import org.apache.spark.sql.functions.{array, lit, map, struct}
df.withColumn("new_column", lit(10))
df.withColumn("map", map(lit("key1"), lit(1), lit("key2"), lit(2)))
To provide names for structs use either alias on each field:
df.withColumn(
"some_struct",
struct(lit("foo").alias("x"), lit(1).alias("y"), lit(0.3).alias("z"))
)
or cast on the whole object
df.withColumn(
"some_struct",
struct(lit("foo"), lit(1), lit(0.3)).cast("struct<x: string, y: integer, z: double>")
)
It is also possible, although slower, to use an UDF.
Note:
The same constructs can be used to pass constant arguments to UDFs or SQL functions.
How to implement a Boolean search with multiple columns in pandas
Easiest way to do this
if this helpful hit up arrow! Tahnks!!
students = [ ('jack1', 'Apples1' , 341) ,
('Riti1', 'Mangos1' , 311) ,
('Aadi1', 'Grapes1' , 301) ,
('Sonia1', 'Apples1', 321) ,
('Lucy1', 'Mangos1' , 331) ,
('Mike1', 'Apples1' , 351),
('Mik', 'Apples1' , np.nan)
]
#Create a DataFrame object
df = pd.DataFrame(students, columns = ['Name1' , 'Product1', 'Sale1'])
print(df)
Name1 Product1 Sale1
0 jack1 Apples1 341
1 Riti1 Mangos1 311
2 Aadi1 Grapes1 301
3 Sonia1 Apples1 321
4 Lucy1 Mangos1 331
5 Mike1 Apples1 351
6 Mik Apples1 NaN
# Select rows in above DataFrame for which ‘Product’ column contains the value ‘Apples’,
subset = df[df['Product1'] == 'Apples1']
print(subset)
Name1 Product1 Sale1
0 jack1 Apples1 341
3 Sonia1 Apples1 321
5 Mike1 Apples1 351
6 Mik Apples1 NA
# Select rows in above DataFrame for which ‘Product’ column contains the value ‘Apples’, AND notnull value in Sale
subsetx= df[(df['Product1'] == "Apples1") & (df['Sale1'].notnull())]
print(subsetx)
Name1 Product1 Sale1
0 jack1 Apples1 341
3 Sonia1 Apples1 321
5 Mike1 Apples1 351
# Select rows in above DataFrame for which ‘Product’ column contains the value ‘Apples’, AND Sale = 351
subsetx= df[(df['Product1'] == "Apples1") & (df['Sale1'] == 351)]
print(subsetx)
Name1 Product1 Sale1
5 Mike1 Apples1 351
# Another example
subsetData = df[df['Product1'].isin(['Mangos1', 'Grapes1']) ]
print(subsetData)
Name1 Product1 Sale1
1 Riti1 Mangos1 311
2 Aadi1 Grapes1 301
4 Lucy1 Mangos1 331
Here is the Original link I found this. I edit it a little bit -- https://thispointer.com/python-pandas-select-rows-in-dataframe-by-conditions-on-multiple-columns/
Changing default startup directory for command prompt in Windows 7
"start in directory" command
cmd /K cd C:\WorkSpace
but if WorkSpace happens to be on different than C drive, console will be launched in default folder and then you still need to put D: to change drive To avoid this use cd with -d parameter
cmd /K cd -d D:\WorkSpace
create a shortcut and your fixed ;)
Select * from subquery
You can select every column from that sub-query by aliasing it and adding the alias before the *:
SELECT t.*, a+b AS total_sum
FROM
(
SELECT SUM(column1) AS a, SUM(column2) AS b
FROM table
) t
how to clear localstorage,sessionStorage and cookies in javascript? and then retrieve?
There is no way to retrieve localStorage, sessionStorage or cookie values via javascript in the browser after they've been deleted via javascript.
If what you're really asking is if there is some other way (from outside the browser) to recover that data, that's a different question and the answer will entirely depend upon the specific browser and how it implements the storage of each of those types of data.
For example, Firefox stores cookies as individual files. When a cookie is deleted, its file is deleted. That means that the cookie can no longer be accessed via the browser. But, we know that from outside the browser, using system tools, the contents of deleted files can sometimes be retrieved.
If you wanted to look into this further, you'd have to discover how each browser stores each data type on each platform of interest and then explore if that type of storage has any recovery strategy.
How to remove specific substrings from a set of strings in Python?
You could do this:
import re
import string
set1={'Apple.good','Orange.good','Pear.bad','Pear.good','Banana.bad','Potato.bad'}
for x in set1:
x.replace('.good',' ')
x.replace('.bad',' ')
x = re.sub('\.good$', '', x)
x = re.sub('\.bad$', '', x)
print(x)
Run "mvn clean install" in Eclipse
If you want to open command prompt inside your eclipse, this can be a useful approach to link cmd with eclipse.
You can follow this link to get the steps in detail with screenshots. How to use cmd prompt inside Eclipse ?
I'm quoting the steps here:
Step 1: Setup a new External Configuration Tool
In the Eclipse tool go to Run -> External Tools -> External Tools Configurations option.
Step 2: Click New Launch Configuration option in Create, manage and run configuration screen
Step 3: New Configuration screen for configuring the command prompt
Step 4: Provide configuration details of the Command Prompt in the Main tab
Name: Give any name to your configuration (Here it is Command_Prompt)
Location: Location of the CMD.exe in your Windows
Working Directory: Any directory where you want to point the Command prompt
Step 5: Tick the check box Allocate console This will ensure the eclipse console is being used as the command prompt for any input or output.
Step 6: Click Run and you are there!! You will land up in the C: directory as a working directory
How do I set the default locale in the JVM?
You can set it on the command line via JVM parameters:
java -Duser.country=CA -Duser.language=fr ... com.x.Main
For further information look at Internationalization: Understanding Locale in the Java Platform - Using Locale
Difference between WebStorm and PHPStorm
There is actually a comparison of the two in the official WebStorm FAQ. However, the version history of that page shows it was last updated December 13, so I'm not sure if it's maintained.
This is an extract from the FAQs for reference:
What is WebStorm & PhpStorm?
WebStorm & PhpStorm are IDEs (Integrated Development Environment) built on top of JetBrains IntelliJ platform and narrowed for web development.
Which IDE do I need?
PhpStorm is designed to cover all needs of PHP developer including full JavaScript, CSS and HTML support. WebStorm is for hardcore JavaScript developers. It includes features PHP developer normally doesn’t need like Node.JS or JSUnit. However corresponding plugins can be installed into PhpStorm for free.
How often new vesions (sic) are going to be released?
Preliminarily, WebStorm and PhpStorm major updates will be available twice in a year. Minor (bugfix) updates are issued periodically as required.
snip
IntelliJ IDEA vs WebStorm features
IntelliJ IDEA remains JetBrains' flagship product and IntelliJ IDEA provides full JavaScript support along with all other features of WebStorm via bundled or downloadable plugins. The only thing missing is the simplified project setup.
WRONGTYPE Operation against a key holding the wrong kind of value php
I faced this issue when trying to set something to redis. The problem was that I previously used "set" method to set data with a certain key, like
$redis->set('persons', $persons)
Later I decided to change to "hSet" method, and I tried it this way
foreach($persons as $person){
$redis->hSet('persons', $person->id, $person);
}
Then I got the aforementioned error. So, what I had to do is to go to redis-cli and manually delete "persons" entry with
del persons
It simply couldn't write different data structure under existing key, so I had to delete the entry and hSet then.
Django -- Template tag in {% if %} block
Sorry for comment in an old post but if you want to use an else if statement this will help you
{% if title == source %}
Do This
{% elif title == value %}
Do This
{% else %}
Do This
{% endif %}
For more info see Django Documentation
Best way to define private methods for a class in Objective-C
You could use blocks?
@implementation MyClass
id (^createTheObject)() = ^(){ return [[NSObject alloc] init];};
NSInteger (^addEm)(NSInteger, NSInteger) =
^(NSInteger a, NSInteger b)
{
return a + b;
};
//public methods, etc.
- (NSObject) thePublicOne
{
return createTheObject();
}
@end
I'm aware this is an old question, but it's one of the first I found when I was looking for an answer to this very question. I haven't seen this solution discussed anywhere else, so let me know if there's something foolish about doing this.
Where is Android Studio layout preview?
If you want to see the live preview, in the right part of the screen you should have a button call Preview that show/hide the live preview.
If what you want is to use the WYSISYG editor mode, in the bottom of the editor there is a tab that switch between XML mode and WYSISYG mode.
This works in the same way both in IntelliJ and Android Studio.
In AVD emulator how to see sdcard folder? and Install apk to AVD?
if you are using Eclipse. You should switch to DDMS perspective from top-right corner there after selecting your device you can see folder tree. to install apk manually you can use adb command
adb install apklocation.apk
What's the difference between all the Selection Segues?
Here is a quick summary of the segues and an example for each type.
Show - Pushes the destination view controller onto the navigation stack, sliding overtop from right to left, providing a back button to return to the source - or if not embedded in a navigation controller it will be presented modally
Example: Navigating inboxes/folders in Mail
Show Detail - For use in a split view controller, replaces the detail/secondary view controller when in an expanded 2 column interface, otherwise if collapsed to 1 column it will push in a navigation controller
Example: In Messages, tapping a conversation will show the conversation details - replacing the view controller on the right when in a two column layout, or push the conversation when in a single column layout
Present Modally - Presents a view controller in various animated fashions as defined by the Presentation option, covering the previous view controller - most commonly used to present a view controller that animates up from the bottom and covers the entire screen on iPhone, or on iPad it's common to present it as a centered box that darkens the presenting view controller
Example: Selecting Touch ID & Passcode in Settings
Popover Presentation - When run on iPad, the destination appears in a popover, and tapping anywhere outside of this popover will dismiss it, or on iPhone popovers are supported as well but by default it will present the destination modally over the full screen
Example: Tapping the + button in Calendar
Custom - You may implement your own custom segue and have control over its behavior
The deprecated segues are essentially the non-adaptive equivalents of those described above. These segue types were deprecated in iOS 8: Push, Modal, Popover, Replace.
For more info, you may read over the Using Segues documentation which also explains the types of segues and how to use them in a Storyboard. Also check out Session 216 Building Adaptive Apps with UIKit from WWDC 2014. They talked about how you can build adaptive apps using these new Adaptive Segues, and they built a demo project that utilizes these segues.
Pure JavaScript: a function like jQuery's isNumeric()
function IsNumeric(val) {
return Number(parseFloat(val)) === val;
}
Where is the default log location for SharePoint/MOSS?
In Sharepoint Server 2010 they are stored here:
"c:\Program Files\Common Files\Microsoft Shared\web server extensions\14\LOGS"
To view them you can use ULS Viewer by Microsoft (unsupported). http://ulsviewer.codeplex.com/
Is optimisation level -O3 dangerous in g++?
In the early days of gcc (2.8 etc.) and in the times of egcs, and redhat 2.96 -O3 was quite buggy sometimes. But this is over a decade ago, and -O3 is not much different than other levels of optimizations (in buggyness).
It does however tend to reveal cases where people rely on undefined behavior, due to relying more strictly on the rules, and especially corner cases, of the language(s).
As a personal note, I am running production software in the financial sector for many years now with -O3 and have not yet encountered a bug that would not have been there if I would have used -O2.
By popular demand, here an addition:
-O3 and especially additional flags like -funroll-loops (not enabled by -O3) can sometimes lead to more machine code being generated. Under certain circumstances (e.g. on a cpu with exceptionally small L1 instruction cache) this can cause a slowdown due to all the code of e.g. some inner loop now not fitting anymore into L1I. Generally gcc tries quite hard to not to generate so much code, but since it usually optimizes the generic case, this can happen. Options especially prone to this (like loop unrolling) are normally not included in -O3 and are marked accordingly in the manpage. As such it is generally a good idea to use -O3 for generating fast code, and only fall back to -O2 or -Os (which tries to optimize for code size) when appropriate (e.g. when a profiler indicates L1I misses).
If you want to take optimization into the extreme, you can tweak in gcc via --param the costs associated with certain optimizations. Additionally note that gcc now has the ability to put attributes at functions that control optimization settings just for these functions, so when you find you have a problem with -O3 in one function (or want to try out special flags for just that function), you don't need to compile the whole file or even whole project with O2.
otoh it seems that care must be taken when using -Ofast, which states:
-Ofast enables all -O3 optimizations. It also enables optimizations that are not valid for all standard compliant programs.
which makes me conclude that -O3 is intended to be fully standards compliant.
Send multiple checkbox data to PHP via jQuery ajax()
Yes it's pretty work with jquery.serialize()
HTML
<form id="myform" class="myform" method="post" name="myform">
<textarea id="myField" type="text" name="myField"></textarea>
<input type="checkbox" name="myCheckboxes[]" id="myCheckboxes" value="someValue1" />
<input type="checkbox" name="myCheckboxes[]" id="myCheckboxes" value="someValue2" />
<input id="submit" type="submit" name="submit" value="Submit" onclick="return submitForm()" />
</form>
<div id="myResponse"></div>
JQuery
function submitForm() {
var form = document.myform;
var dataString = $(form).serialize();
$.ajax({
type:'POST',
url:'myurl.php',
data: dataString,
success: function(data){
$('#myResponse').html(data);
}
});
return false;
}
NOW THE PHP, i export the POST data
echo var_export($_POST);
You can see the all the checkbox value are sent.I hope it may help you
How to get a .csv file into R?
As Dirk said, the function you are after is 'read.csv' or one of the other read.table variants. Given your sample data above, I think you will want to do something like this:
setwd("c:/random/directory")
df <- read.csv("myRandomFile.csv", header=TRUE)
All we did in the above was set the directory to where your .csv file is and then read the .csv into a dataframe named df. You can check that the data loaded properly by checking the structure of the object with:
str(df)
Assuming the data loaded properly, you can think go on to perform any number of statistical methods with the data in your data frame. I think summary(df) would be a good place to start. Learning how to use the help in R will be immensely useful, and a quick read through the help on CRAN will save you lots of time in the future: http://cran.r-project.org/
How to write unit testing for Angular / TypeScript for private methods with Jasmine
This worked for me:
Instead of:
sut.myPrivateMethod();
This:
sut['myPrivateMethod']();
Multiple INNER JOIN SQL ACCESS
Access requires parentheses in the FROM clause for queries which include more than one join. Try it this way ...
FROM
((tbl_employee
INNER JOIN tbl_netpay
ON tbl_employee.emp_id = tbl_netpay.emp_id)
INNER JOIN tbl_gross
ON tbl_employee.emp_id = tbl_gross.emp_ID)
INNER JOIN tbl_tax
ON tbl_employee.emp_id = tbl_tax.emp_ID;
If possible, use the Access query designer to set up your joins. The designer will add parentheses as required to keep the db engine happy.
Returning pointer from a function
Although returning a pointer to a local object is bad practice, it didn't cause the kaboom here. Here's why you got a segfault:
int *fun()
{
int *point;
*point=12; <<<<<< your program crashed here.
return point;
}
The local pointer goes out of scope, but the real issue is dereferencing a pointer that was never initialized. What is the value of point? Who knows. If the value did not map to a valid memory location, you will get a SEGFAULT. If by luck it mapped to something valid, then you just corrupted memory by overwriting that place with your assignment to 12.
Since the pointer returned was immediately used, in this case you could get away with returning a local pointer. However, it is bad practice because if that pointer was reused after another function call reused that memory in the stack, the behavior of the program would be undefined.
int *fun()
{
int point;
point = 12;
return (&point);
}
or almost identically:
int *fun()
{
int point;
int *point_ptr;
point_ptr = &point;
*point_ptr = 12;
return (point_ptr);
}
Another bad practice but safer method would be to declare the integer value as a static variable, and it would then not be on the stack and would be safe from being used by another function:
int *fun()
{
static int point;
int *point_ptr;
point_ptr = &point;
*point_ptr = 12;
return (point_ptr);
}
or
int *fun()
{
static int point;
point = 12;
return (&point);
}
As others have mentioned, the "right" way to do this would be to allocate memory on the heap, via malloc.
How can I delete multiple lines in vi?
If you prefer a non-visual mode method and acknowledge the line numbers, I would like to suggest you an another straightforward way.
Example
I want to delete text from line 45 to line 101.
My method suggests you to type a below command in command-mode:
45Gd101G
It reads:
Go to line 45 (
45G) then delete text (d) from the current line to the line 101 (101G).
Note that on vim you might use gg in stead of G.
Compare to the @Bonnie Varghese's answer which is:
:45,101d[enter]
The command above from his answer requires 9 times typing including enter, where my answer require 8 - 10 times typing. Thus, a speed of my method is comparable.
Personally, I myself prefer 45Gd101G over :45,101d because I like to stick to the syntax of the vi's command, in this case is:
+---------+----------+--------------------+
| syntax | <motion> | <operator><motion> |
+---------+----------+--------------------+
| command | 45G | d101G |
+---------+----------+--------------------+
Measuring text height to be drawn on Canvas ( Android )
You must use Rect.width() and Rect.Height() which returned from getTextBounds() instead. That works for me.
Where is the kibana error log? Is there a kibana error log?
For kibana 6.x on Windows, edit the shortcut to "kibana -l " folder must exist.
Check Postgres access for a user
You could query the table_privileges table in the information schema:
SELECT table_catalog, table_schema, table_name, privilege_type
FROM information_schema.table_privileges
WHERE grantee = 'MY_USER'
How to save a list as numpy array in python?
you mean something like this ?
from numpy import array
a = array( your_list )
Read specific columns with pandas or other python module
According to the latest pandas documentation you can read a csv file selecting only the columns which you want to read.
import pandas as pd
df = pd.read_csv('some_data.csv', usecols = ['col1','col2'], low_memory = True)
Here we use usecols which reads only selected columns in a dataframe.
We are using low_memory so that we Internally process the file in chunks.
git - remote add origin vs remote set-url origin
below is used to a add a new remote:
git remote add origin [email protected]:User/UserRepo.git
below is used to change the url of an existing remote repository:
git remote set-url origin [email protected]:User/UserRepo.git
below will push your code to the master branch of the remote repository defined with origin and -u let you point your current local branch to the remote master branch:
git push -u origin master
MySQL set current date in a DATETIME field on insert
Your best bet is to change that column to a timestamp. MySQL will automatically use the first timestamp in a row as a 'last modified' value and update it for you. This is configurable if you just want to save creation time.
See doc http://dev.mysql.com/doc/refman/5.7/en/timestamp-initialization.html
how to sync windows time from a ntp time server in command
Use net time
net time \\timesrv /set /yes
after your comment try this one in evelated prompt :
w32tm /config /update /manualpeerlist:yourtimerserver
How to get the file-path of the currently executing javascript code
Refining upon the answers found here I came up with the following:
getCurrentScript.js
var getCurrentScript = function () {
if (document.currentScript) {
return document.currentScript.src;
} else {
var scripts = document.getElementsByTagName('script');
return scripts[scripts.length-1].src;
}
};
module.exports = getCurrentScript;
getCurrentScriptPath.js
var getCurrentScript = require('./getCurrentScript');
var getCurrentScriptPath = function () {
var script = getCurrentScript();
var path = script.substring(0, script.lastIndexOf('/'));
return path;
};
module.exports = getCurrentScriptPath;
BTW: I'm using CommonJS module format and bundling with webpack.
Javax.net.ssl.SSLHandshakeException: javax.net.ssl.SSLProtocolException: SSL handshake aborted: Failure in SSL library, usually a protocol error
I found the solution for it by analyzing the data packets using wireshark. What I found is that while making a secure connection, android was falling back to SSLv3 from TLSv1 . It is a bug in android versions < 4.4 , and it can be solved by removing the SSLv3 protocol from Enabled Protocols list. I made a custom socketFactory class called NoSSLv3SocketFactory.java. Use this to make a socketfactory.
/*Copyright 2015 Bhavit Singh Sengar
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.*/
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.InetAddress;
import java.net.Socket;
import java.net.SocketAddress;
import java.net.SocketException;
import java.nio.channels.SocketChannel;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import javax.net.ssl.HandshakeCompletedListener;
import javax.net.ssl.HttpsURLConnection;
import javax.net.ssl.SSLSession;
import javax.net.ssl.SSLSocket;
import javax.net.ssl.SSLSocketFactory;
public class NoSSLv3SocketFactory extends SSLSocketFactory{
private final SSLSocketFactory delegate;
public NoSSLv3SocketFactory() {
this.delegate = HttpsURLConnection.getDefaultSSLSocketFactory();
}
public NoSSLv3SocketFactory(SSLSocketFactory delegate) {
this.delegate = delegate;
}
@Override
public String[] getDefaultCipherSuites() {
return delegate.getDefaultCipherSuites();
}
@Override
public String[] getSupportedCipherSuites() {
return delegate.getSupportedCipherSuites();
}
private Socket makeSocketSafe(Socket socket) {
if (socket instanceof SSLSocket) {
socket = new NoSSLv3SSLSocket((SSLSocket) socket);
}
return socket;
}
@Override
public Socket createSocket(Socket s, String host, int port, boolean autoClose) throws IOException {
return makeSocketSafe(delegate.createSocket(s, host, port, autoClose));
}
@Override
public Socket createSocket(String host, int port) throws IOException {
return makeSocketSafe(delegate.createSocket(host, port));
}
@Override
public Socket createSocket(String host, int port, InetAddress localHost, int localPort) throws IOException {
return makeSocketSafe(delegate.createSocket(host, port, localHost, localPort));
}
@Override
public Socket createSocket(InetAddress host, int port) throws IOException {
return makeSocketSafe(delegate.createSocket(host, port));
}
@Override
public Socket createSocket(InetAddress address, int port, InetAddress localAddress, int localPort) throws IOException {
return makeSocketSafe(delegate.createSocket(address, port, localAddress, localPort));
}
private class NoSSLv3SSLSocket extends DelegateSSLSocket {
private NoSSLv3SSLSocket(SSLSocket delegate) {
super(delegate);
}
@Override
public void setEnabledProtocols(String[] protocols) {
if (protocols != null && protocols.length == 1 && "SSLv3".equals(protocols[0])) {
List<String> enabledProtocols = new ArrayList<String>(Arrays.asList(delegate.getEnabledProtocols()));
if (enabledProtocols.size() > 1) {
enabledProtocols.remove("SSLv3");
System.out.println("Removed SSLv3 from enabled protocols");
} else {
System.out.println("SSL stuck with protocol available for " + String.valueOf(enabledProtocols));
}
protocols = enabledProtocols.toArray(new String[enabledProtocols.size()]);
}
super.setEnabledProtocols(protocols);
}
}
public class DelegateSSLSocket extends SSLSocket {
protected final SSLSocket delegate;
DelegateSSLSocket(SSLSocket delegate) {
this.delegate = delegate;
}
@Override
public String[] getSupportedCipherSuites() {
return delegate.getSupportedCipherSuites();
}
@Override
public String[] getEnabledCipherSuites() {
return delegate.getEnabledCipherSuites();
}
@Override
public void setEnabledCipherSuites(String[] suites) {
delegate.setEnabledCipherSuites(suites);
}
@Override
public String[] getSupportedProtocols() {
return delegate.getSupportedProtocols();
}
@Override
public String[] getEnabledProtocols() {
return delegate.getEnabledProtocols();
}
@Override
public void setEnabledProtocols(String[] protocols) {
delegate.setEnabledProtocols(protocols);
}
@Override
public SSLSession getSession() {
return delegate.getSession();
}
@Override
public void addHandshakeCompletedListener(HandshakeCompletedListener listener) {
delegate.addHandshakeCompletedListener(listener);
}
@Override
public void removeHandshakeCompletedListener(HandshakeCompletedListener listener) {
delegate.removeHandshakeCompletedListener(listener);
}
@Override
public void startHandshake() throws IOException {
delegate.startHandshake();
}
@Override
public void setUseClientMode(boolean mode) {
delegate.setUseClientMode(mode);
}
@Override
public boolean getUseClientMode() {
return delegate.getUseClientMode();
}
@Override
public void setNeedClientAuth(boolean need) {
delegate.setNeedClientAuth(need);
}
@Override
public void setWantClientAuth(boolean want) {
delegate.setWantClientAuth(want);
}
@Override
public boolean getNeedClientAuth() {
return delegate.getNeedClientAuth();
}
@Override
public boolean getWantClientAuth() {
return delegate.getWantClientAuth();
}
@Override
public void setEnableSessionCreation(boolean flag) {
delegate.setEnableSessionCreation(flag);
}
@Override
public boolean getEnableSessionCreation() {
return delegate.getEnableSessionCreation();
}
@Override
public void bind(SocketAddress localAddr) throws IOException {
delegate.bind(localAddr);
}
@Override
public synchronized void close() throws IOException {
delegate.close();
}
@Override
public void connect(SocketAddress remoteAddr) throws IOException {
delegate.connect(remoteAddr);
}
@Override
public void connect(SocketAddress remoteAddr, int timeout) throws IOException {
delegate.connect(remoteAddr, timeout);
}
@Override
public SocketChannel getChannel() {
return delegate.getChannel();
}
@Override
public InetAddress getInetAddress() {
return delegate.getInetAddress();
}
@Override
public InputStream getInputStream() throws IOException {
return delegate.getInputStream();
}
@Override
public boolean getKeepAlive() throws SocketException {
return delegate.getKeepAlive();
}
@Override
public InetAddress getLocalAddress() {
return delegate.getLocalAddress();
}
@Override
public int getLocalPort() {
return delegate.getLocalPort();
}
@Override
public SocketAddress getLocalSocketAddress() {
return delegate.getLocalSocketAddress();
}
@Override
public boolean getOOBInline() throws SocketException {
return delegate.getOOBInline();
}
@Override
public OutputStream getOutputStream() throws IOException {
return delegate.getOutputStream();
}
@Override
public int getPort() {
return delegate.getPort();
}
@Override
public synchronized int getReceiveBufferSize() throws SocketException {
return delegate.getReceiveBufferSize();
}
@Override
public SocketAddress getRemoteSocketAddress() {
return delegate.getRemoteSocketAddress();
}
@Override
public boolean getReuseAddress() throws SocketException {
return delegate.getReuseAddress();
}
@Override
public synchronized int getSendBufferSize() throws SocketException {
return delegate.getSendBufferSize();
}
@Override
public int getSoLinger() throws SocketException {
return delegate.getSoLinger();
}
@Override
public synchronized int getSoTimeout() throws SocketException {
return delegate.getSoTimeout();
}
@Override
public boolean getTcpNoDelay() throws SocketException {
return delegate.getTcpNoDelay();
}
@Override
public int getTrafficClass() throws SocketException {
return delegate.getTrafficClass();
}
@Override
public boolean isBound() {
return delegate.isBound();
}
@Override
public boolean isClosed() {
return delegate.isClosed();
}
@Override
public boolean isConnected() {
return delegate.isConnected();
}
@Override
public boolean isInputShutdown() {
return delegate.isInputShutdown();
}
@Override
public boolean isOutputShutdown() {
return delegate.isOutputShutdown();
}
@Override
public void sendUrgentData(int value) throws IOException {
delegate.sendUrgentData(value);
}
@Override
public void setKeepAlive(boolean keepAlive) throws SocketException {
delegate.setKeepAlive(keepAlive);
}
@Override
public void setOOBInline(boolean oobinline) throws SocketException {
delegate.setOOBInline(oobinline);
}
@Override
public void setPerformancePreferences(int connectionTime, int latency, int bandwidth) {
delegate.setPerformancePreferences(connectionTime, latency, bandwidth);
}
@Override
public synchronized void setReceiveBufferSize(int size) throws SocketException {
delegate.setReceiveBufferSize(size);
}
@Override
public void setReuseAddress(boolean reuse) throws SocketException {
delegate.setReuseAddress(reuse);
}
@Override
public synchronized void setSendBufferSize(int size) throws SocketException {
delegate.setSendBufferSize(size);
}
@Override
public void setSoLinger(boolean on, int timeout) throws SocketException {
delegate.setSoLinger(on, timeout);
}
@Override
public synchronized void setSoTimeout(int timeout) throws SocketException {
delegate.setSoTimeout(timeout);
}
@Override
public void setTcpNoDelay(boolean on) throws SocketException {
delegate.setTcpNoDelay(on);
}
@Override
public void setTrafficClass(int value) throws SocketException {
delegate.setTrafficClass(value);
}
@Override
public void shutdownInput() throws IOException {
delegate.shutdownInput();
}
@Override
public void shutdownOutput() throws IOException {
delegate.shutdownOutput();
}
@Override
public String toString() {
return delegate.toString();
}
@Override
public boolean equals(Object o) {
return delegate.equals(o);
}
}
}
Use this class like this while connecting :
SSLContext sslcontext = SSLContext.getInstance("TLSv1");
sslcontext.init(null, null, null);
SSLSocketFactory NoSSLv3Factory = new NoSSLv3SocketFactory(sslcontext.getSocketFactory());
HttpsURLConnection.setDefaultSSLSocketFactory(NoSSLv3Factory);
l_connection = (HttpsURLConnection) l_url.openConnection();
l_connection.connect();
UPDATE :
Now, correct solution would be to install a newer security provider using Google Play Services:
ProviderInstaller.installIfNeeded(getApplicationContext());
This effectively gives your app access to a newer version of OpenSSL and Java Security Provider, which includes support for TLSv1.2 in SSLEngine. Once the new provider is installed, you can create an SSLEngine which supports SSLv3, TLSv1, TLSv1.1 and TLSv1.2 the usual way:
SSLContext sslContext = SSLContext.getInstance("TLSv1.2");
sslContext.init(null, null, null);
SSLEngine engine = sslContext.createSSLEngine();
Or you can restrict the enabled protocols using engine.setEnabledProtocols.
Don't forget to add the following dependency (check the latest version here):
implementation 'com.google.android.gms:play-services-auth:17.0.0'
For more info, checkout this link.
Regex Named Groups in Java
(Update: August 2011)
As geofflane mentions in his answer, Java 7 now support named groups.
tchrist points out in the comment that the support is limited.
He details the limitations in his great answer "Java Regex Helper"
Java 7 regex named group support was presented back in September 2010 in Oracle's blog.
In the official release of Java 7, the constructs to support the named capturing group are:
(?<name>capturing text)to define a named group "name"\k<name>to backreference a named group "name"${name}to reference to captured group in Matcher's replacement stringMatcher.group(String name)to return the captured input subsequence by the given "named group".
Other alternatives for pre-Java 7 were:
- Google named-regex (see John Hardy's answer)
Gábor Lipták mentions (November 2012) that this project might not be active (with several outstanding bugs), and its GitHub fork could be considered instead. - jregex (See Brian Clozel's answer)
(Original answer: Jan 2009, with the next two links now broken)
You can not refer to named group, unless you code your own version of Regex...
That is precisely what Gorbush2 did in this thread.
(limited implementation, as pointed out again by tchrist, as it looks only for ASCII identifiers. tchrist details the limitation as:
only being able to have one named group per same name (which you don’t always have control over!) and not being able to use them for in-regex recursion.
Note: You can find true regex recursion examples in Perl and PCRE regexes, as mentioned in Regexp Power, PCRE specs and Matching Strings with Balanced Parentheses slide)
Example:
String:
"TEST 123"
RegExp:
"(?<login>\\w+) (?<id>\\d+)"
Access
matcher.group(1) ==> TEST
matcher.group("login") ==> TEST
matcher.name(1) ==> login
Replace
matcher.replaceAll("aaaaa_$1_sssss_$2____") ==> aaaaa_TEST_sssss_123____
matcher.replaceAll("aaaaa_${login}_sssss_${id}____") ==> aaaaa_TEST_sssss_123____
(extract from the implementation)
public final class Pattern
implements java.io.Serializable
{
[...]
/**
* Parses a group and returns the head node of a set of nodes that process
* the group. Sometimes a double return system is used where the tail is
* returned in root.
*/
private Node group0() {
boolean capturingGroup = false;
Node head = null;
Node tail = null;
int save = flags;
root = null;
int ch = next();
if (ch == '?') {
ch = skip();
switch (ch) {
case '<': // (?<xxx) look behind or group name
ch = read();
int start = cursor;
[...]
// test forGroupName
int startChar = ch;
while(ASCII.isWord(ch) && ch != '>') ch=read();
if(ch == '>'){
// valid group name
int len = cursor-start;
int[] newtemp = new int[2*(len) + 2];
//System.arraycopy(temp, start, newtemp, 0, len);
StringBuilder name = new StringBuilder();
for(int i = start; i< cursor; i++){
name.append((char)temp[i-1]);
}
// create Named group
head = createGroup(false);
((GroupTail)root).name = name.toString();
capturingGroup = true;
tail = root;
head.next = expr(tail);
break;
}
Placeholder Mixin SCSS/CSS
I use exactly the same sass mixin placeholder as NoDirection wrote. I find it in sass mixins collection here and I'm very satisfied with it. There's a text that explains a mixins option more.
Why am I getting "IndentationError: expected an indented block"?
I had this same problem and discovered (via this answer to a similar question) that the problem was that I didn't properly indent the docstring properly. Unfortunately IDLE doesn't give useful feedback here, but once I fixed the docstring indentation, the problem went away.
Specifically --- bad code that generates indentation errors:
def my_function(args):
"Here is my docstring"
....
Good code that avoids indentation errors:
def my_function(args):
"Here is my docstring"
....
Note: I'm not saying this is the problem, but that it might be, because in my case, it was!
Update records using LINQ
I assume person_id is the primary key of Person table, so here's how you update a single record:
Person result = (from p in Context.Persons
where p.person_id == 5
select p).SingleOrDefault();
result.is_default = false;
Context.SaveChanges();
and here's how you update multiple records:
List<Person> results = (from p in Context.Persons
where .... // add where condition here
select p).ToList();
foreach (Person p in results)
{
p.is_default = false;
}
Context.SaveChanges();
Font scaling based on width of container
My own solution, jQuery-based, works by gradually increasing the font size until the container gets a big increase in height (meaning it got a line break).
It's pretty simple, but works fairly well, and it is very easy to use. You don't have to know anything about the font being used, everything is taken care of by the browser.
You can play with it on http://jsfiddle.net/tubededentifrice/u5y15d0L/2/
The magic happens here:
var setMaxTextSize=function(jElement) {
// Get and set the font size into data for reuse upon resize
var fontSize=parseInt(jElement.data(quickFitFontSizeData)) || parseInt(jElement.css("font-size"));
jElement.data(quickFitFontSizeData, fontSize);
// Gradually increase font size until the element gets a big increase in height (i.e. line break)
var i = 0;
var previousHeight;
do
{
previousHeight=jElement.height();
jElement.css("font-size", "" + (++fontSize) + "px");
}
while(i++ < 300 && jElement.height()-previousHeight < fontSize/2)
// Finally, go back before the increase in height and set the element as resized by adding quickFitSetClass
fontSize -= 1;
jElement.addClass(quickFitSetClass).css("font-size", "" + fontSize + "px");
return fontSize;
};
Convert DataTable to CSV stream
BFree's answer worked for me. I needed to post the stream right to the browser. Which I'd imagine is a common alternative. I added the following to BFree's Main() code to do this:
//StreamReader reader = new StreamReader(stream);
//Console.WriteLine(reader.ReadToEnd());
string fileName = "fileName.csv";
HttpContext.Current.Response.ContentType = "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet";
HttpContext.Current.Response.AddHeader("content-disposition", string.Format("attachment;filename={0}", fileName));
stream.Position = 0;
stream.WriteTo(HttpContext.Current.Response.OutputStream);
Error sending json in POST to web API service
In the HTTP request you need to set Content-Type to: Content-Type: application/json
So if you're using fiddler client add Content-Type: application/json to the request header
rejected master -> master (non-fast-forward)
WARNING:
Going for a 'git pull' is not ALWAYS a solution, so be carefull. You may face this problem (the one that is mentioned in the Q) if you have intentionally changed your repository history. In that case, git is confusing your history changes with new changes in your remote repo. So, you should go for a git push --force, because calling git pull will undo all of the changes you made to your history, intentionally.
Is it possible to format an HTML tooltip (title attribute)?
Not sure if it works with all browsers or 3rd party tools, but I have had success just specifying "\n" in tooltips for newline, works with dhtmlx in at least ie11, firefox and chrome
for (var key in oPendingData) {
var obj = oPendingData[key];
this.cells(sRowID, nColInd).cell.title += "\n" + obj["ChangeUser"] + ": " + obj[sCol];
}
C pass int array pointer as parameter into a function
The argument of func is accepting double-pointer variable. Hope this helps...
#include <stdio.h>
int func(int **B){
}
int main(void){
int *B[10];
func(B);
return 0;
}
SyntaxError: cannot assign to operator
Instead of ((t[1])/length) * t[1] += string, you should use string += ((t[1])/length) * t[1]. (The other syntax issue - int is not iterable - will be your exercise to figure out.)
VB.Net Properties - Public Get, Private Set
I'm not sure what the minimum required version of Visual Studio is, but in VS2015 you can use
Public ReadOnly Property Name As String
It is read-only for public access but can be privately modified using _Name
How do I force git to use LF instead of CR+LF under windows?
Context
If you
- want to force all users to have LF line endings for text files and
- you cannot ensure that all users change their git config,
you can do that starting with git 2.10. 2.10 or later is required, because 2.10 fixed the behavior of text=auto together with eol=lf. Source.
Solution
Put a .gitattributes file in the root of your git repository having following contents:
* text=auto eol=lf
Commit it.
Optional tweaks
You can also add an .editorconfig in the root of your repository to ensure that modern tooling creates new files with the desired line endings.
# EditorConfig is awesome: http://EditorConfig.org
# top-most EditorConfig file
root = true
# Unix-style newlines with a newline ending every file
[*]
end_of_line = lf
insert_final_newline = true
Filtering Pandas Dataframe using OR statement
You can do like below to achieve your result:
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
....
....
#use filter with plot
#or
fg=sns.factorplot('Retailer country', data=df1[(df1['Retailer country']=='United States') | (df1['Retailer country']=='France')], kind='count')
fg.set_xlabels('Retailer country')
plt.show()
#also
#and
fg=sns.factorplot('Retailer country', data=df1[(df1['Retailer country']=='United States') & (df1['Year']=='2013')], kind='count')
fg.set_xlabels('Retailer country')
plt.show()
C# testing to see if a string is an integer?
I think that I remember looking at a performance comparison between int.TryParse and int.Parse Regex and char.IsNumber and char.IsNumber was fastest. At any rate, whatever the performance, here's one more way to do it.
bool isNumeric = true;
foreach (char c in "12345")
{
if (!Char.IsNumber(c))
{
isNumeric = false;
break;
}
}
Remove the newline character in a list read from a file
Here are various optimisations and applications of proper Python style to make your code a lot neater. I've put in some optional code using the csv module, which is more desirable than parsing it manually. I've also put in a bit of namedtuple goodness, but I don't use the attributes that then provides. Names of the parts of the namedtuple are inaccurate, you'll need to correct them.
import csv
from collections import namedtuple
from time import localtime, strftime
# Method one, reading the file into lists manually (less desirable)
with open('grades.dat') as files:
grades = [[e.strip() for e in s.split(',')] for s in files]
# Method two, using csv and namedtuple
StudentRecord = namedtuple('StudentRecord', 'id, lastname, firstname, something, homework1, homework2, homework3, homework4, homework5, homework6, homework7, exam1, exam2, exam3')
grades = map(StudentRecord._make, csv.reader(open('grades.dat')))
# Now you could have student.id, student.lastname, etc.
# Skipping the namedtuple, you could do grades = map(tuple, csv.reader(open('grades.dat')))
request = open('requests.dat', 'w')
cont = 'y'
while cont.lower() == 'y':
answer = raw_input('Please enter the Student I.D. of whom you are looking: ')
for student in grades:
if answer == student[0]:
print '%s, %s %s %s' % (student[1], student[2], student[0], student[3])
time = strftime('%a, %b %d %Y %H:%M:%S', localtime())
print time
print 'Exams - %s, %s, %s' % student[11:14]
print 'Homework - %s, %s, %s, %s, %s, %s, %s' % student[4:11]
total = sum(int(x) for x in student[4:14])
print 'Total points earned - %d' % total
grade = total / 5.5
if grade >= 90:
letter = 'an A'
elif grade >= 80:
letter = 'a B'
elif grade >= 70:
letter = 'a C'
elif grade >= 60:
letter = 'a D'
else:
letter = 'an F'
if letter = 'an A':
print 'Grade: %s, that is equal to %s.' % (grade, letter)
else:
print 'Grade: %.2f, that is equal to %s.' % (grade, letter)
request.write('%s %s, %s %s\n' % (student[0], student[1], student[2], time))
print
cont = raw_input('Would you like to search again? ')
print 'Goodbye.'
Not able to access adb in OS X through Terminal, "command not found"
I couldn't get the stupid path working so I created an alias for abd
alias abd ="~/Library/Android/sdk/platform-tools/adb"
works fine.
Spark RDD to DataFrame python
Try if that works
sc = spark.sparkContext
# Infer the schema, and register the DataFrame as a table.
schemaPeople = spark.createDataFrame(RddName)
schemaPeople.createOrReplaceTempView("RddName")
Python strptime() and timezones?
Since strptime returns a datetime object which has tzinfo attribute, We can simply replace it with desired timezone.
>>> import datetime
>>> date_time_str = '2018-06-29 08:15:27.243860'
>>> date_time_obj = datetime.datetime.strptime(date_time_str, '%Y-%m-%d %H:%M:%S.%f').replace(tzinfo=datetime.timezone.utc)
>>> date_time_obj.tzname()
'UTC'
Call a function on click event in Angular 2
Exact transfer to Angular2+ is as below:
<button (click)="myFunc()"></button>
also in your component file:
import { Component, OnInit } from "@angular/core";
@Component({
templateUrl:"button.html" //this is the component which has the above button html
})
export class App implements OnInit{
constructor(){}
ngOnInit(){
}
myFunc(){
console.log("function called");
}
}
Android Fragments and animation
As for me, i need the view diraction:
in -> swipe from right
out -> swipe to left
Here works for me code:
slide_in_right.xml
<set xmlns:android="http://schemas.android.com/apk/res/android">
<translate android:fromXDelta="50%p" android:toXDelta="0"
android:duration="@android:integer/config_mediumAnimTime"/>
<alpha android:fromAlpha="0.0" android:toAlpha="1.0"
android:duration="@android:integer/config_mediumAnimTime" />
</set>
slide_out_left.xml
<set xmlns:android="http://schemas.android.com/apk/res/android">
<translate android:fromXDelta="0" android:toXDelta="-50%p"
android:duration="@android:integer/config_mediumAnimTime"/>
<alpha android:fromAlpha="1.0" android:toAlpha="0.0"
android:duration="@android:integer/config_mediumAnimTime" />
</set>
transaction code:
inline fun FragmentActivity.setContentFragment(
containerViewId: Int,
backStack: Boolean = false,
isAnimate: Boolean = false,
f: () -> Fragment
): Fragment? {
val manager = supportFragmentManager
return f().apply {
manager.beginTransaction().let {
if (isAnimate)
it.setCustomAnimations(R.anim.slide_in_right, R.anim.slide_out_left)
if (backStack) {
it.replace(containerViewId, this, "Fr").addToBackStack("Fr").commit()
} else {
it.replace(containerViewId, this, "Fr").commit()
}
}
}
}
How do I determine the size of my array in C?
sizeof(array) / sizeof(array[0])
How to write a PHP ternary operator
echo ($result ->vocation == 1) ? 'Sorcerer'
: ($result->vocation == 2) ? 'Druid'
: ($result->vocation == 3) ? 'Paladin'
....
;
It’s kind of ugly. You should stick with normal if statements.
How to query MongoDB with "like"?
You would use regex for that in mongo.
e.g:
db.users.find({"name": /^m/})
Convert this string to datetime
Use DateTime::createFromFormat
$date = date_create_from_format('d/m/Y:H:i:s', $s);
$date->getTimestamp();
Injection of autowired dependencies failed;
The error shows that com.bd.service.ArticleService is not a registered bean. Add the packages in which you have beans that will be autowired in your application context:
<context:component-scan base-package="com.bd.service"/>
<context:component-scan base-package="com.bd.controleur"/>
Alternatively, if you want to include all subpackages in com.bd:
<context:component-scan base-package="com.bd">
<context:include-filter type="aspectj" expression="com.bd.*" />
</context:component-scan>
As a side note, if you're using Spring 3.1 or later, you can take advantage of the @ComponentScan annotation, so that you don't have to use any xml configuration regarding component-scan. Use it in conjunction with @Configuration.
@Controller
@RequestMapping("/Article/GererArticle")
@Configuration
@ComponentScan("com.bd.service") // No need to include component-scan in xml
public class ArticleControleur {
@Autowired
ArticleService articleService;
...
}
You might find this Spring in depth section on Autowiring useful.
Is it good practice to make the constructor throw an exception?
Throwing exceptions in a constructor is not bad practice. In fact, it is the only reasonable way for a constructor to indicate that there is a problem; e.g. that the parameters are invalid.
I also think that throwing checked exceptions can be OK1, assuming that the checked exception is 1) declared, 2) specific to the problem you are reporting, and 3) it is reasonable to expect the caller to deal with a checked exception for this2.
However explicitly declaring or throwing java.lang.Exception is almost always bad practice.
You should pick an exception class that matches the exceptional condition that has occurred. If you throw Exception it is difficult for the caller to separate this exception from any number of other possible declared and undeclared exceptions. This makes error recovery difficult, and if the caller chooses to propagate the Exception, the problem just spreads.
1 - Some people may disagree, but IMO there is no substantive difference between this case and the case of throwing exceptions in methods. The standard checked vs unchecked advice applies equally to both cases.
2 - For example, the existing FileInputStream constructors will throw FileNotFoundException if you try to open a file that does not exist. Assuming that it is reasonable for FileNotFoundException to be a checked exception3, then the constructor is the most appropriate place for that exception to be thrown. If we threw the FileNotFoundException the first time that (say) a read or write call was made, that is liable to make application logic more complicated.
3 - Given that this is one of the motivating examples for checked exceptions, if you don't accept this you are basically saying that all exceptions should be unchecked. That is not practical ... if you are going to use Java.
Someone suggested using assert for checking arguments. The problem with this is that checking of assert assertions can be turned on and off via a JVM command-line setting. Using assertions to check internal invariants is OK, but using them to implement argument checking that is specified in your javadoc is not a good idea ... because it means your method will only strictly implement the specification when assertion checking is enabled.
The second problem with assert is that if an assertion fails, then AssertionError will be thrown, and received wisdom is that it is a bad idea to attempt to catch Error and any of its subtypes.
SOAP-ERROR: Parsing WSDL: Couldn't load from <URL>
I got the same error
Could not connect to the Magento WebService API: SOAP-ERROR: Parsing WSDL: Couldn't load from 'example.com/api/soap/?wsdl' : failed to load external entity "example.com/api/soap/?wsdl"
and my issue resolved once I update my Magento Root URL to
example.com/index.php/api/soap/?wsdl
Yes, I was missing index.php that causes the error.
Eclipse gives “Java was started but returned exit code 13”
Check you PATH environment variable once. Make sure the correct location of your JDK is specified there.
Hyper-V: Create shared folder between host and guest with internal network
Share Files, Folders or Drives Between Host and Hyper-V Virtual Machine
Prerequisites
Ensure that Enhanced session mode settings are enabled on the Hyper-V host.
Start Hyper-V Manager, and in the Actions section, select "Hyper-V Settings".
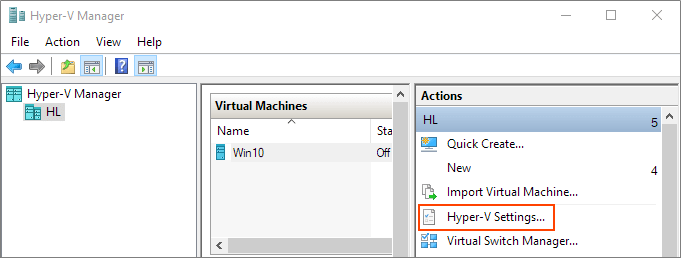
Make sure that enhanced session mode is allowed in the Server section. Then, make sure that the enhanced session mode is available in the User section.
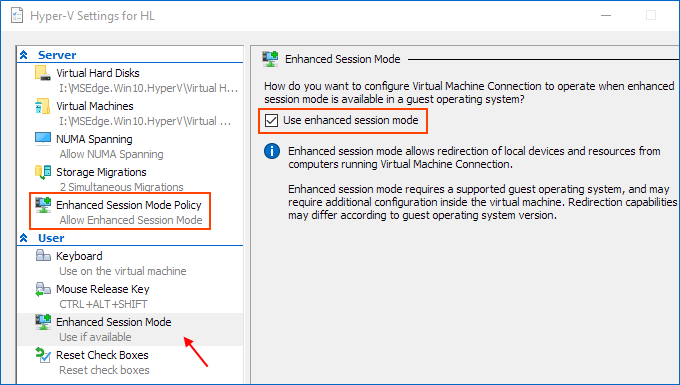
Enable Hyper-V Guest Services for your virtual machine
Right-click on Virtual Machine > Settings. Select the Integration Services in the left-lower corner of the menu. Check Guest Service and click OK.
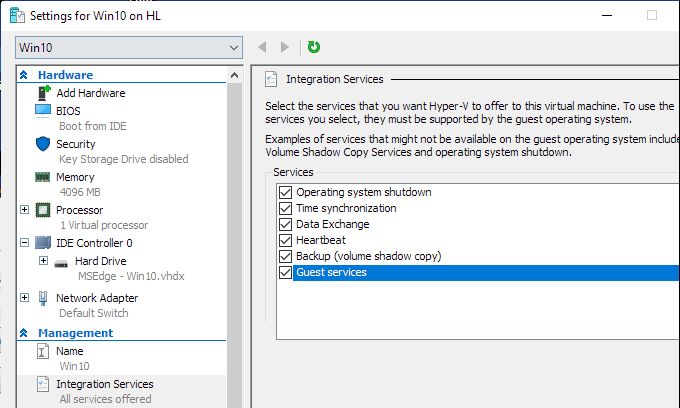
Steps to share devices with Hyper-v virtual machine:
Start a virtual machine and click Show Options in the pop-up windows.
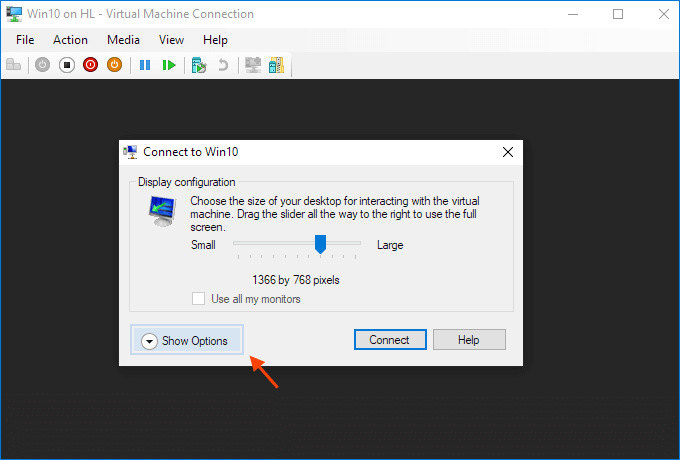
Or click "Edit Session Settings..." in the Actions panel on the right

It may only appear when you're (able to get) connected to it. If it doesn't appear try Starting and then Connecting to the VM while paying close attention to the panel in the Hyper-V Manager.
View local resources. Then, select the "More..." menu.
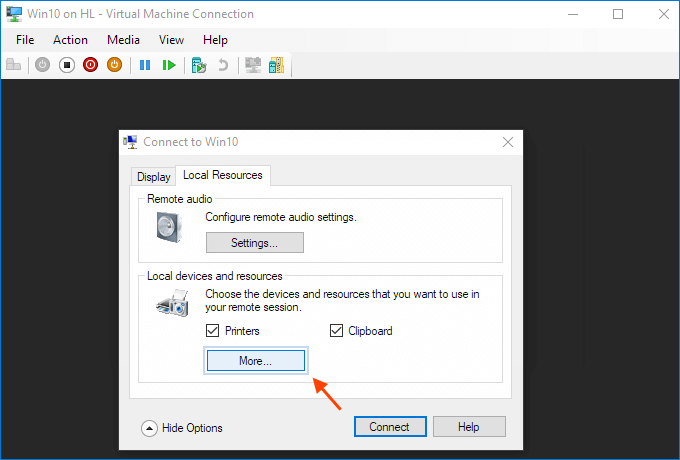
From there, you can choose which devices to share. Removable drives are especially useful for file sharing.
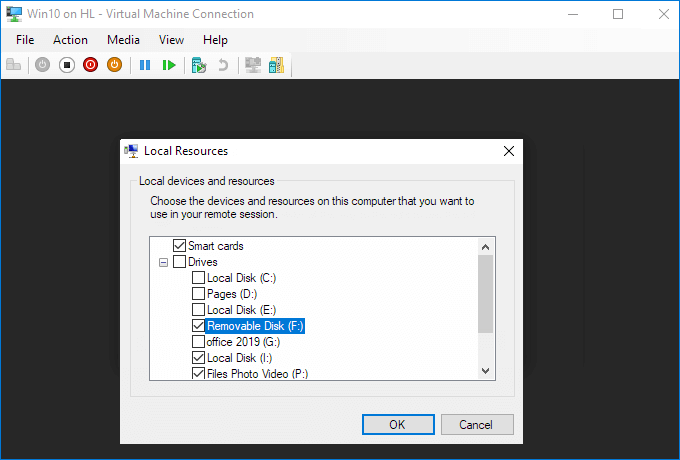
Choose to "Save my settings for future connections to this virtual machine".
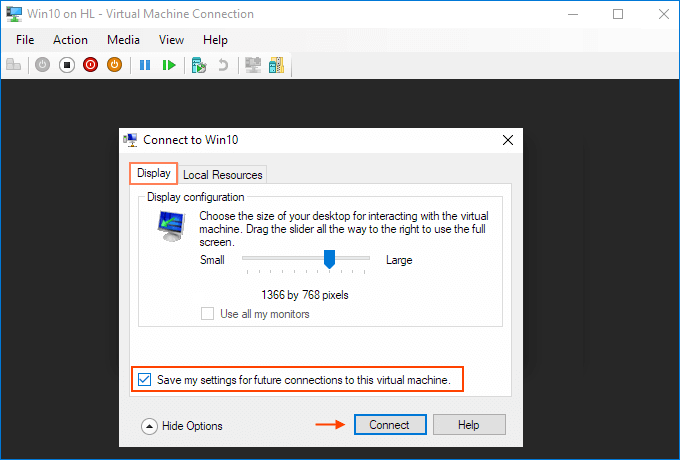
Click Connect. Drive sharing is now complete, and you will see the shared drive in this PC > Network Locations section of Windows Explorer after using the enhanced session mode to sigh to the VM. You should now be able to copy files from a physical machine and paste them into a virtual machine, and vice versa.
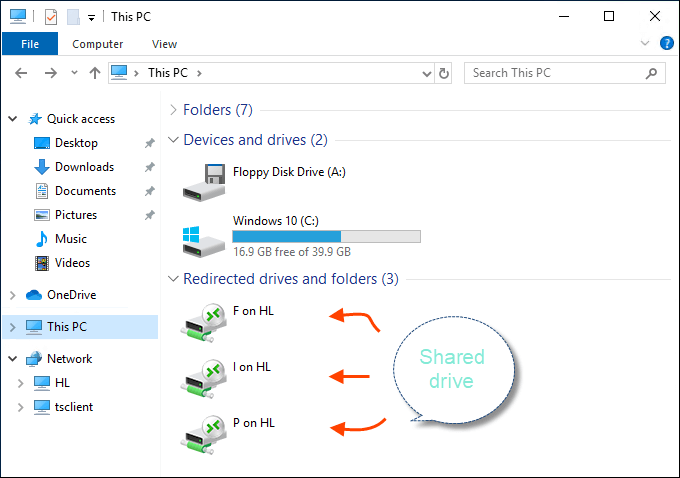
Source (and for more info): Share Files, Folders or Drives Between Host and Hyper-V Virtual Machine
Best way to structure a tkinter application?
This isn't a bad structure; it will work just fine. However, you do have to have functions in a function to do commands when someone clicks on a button or something
So what you could do is write classes for these then have methods in the class that handle commands for the button clicks and such.
Here's an example:
import tkinter as tk
class Window1:
def __init__(self, master):
pass
# Create labels, entries,buttons
def button_click(self):
pass
# If button is clicked, run this method and open window 2
class Window2:
def __init__(self, master):
#create buttons,entries,etc
def button_method(self):
#run this when button click to close window
self.master.destroy()
def main(): #run mianloop
root = tk.Tk()
app = Window1(root)
root.mainloop()
if __name__ == '__main__':
main()
Usually tk programs with multiple windows are multiple big classes and in the __init__ all the entries, labels etc are created and then each method is to handle button click events
There isn't really a right way to do it, whatever works for you and gets the job done as long as its readable and you can easily explain it because if you cant easily explain your program, there probably is a better way to do it.
Take a look at Thinking in Tkinter.
How to get number of rows inserted by a transaction
You can use @@trancount in MSSQL
From the documentation:
Returns the number of BEGIN TRANSACTION statements that have occurred on the current connection.
Is embedding background image data into CSS as Base64 good or bad practice?
Thanks for the information here. I am finding this embedding useful and particularly for mobile especially with the embedded images' css file being cached.
To help make life easier, as my file editor(s) do not natively handle this, I made a couple of simple scripts for laptop/desktop editing work, share here in case they are any use to any one else. I have stuck with php as it is handling these things directly and very well.
Under Windows 8.1 say---
C:\Users\`your user name`\AppData\Roaming\Microsoft\Windows\SendTo
... there as an Administrator you can establish a shortcut to a batch file in your path. That batch file will call a php (cli) script.
You can then right click an image in file explorer, and SendTo the batchfile.
Ok Admiinstartor request, and wait for the black command shell windows to close.
Then just simply paste the result from clipboard in your into your text editor...
<img src="|">
or
`background-image : url("|")`
Following should be adaptable for other OS.
Batch file...
rem @echo 0ff
rem Puts 64 encoded version of a file on clipboard
php c:\utils\php\make64Encode.php %1
And with php.exe in your path, that calls a php (cli) script...
<?php
function putClipboard($text){
// Windows 8.1 workaround ...
file_put_contents("output.txt", $text);
exec(" clip < output.txt");
}
// somewhat based on http://perishablepress.com/php-encode-decode-data-urls/
// convert image to dataURL
$img_source = $argv[1]; // image path/name
$img_binary = fread(fopen($img_source, "r"), filesize($img_source));
$img_string = base64_encode($img_binary);
$finfo = finfo_open(FILEINFO_MIME_TYPE);
$dataType = finfo_file($finfo, $img_source);
$build = "data:" . $dataType . ";base64," . $img_string;
putClipboard(trim($build));
?>
Get all dates between two dates in SQL Server
DECLARE @FirstDate DATE = '2018-01-01'
DECLARE @LastDate Date = '2018-12-31'
DECLARE @tbl TABLE(ID INT IDENTITY(1,1) PRIMARY KEY,CurrDate date)
INSERT @tbl VALUES( @FirstDate)
WHILE @FirstDate < @LastDate
BEGIN
SET @FirstDate = DATEADD( day,1, @FirstDate)
INSERT @tbl VALUES( @FirstDate)
END
INSERT @tbl VALUES( @LastDate)
SELECT * FROM @tbl
How to open a new HTML page using jQuery?
If you want to use jQuery, the .load() function is the correct function you are after;
But you are missing the # from the div1 id selector in the example 2)
This should work:
$("#div1").load("file2.html");
Can I get image from canvas element and use it in img src tag?
I'm getting
SecurityError: The operation is insecure.
when using canvas.toDataURL('image/jpg'); in safari browser
How to get the text of the selected value of a dropdown list?
The easiest way is through css3 $("select option:selected") and then use the .text() or .html() function. depending on what you want to have.
Display PDF within web browser
I use Google Docs embeddable PDF viewer. The docs don't have to be uploaded to Google Docs, but they do have to be available online.
<iframe src="http://docs.google.com/gview?url=http://path.com/to/your/pdf.pdf&embedded=true"
style="width:600px; height:500px;" frameborder="0"></iframe>
How to determine CPU and memory consumption from inside a process?
Linux
A portable way of reading memory and load numbers is the sysinfo call
Usage
#include <sys/sysinfo.h>
int sysinfo(struct sysinfo *info);
DESCRIPTION
Until Linux 2.3.16, sysinfo() used to return information in the
following structure:
struct sysinfo {
long uptime; /* Seconds since boot */
unsigned long loads[3]; /* 1, 5, and 15 minute load averages */
unsigned long totalram; /* Total usable main memory size */
unsigned long freeram; /* Available memory size */
unsigned long sharedram; /* Amount of shared memory */
unsigned long bufferram; /* Memory used by buffers */
unsigned long totalswap; /* Total swap space size */
unsigned long freeswap; /* swap space still available */
unsigned short procs; /* Number of current processes */
char _f[22]; /* Pads structure to 64 bytes */
};
and the sizes were given in bytes.
Since Linux 2.3.23 (i386), 2.3.48 (all architectures) the structure
is:
struct sysinfo {
long uptime; /* Seconds since boot */
unsigned long loads[3]; /* 1, 5, and 15 minute load averages */
unsigned long totalram; /* Total usable main memory size */
unsigned long freeram; /* Available memory size */
unsigned long sharedram; /* Amount of shared memory */
unsigned long bufferram; /* Memory used by buffers */
unsigned long totalswap; /* Total swap space size */
unsigned long freeswap; /* swap space still available */
unsigned short procs; /* Number of current processes */
unsigned long totalhigh; /* Total high memory size */
unsigned long freehigh; /* Available high memory size */
unsigned int mem_unit; /* Memory unit size in bytes */
char _f[20-2*sizeof(long)-sizeof(int)]; /* Padding to 64 bytes */
};
and the sizes are given as multiples of mem_unit bytes.
How to access the contents of a vector from a pointer to the vector in C++?
vector<int> v;
v.push_back(906);
vector<int> * p = &v;
cout << (*p)[0] << endl;
Error Code: 1290. The MySQL server is running with the --secure-file-priv option so it cannot execute this statement
The code above exports data without the heading columns which is weird. Here's how to do it. You have to merge the two files later though using text a editor.
SELECT column_name FROM information_schema.columns WHERE table_schema = 'my_app_db' AND table_name = 'customers' INTO OUTFILE 'C:/ProgramData/MySQL/MySQL Server 5.6/Uploads/customers_heading_cols.csv' FIELDS TERMINATED BY '' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY ',';
How to find the minimum value in an ArrayList, along with the index number? (Java)
try this:
public int getIndexOfMin(List<Float> data) {
float min = Float.MAX_VALUE;
int index = -1;
for (int i = 0; i < data.size(); i++) {
Float f = data.get(i);
if (Float.compare(f.floatValue(), min) < 0) {
min = f.floatValue();
index = i;
}
}
return index;
}
Compile error: package javax.servlet does not exist
This is what solved the problem for me:
<dependency>
<groupId>javax.servlet.jsp</groupId>
<artifactId>jsp-api</artifactId>
<version>2.2</version>
<scope>provided</scope>
</dependency>
How do I select an entire row which has the largest ID in the table?
Try with this
SELECT top 1 id, Col2, row_number() over (order by id desc) FROM Table
How to check db2 version
SELECT GETVARIABLE('SYSIBM.VERSION') FROM SYSIBM.SYSDUMMY1
MySQL error: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near
How to find out what this MySQL Error is trying to say:
#1064 - You have an error in your SQL syntax;
This error has no clues in it. You have to double check all of these items to see where your mistake is:
- You have omitted, or included an unnecessary symbol:
!@#$%^&*()-_=+[]{}\|;:'",<>/? - A misplaced, missing or unnecessary keyword:
select,into, or countless others. - You have unicode characters that look like ascii characters in your query but are not recognized.
- Misplaced, missing or unnecessary whitespace or newlines between keywords.
- Unmatched single quotes, double quotes, parenthesis or braces.
Take away as much as you can from the broken query until it starts working. And then use PostgreSQL next time that has a sane syntax reporting system.
When is it appropriate to use UDP instead of TCP?
Video streaming is a perfect example of using UDP.
How to use executables from a package installed locally in node_modules?
You don't have to manipulate $PATH anymore!
From [email protected], npm ships with npx package which lets you run commands from a local node_modules/.bin or from a central cache.
Simply run:
$ npx [options] <command>[@version] [command-arg]...
By default, npx will check whether <command> exists in $PATH, or in the local project binaries, and execute that.
Calling npx <command> when <command> isn't already in your $PATH will automatically install a package with that name from the NPM registry for you, and invoke it. When it's done, the installed package won’t be anywhere in your globals, so you won’t have to worry about pollution in the long-term. You can prevent this behaviour by providing --no-install option.
For npm < 5.2.0, you can install npx package manually by running the following command:
$ npm install -g npx
Bootstrap 3 hidden-xs makes row narrower
How does it work if you only are using visible-md at Col4 instead? Do you use the -lg at all? If not this might work.
<div class="container">
<div class="row">
<div class="col-xs-4 col-sm-2 col-md-1" align="center">
Col1
</div>
<div class="col-xs-4 col-sm-2" align="center">
Col2
</div>
<div class="hidden-xs col-sm-6 col-md-5" align="center">
Col3
</div>
<div class="visible-md col-md-3 " align="center">
Col4
</div>
<div class="col-xs-4 col-sm-2 col-md-1" align="center">
Col5
</div>
</div>
</div>
Disable back button in android
Just using this code: If you want backpressed disable, you dont use super.OnBackPressed();
@Override
public void onBackPressed() {
}
What is the use of a cursor in SQL Server?
Cursor might used for retrieving data row by row basis.its act like a looping statement(ie while or for loop). To use cursors in SQL procedures, you need to do the following: 1.Declare a cursor that defines a result set. 2.Open the cursor to establish the result set. 3.Fetch the data into local variables as needed from the cursor, one row at a time. 4.Close the cursor when done.
for ex:
declare @tab table
(
Game varchar(15),
Rollno varchar(15)
)
insert into @tab values('Cricket','R11')
insert into @tab values('VollyBall','R12')
declare @game varchar(20)
declare @Rollno varchar(20)
declare cur2 cursor for select game,rollno from @tab
open cur2
fetch next from cur2 into @game,@rollno
WHILE @@FETCH_STATUS = 0
begin
print @game
print @rollno
FETCH NEXT FROM cur2 into @game,@rollno
end
close cur2
deallocate cur2
Add and remove multiple classes in jQuery
Add multiple classes:
$("p").addClass("class1 class2 class3");
or in cascade:
$("p").addClass("class1").addClass("class2").addClass("class3");
Very similar also to remove more classes:
$("p").removeClass("class1 class2 class3");
or in cascade:
$("p").removeClass("class1").removeClass("class2").removeClass("class3");
How to disable the ability to select in a DataGridView?
I liked user4101525's answer best in theory but it doesn't actually work. Selection is not an overlay so you see whatever is under the control
Ramgy Borja's answer doesn't deal with the fact that default style is not actually a color at all so applying it doesn't help. This handles the default style and works if applying your own colors (which may be what edhubbell refers to as nasty results)
dgv.RowsDefaultCellStyle.SelectionBackColor = dgv.RowsDefaultCellStyle.BackColor.IsEmpty ? System.Drawing.Color.White : dgv.RowsDefaultCellStyle.BackColor;
dgv.RowsDefaultCellStyle.SelectionForeColor = dgv.RowsDefaultCellStyle.ForeColor.IsEmpty ? System.Drawing.Color.Black : dgv.RowsDefaultCellStyle.ForeColor;
Get Category name from Post ID
function wp_get_post_categories( $post_id = 0, $args = array() )
{
$post_id = (int) $post_id;
$defaults = array('fields' => 'ids');
$args = wp_parse_args( $args, $defaults );
$cats = wp_get_object_terms($post_id, 'category', $args);
return $cats;
}
Here is the second argument of function wp_get_post_categories()
which you can pass the attributes of receiving data.
$category_detail = get_the_category( '4',array( 'fields' => 'names' ) ); //$post->ID
foreach( $category_detail as $cd )
{
echo $cd->name;
}
How do I reference to another (open or closed) workbook, and pull values back, in VBA? - Excel 2007
You will have to open the file in one way or another if you want to access the data within it. Obviously, one way is to open it in your Excel application instance, e.g.:-
(untested code)
Dim wbk As Workbook
Set wbk = Workbooks.Open("C:\myworkbook.xls")
' now you can manipulate the data in the workbook anyway you want, e.g. '
Dim x As Variant
x = wbk.Worksheets("Sheet1").Range("A6").Value
Call wbk.Worksheets("Sheet2").Range("A1:G100").Copy
Call ThisWorbook.Worksheets("Target").Range("A1").PasteSpecial(xlPasteValues)
Application.CutCopyMode = False
' etc '
Call wbk.Close(False)
Another way to do it would be to use the Excel ADODB provider to open a connection to the file and then use SQL to select data from the sheet you want, but since you are anyway working from within Excel I don't believe there is any reason to do this rather than just open the workbook. Note that there are optional parameters for the Workbooks.Open() method to open the workbook as read-only, etc.
java.lang.ClassNotFoundException: org.springframework.core.io.Resource
Right-Click on your project -> Properties -> Deployment Assembly.
On the Left-hand panel Click 'Add' and add the 'Project and External Dependencies'.
'Project and External Dependencies' will have all the spring related jars deployed along with your application
datetime datatype in java
java.util.Date represents an instant in time, with no reference to a particular time zone or calendar system. It does hold both date and time though - it's basically a number of milliseconds since the Unix epoch.
Alternatively you can use java.util.Calendar which does know about both of those things.
Personally I would strongly recommend you use Joda Time which is a much richer date/time API. It allows you to express your data much more clearly, with types for "just dates", "just local times", "local date/time", "instant", "date/time with time zone" etc. Most of the types are also immutable, which is a huge benefit in terms of code clarity.
Android Studio Checkout Github Error "CreateProcess=2" (Windows)
I faced same issue in android studio 3.2.1, solved the issue by setting git path in System Environment variable
C:\Program Files\Git\bin\,C:\Program Files\Git\bin\
And I imported the project once again and solved the issue!!!
Note : Check your android studio git settings has properly set the correct path to git.exe
How to mock private method for testing using PowerMock?
A generic solution that will work with any testing framework (if your class is non-final) is to manually create your own mock.
- Change your private method to protected.
- In your test class extend the class
- override the previously-private method to return whatever constant you want
This doesn't use any framework so its not as elegant but it will always work: even without PowerMock. Alternatively, you can use Mockito to do steps #2 & #3 for you, if you've done step #1 already.
To mock a private method directly, you'll need to use PowerMock as shown in the other answer.
What is the opposite of :hover (on mouse leave)?
You can use CSS3 transition
Some good links:
http://css-tricks.com/different-transitions-for-hover-on-hover-off/
http://www.alistapart.com/articles/understanding-css3-transitions/
Open directory dialog
The best way to achieve what you want is to create your own wpf based control , or use a one that was made by other people
why ? because there will be a noticeable performance impact when using the winforms dialog in a wpf application (for some reason)
i recommend this project
https://opendialog.codeplex.com/
or Nuget :
PM> Install-Package OpenDialog
it's very MVVM friendly and it isn't wraping the winforms dialog
Adding Lombok plugin to IntelliJ project
If after installing the lombok intellij plugin and enabling annotation processing, if your getter and setters are still not recognised in intellij, do check if the plugin version is compatible with the intellij version you use.
It is listed under the Downloads section:
Represent space and tab in XML tag
New, expanded answer to an old, commonly asked question...
Whitespace in XML Component Names
Summary: Whitespace characters are not permitted in XML element or attribute names.
Here are the main Unicode code points related to whitespace:
#x0009CHARACTER TABULATION#x0020SPACE#x000ALINE FEED (LF)#x000DCARRIAGE RETURN (CR)#x00A0NO-BREAK SPACE[#x2002-#x200A]EN SPACE through HAIR SPACE#x205FMEDIUM MATHEMATICAL SPACE#x3000IDEOGRAPHIC SPACE
None of these code points are permitted by the W3C XML BNF for XML names:
NameStartChar ::= ":" | [A-Z] | "_" | [a-z] | [#xC0-#xD6] | [#xD8-#xF6] | [#xF8-#x2FF] | [#x370-#x37D] | [#x37F-#x1FFF] | [#x200C-#x200D] | [#x2070-#x218F] | [#x2C00-#x2FEF] | [#x3001-#xD7FF] | [#xF900-#xFDCF] | [#xFDF0-#xFFFD] | [#x10000-#xEFFFF] NameChar ::= NameStartChar | "-" | "." | [0-9] | #xB7 | [#x0300-#x036F] | [#x203F-#x2040] Name ::= NameStartChar (NameChar)*
Whitespace in XML Content (Not Component Names)
Summary: Whitespace characters are, of course, permitted in XML content.
All of the above whitespace codepoints are permitted in XML content by the W3C XML BNF for Char:
Char ::= #x9 | #xA | #xD | [#x20-#xD7FF] | [#xE000-#xFFFD] | [#x10000-#x10FFFF] /* any Unicode character, excluding the surrogate blocks, FFFE, and FFFF. */
Unicode code points can be inserted as character references. Both decimal &#decimal; and hexadecimal &#xhex; forms are supported.
- Hexadecimal Decimal Unicode Name
	or	CHARACTER TABULATION
or LINE FEED (LF)
or CARRIAGE RETURN (CR) or SPACE or NO-BREAK SPACE
Why does scanf() need "%lf" for doubles, when printf() is okay with just "%f"?
Because C will promote floats to doubles for functions that take variable arguments. Pointers aren't promoted to anything, so you should be using %lf, %lg or %le (or %la in C99) to read in doubles.
On duplicate key ignore?
Would suggest NOT using INSERT IGNORE as it ignores ALL errors (ie its a sloppy global ignore).
Instead, since in your example tag is the unique key, use:
INSERT INTO table_tags (tag) VALUES ('tag_a'),('tab_b'),('tag_c') ON DUPLICATE KEY UPDATE tag=tag;
on duplicate key produces:
Query OK, 0 rows affected (0.07 sec)
How do you specify table padding in CSS? ( table, not cell padding )
The easiest/best supported method is to use <table cellspacing="10">
The css way: border-spacing (not supported by IE I don't think)
<!-- works in firefox, opera, safari, chrome -->_x000D_
<style type="text/css">_x000D_
_x000D_
table.foobar {_x000D_
border: solid black 1px;_x000D_
border-spacing: 10px;_x000D_
}_x000D_
table.foobar td {_x000D_
border: solid black 1px;_x000D_
}_x000D_
_x000D_
_x000D_
</style>_x000D_
_x000D_
<table class="foobar" cellpadding="0" cellspacing="0">_x000D_
<tr><td>foo</td><td>bar</td></tr>_x000D_
</table>Edit: if you just want to pad the cell content, and not space them you can simply use
<table cellpadding="10">
OR
td {
padding: 10px;
}
Removing body margin in CSS
You've still got a margin on your h1 tag
So you need to remove that like this:
h1 {
margin-top:0;
}
Validating input using java.util.Scanner
For checking Strings for letters you can use regular expressions for example:
someString.matches("[A-F]");
For checking numbers and stopping the program crashing, I have a quite simple class you can find below where you can define the range of values you want. Here
public int readInt(String prompt, int min, int max)
{
Scanner scan = new Scanner(System.in);
int number = 0;
//Run once and loop until the input is within the specified range.
do
{
//Print users message.
System.out.printf("\n%s > ", prompt);
//Prevent string input crashing the program.
while (!scan.hasNextInt())
{
System.out.printf("Input doesn't match specifications. Try again.");
System.out.printf("\n%s > ", prompt);
scan.next();
}
//Set the number.
number = scan.nextInt();
//If the number is outside range print an error message.
if (number < min || number > max)
System.out.printf("Input doesn't match specifications. Try again.");
} while (number < min || number > max);
return number;
}
Liquibase lock - reasons?
The problem was the buggy implementation of SequenceExists in Liquibase. Since the changesets with these statements took a very long time and was accidently aborted. Then the next try executing the liquibase-scripts the lock was held.
<changeSet author="user" id="123">
<preConditions onFail="CONTINUE">
<not><sequenceExists sequenceName="SEQUENCE_NAME_SEQ" /></not>
</preConditions>
<createSequence sequenceName="SEQUENCE_NAME_SEQ"/>
</changeSet>
A work around is using plain SQL to check this instead:
<changeSet author="user" id="123">
<preConditions onFail="CONTINUE">
<sqlCheck expectedResult="0">
select count(*) from user_sequences where sequence_name = 'SEQUENCE_NAME_SEQ';
</sqlCheck>
</preConditions>
<createSequence sequenceName="SEQUENCE_NAME_SEQ"/>
</changeSet>
Lockdata is stored in the table DATABASECHANGELOCK. To get rid of the lock you just change 1 to 0 or drop that table and recreate.
Limiting Powershell Get-ChildItem by File Creation Date Range
Fixed it...
Get-ChildItem C:\Windows\ -recurse -include @("*.txt*","*.pdf") |
Where-Object {$_.CreationTime -gt "01/01/2013" -and $_.CreationTime -lt "12/02/2014"} |
Select-Object FullName, CreationTime, @{Name="Mbytes";Expression={$_.Length/1Kb}}, @{Name="Age";Expression={(((Get-Date) - $_.CreationTime).Days)}} |
Export-Csv C:\search_TXT-and-PDF_files_01012013-to-12022014_sort.txt
Java check to see if a variable has been initialized
Instance variables or fields, along with static variables, are assigned default values based on the variable type:
- int:
0 - char:
\u0000or0 - double:
0.0 - boolean:
false - reference:
null
Just want to clarify that local variables (ie. declared in block, eg. method, for loop, while loop, try-catch, etc.) are not initialized to default values and must be explicitly initialized.
What's the best visual merge tool for Git?
vimdiff
Once you have have learned vim (and IMHO you should), vimdiff is just one more beautiful little orthogonal concept to learn. To get online help in vim:
:help vimdiff
This question covers how to use it: How do I use vimdiff to resolve a conflict?
If you're stuck in the dark ages of mouse usage, and the files you're merging aren't very large, I recommend meld.
.htaccess File Options -Indexes on Subdirectories
The correct answer is
Options -Indexes
You must have been thinking of
AllowOverride All
https://httpd.apache.org/docs/2.2/howto/htaccess.html
.htaccess files (or "distributed configuration files") provide a way to make configuration changes on a per-directory basis. A file, containing one or more configuration directives, is placed in a particular document directory, and the directives apply to that directory, and all subdirectories thereof.
Is there a float input type in HTML5?
You can use:
<input type="number" step="any" min="0" max="100" value="22.33">
android adb turn on wifi via adb
No need to edit any database directly, there is a command for it :)
svc wifi [enable|disable]
For each row in an R dataframe
Well, since you asked for R equivalent to other languages, I tried to do this. Seems to work though I haven't really looked at which technique is more efficient in R.
> myDf <- head(iris)
> myDf
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
> nRowsDf <- nrow(myDf)
> for(i in 1:nRowsDf){
+ print(myDf[i,4])
+ }
[1] 0.2
[1] 0.2
[1] 0.2
[1] 0.2
[1] 0.2
[1] 0.4
For the categorical columns though, it would fetch you a Data Frame which you could typecast using as.character() if needed.
seek() function?
For strings, forget about using WHENCE: use f.seek(0) to position at beginning of file and f.seek(len(f)+1) to position at the end of file. Use open(file, "r+") to read/write anywhere in a file. If you use "a+" you'll only be able to write (append) at the end of the file regardless of where you position the cursor.
fatal: could not read Username for 'https://github.com': No such file or directory
I found my answer here:
edit ~/.gitconfig and add the following:
[url "[email protected]:"]
insteadOf = https://github.com/
Although it solves a different problem, the error code is the same...
Calling method using JavaScript prototype
An alternative :
// shape
var shape = function(type){
this.type = type;
}
shape.prototype.display = function(){
console.log(this.type);
}
// circle
var circle = new shape('circle');
// override
circle.display = function(a,b){
// call implementation of the super class
this.__proto__.display.apply(this,arguments);
}
Floating Point Exception C++ Why and what is it?
A "floating point number" is how computers usually represent numbers that are not integers -- basically, a number with a decimal point. In C++ you declare them with float instead of int. A floating point exception is an error that occurs when you try to do something impossible with a floating point number, such as divide by zero.
gcloud command not found - while installing Google Cloud SDK
$ sudo su
$ /opt/google-appengine-sdk/bin/gcloud components update
$ su <yourusername>
ASP.NET Core Identity - get current user
private readonly UserManager<AppUser> _userManager;
public AccountsController(UserManager<AppUser> userManager)
{
_userManager = userManager;
}
[Authorize(Policy = "ApiUser")]
[HttpGet("api/accounts/GetProfile", Name = "GetProfile")]
public async Task<IActionResult> GetProfile()
{
var userId = ((ClaimsIdentity)User.Identity).FindFirst("Id").Value;
var user = await _userManager.FindByIdAsync(userId);
ProfileUpdateModel model = new ProfileUpdateModel();
model.Email = user.Email;
model.FirstName = user.FirstName;
model.LastName = user.LastName;
model.PhoneNumber = user.PhoneNumber;
return new OkObjectResult(model);
}
How to draw a dotted line with css?
To do this, you simple need to add a border-top or border-bottom to your <hr/> tag as the following:
<hr style="border-top: 2px dotted navy" />
with any line type or color you want
I can't install python-ldap
I had problems with the installation on Windows, so one of the solutions is to install the ldap package manually.
A few steps:
- Go to the page pyldap or/and python-ldap and download the latest version
*whl. - Open a console then cd to where you've downloaded your file like
some-package.whland use:
pip install some-package.whl
The current version for pyldap is 2.4.45. On a concrete example the installation would be:
pip install .\pyldap-2.4.45-cp37-cp37m-win_amd64.whl
# or
pip install .\python_ldap-3.3.1-cp39-cp39-win_amd64.whl
Output:
Installing collected packages: pyldap
Successfully installed pyldap-2.4.45
EDIT
You can install the proper version for Python-3.X though using following command:
# if pip3 is the default pip alias for python-3
pip3 install python3-ldap
# otherwise
pip install python3-ldap
Also here is the link of PiPy package for further information: python3-ldap 0.9.8.4
OR
ldap3 is a strictly RFC 4510 conforming LDAP V3 pure Python client library. The same codebase runs in Python 2, Python 3, PyPy and PyPy3: https://github.com/cannatag/ldap3
pip install ldap3
from ldap3 import Server, Connection, SAFE_SYNC
server = Server('my_server')
conn = Connection(server, 'my_user', 'my_password', client_strategy=SAFE_SYNC, auto_bind=True)
status, result, response, _ = conn.search('o=test', '(objectclass=*)')
# usually you don't need the original request (4th element of the returned tuple)
How do you specify the Java compiler version in a pom.xml file?
maven-compiler-plugin it's already present in plugins hierarchy dependency in pom.xml. Check in Effective POM.
For short you can use properties like this:
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
I'm using Maven 3.2.5.
What is a elegant way in Ruby to tell if a variable is a Hash or an Array?
First of all, the best answer for the literal question is
Hash === @some_var
But the question really should have been answered by showing how to do duck-typing here. That depends a bit on what kind of duck you need.
@some_var.respond_to?(:each_pair)
or
@some_var.respond_to?(:has_key?)
or even
@some_var.respond_to?(:to_hash)
may be right depending on the application.
How to convert Double to int directly?
If you really should use Double instead of double you even can get the int Value of Double by calling:
Double d = new Double(1.23);
int i = d.intValue();
Else its already described by Peter Lawreys answer.
How to fast-forward a branch to head?
Doing:
git checkout master
git pull origin
will fetch and merge the origin/master branch (you may just say git pull as origin is the default).
Installing Python 3 on RHEL
It is easy to install it manually:
Download (there may be newer releases on Python.org):
$ wget https://www.python.org/ftp/python/3.4.3/Python-3.4.3.tar.xzUnzip
$ tar xf Python-3.* $ cd Python-3.*Prepare compilation
$ ./configureBuild
$ makeInstall
$ make installOR if you don't want to overwrite the
pythonexecutable (safer, at least on some distrosyumneedspythonto be 2.x, such as for RHEL6) - you can installpython3.*as a concurrent instance to the system default with analtinstall:$ make altinstall
Now if you want an alternative installation directory, you can pass --prefix to the configurecommand.
Example: for 'installing' Python in /opt/local, just add --prefix=/opt/local.
After the make install step: In order to use your new Python installation, it could be, that you still have to add the [prefix]/bin to the $PATH and [prefix]/lib to the $LD_LIBRARY_PATH (depending of the --prefix you passed)
How to add 10 minutes to my (String) time?
You have a plenty of easy approaches within above answers. This is just another idea. You can convert it to millisecond and add the TimeZoneOffset and add / deduct the mins/hours/days etc by milliseconds.
String myTime = "14:10";
int minsToAdd = 10;
Date date = new Date();
date.setTime((((Integer.parseInt(myTime.split(":")[0]))*60 + (Integer.parseInt(myTime.split(":")[1])))+ date1.getTimezoneOffset())*60000);
System.out.println(date.getHours() + ":"+date.getMinutes());
date.setTime(date.getTime()+ minsToAdd *60000);
System.out.println(date.getHours() + ":"+date.getMinutes());
Output :
14:10
14:20
Check string length in PHP
$message is propably not a string at all, but an array. Use $message[0] to access the first element.
How to modify memory contents using GDB?
Expanding on the answers provided here.
You can just do set idx = 1 to set a variable, but that syntax is not recommended because the variable name may clash with a set sub-command. As an example set w=1 would not be valid.
This means that you should prefer the syntax: set variable idx = 1 or set var idx = 1.
Last but not least, you can just use your trusty old print command, since it evaluates an expression. The only difference being that he also prints the result of the expression.
(gdb) p idx = 1
$1 = 1
You can read more about gdb here.
PackagesNotFoundError: The following packages are not available from current channels:
Try adding the conda-forge channel to your list of channels with this command:
conda config --append channels conda-forge. It tells conda to also look on the conda-forge channel when you search for packages. You can then simply install the two packages with conda install slycot control.
Channels are basically servers for people to host packages on and the community-driven conda-forge is usually a good place to start when packages are not available via the standard channels. I checked and both slycot and control seem to be available there.
How to pass variables from one php page to another without form?
You want sessions if you have data you want to have the data held for longer than one page.
$_GET for just one page.
<a href='page.php?var=data'>Data link</a>
on page.php
<?php
echo $_GET['var'];
?>
will output: data
break out of if and foreach
For those of you landing here but searching how to break out of a loop that contains an include statement use return instead of break or continue.
<?php
for ($i=0; $i < 100; $i++) {
if (i%2 == 0) {
include(do_this_for_even.php);
}
else {
include(do_this_for_odd.php);
}
}
?>
If you want to break when being inside do_this_for_even.php you need to use return. Using break or continue will return this error: Cannot break/continue 1 level. I found more details here
Take a screenshot via a Python script on Linux
Cross platform solution using wxPython:
import wx
wx.App() # Need to create an App instance before doing anything
screen = wx.ScreenDC()
size = screen.GetSize()
bmp = wx.EmptyBitmap(size[0], size[1])
mem = wx.MemoryDC(bmp)
mem.Blit(0, 0, size[0], size[1], screen, 0, 0)
del mem # Release bitmap
bmp.SaveFile('screenshot.png', wx.BITMAP_TYPE_PNG)
Best design for a changelog / auditing database table?
What we have in our table:-
Primary Key
Event type (e.g. "UPDATED", "APPROVED")
Description ("Frisbar was added to blong")
User Id
User Id of second authoriser
Amount
Date/time
Generic Id
Table Name
The generic id points at a row in the table that was updated and the table name is the name of that table as a string. Not a good DB design, but very usable. All our tables have a single surrogate key column so this works well.
'No JUnit tests found' in Eclipse
Came across this problem while upgrading projects across eclipse versions. For e.g. junits running well in Mars2.0 did not run on Neon. The following worked for me.
- Delete .settings folder. Import project into eclipse.
- Remove source folders. Then again use the folders as source folders. e.g - remove src/main/java from build path as source folder. -> Ok -> Again make this folder as source folder. Repeat it for main/resources, test/java, test/resources
Clicking at coordinates without identifying element
This worked for me in Java for clicking on coordinates irrespective on any elements.
Actions actions = new Actions(driver);
actions.moveToElement(driver.findElement(By.tagName("body")), 0, 0);
actions.moveByOffset(xCoordinate, yCoordinate).click().build().perform();
Second line of code will reset your cursor to the top left corner of the browser view and last line will click on the x,y coordinates provided as parameter.
Looping each row in datagridview
You could loop through DataGridView using Rows property, like:
foreach (DataGridViewRow row in datagridviews.Rows)
{
currQty += row.Cells["qty"].Value;
//More code here
}
Maximum number of rows of CSV data in excel sheet
Using the Excel Text import wizard to import it if it is a text file, like a CSV file, is another option and can be done based on which row number to which row numbers you specify. See: This link
How can I get Apache gzip compression to work?
Your .htaccess should run just fine; it depends on four different Apache modules (one per each <IfModule> directive). I guess one of the following:
your Apache server doesn't have either mod_filter, mod_deflate, mod_headers and/or mod_setenvif modules installed and running. If you can access the server config, please check
/etc/apache2/httpd.conf(and the related Apache config files); otherwise, you can see which modules are loaded viaphpinfo(), under the apache2handler section (see attached image); (EDIT) OR, you can open a terminal window and issue the commandsudo apachectl -Mthat will list the loaded modules;if you get an http 500 internal server error, your server may not be allowed to use .htaccess files;
you are trying to load a PHP file that sends its own headers (overwriting Apache'sheaders), thus "confusing" the browser.
In any case, you should double-check your server config and error logs to see what's going wrong. Just to be sure, try to use the fastest way suggested here in Apache docs:
AddOutputFilterByType DEFLATE text/html text/plain text/xml
and then try to load a large textfile (preferably, clean your cache first).
(EDIT) If the needed modules are there (in the Apache modules dir) but aren't loaded, just edit /etc/apache2/httpd.conf and add a LoadModule directive for each one of them.
If the needed modules aren't there (neither loaded, nor in the Apache modules directory), I fear that the only option is reinstalling Apache (a complete version).
Checking if a number is a prime number in Python
def prime(x):
# check that number is greater that 1
if x > 1:
for i in range(2, x + 1):
# check that only x and 1 can evenly divide x
if x % i == 0 and i != x and i != 1:
return False
else:
return True
else:
return False # if number is negative
Error: unexpected symbol/input/string constant/numeric constant/SPECIAL in my code
These errors mean that the R code you are trying to run or source is not syntactically correct. That is, you have a typo.
To fix the problem, read the error message carefully. The code provided in the error message shows where R thinks that the problem is. Find that line in your original code, and look for the typo.
Prophylactic measures to prevent you getting the error again
The best way to avoid syntactic errors is to write stylish code. That way, when you mistype things, the problem will be easier to spot. There are many R style guides linked from the SO R tag info page. You can also use the formatR package to automatically format your code into something more readable. In RStudio, the keyboard shortcut CTRL + SHIFT + A will reformat your code.
Consider using an IDE or text editor that highlights matching parentheses and braces, and shows strings and numbers in different colours.
Common syntactic mistakes that generate these errors
Mismatched parentheses, braces or brackets
If you have nested parentheses, braces or brackets it is very easy to close them one too many or too few times.
{}}
## Error: unexpected '}' in "{}}"
{{}} # OK
Missing * when doing multiplication
This is a common mistake by mathematicians.
5x
Error: unexpected symbol in "5x"
5*x # OK
Not wrapping if, for, or return values in parentheses
This is a common mistake by MATLAB users. In R, if, for, return, etc., are functions, so you need to wrap their contents in parentheses.
if x > 0 {}
## Error: unexpected symbol in "if x"
if(x > 0) {} # OK
Not using multiple lines for code
Trying to write multiple expressions on a single line, without separating them by semicolons causes R to fail, as well as making your code harder to read.
x + 2 y * 3
## Error: unexpected symbol in "x + 2 y"
x + 2; y * 3 # OK
else starting on a new line
In an if-else statement, the keyword else must appear on the same line as the end of the if block.
if(TRUE) 1
else 2
## Error: unexpected 'else' in "else"
if(TRUE) 1 else 2 # OK
if(TRUE)
{
1
} else # also OK
{
2
}
= instead of ==
= is used for assignment and giving values to function arguments. == tests two values for equality.
if(x = 0) {}
## Error: unexpected '=' in "if(x ="
if(x == 0) {} # OK
Missing commas between arguments
When calling a function, each argument must be separated by a comma.
c(1 2)
## Error: unexpected numeric constant in "c(1 2"
c(1, 2) # OK
Not quoting file paths
File paths are just strings. They need to be wrapped in double or single quotes.
path.expand(~)
## Error: unexpected ')' in "path.expand(~)"
path.expand("~") # OK
Quotes inside strings
This is a common problem when trying to pass quoted values to the shell via system, or creating quoted xPath or sql queries.
Double quotes inside a double quoted string need to be escaped. Likewise, single quotes inside a single quoted string need to be escaped. Alternatively, you can use single quotes inside a double quoted string without escaping, and vice versa.
"x"y"
## Error: unexpected symbol in ""x"y"
"x\"y" # OK
'x"y' # OK
Using curly quotes
So-called "smart" quotes are not so smart for R programming.
path.expand(“~”)
## Error: unexpected input in "path.expand(“"
path.expand("~") # OK
Using non-standard variable names without backquotes
?make.names describes what constitutes a valid variable name. If you create a non-valid variable name (using assign, perhaps), then you need to access it with backquotes,
assign("x y", 0)
x y
## Error: unexpected symbol in "x y"
`x y` # OK
This also applies to column names in data frames created with check.names = FALSE.
dfr <- data.frame("x y" = 1:5, check.names = FALSE)
dfr$x y
## Error: unexpected symbol in "dfr$x y"
dfr[,"x y"] # OK
dfr$`x y` # also OK
It also applies when passing operators and other special values to functions. For example, looking up help on %in%.
?%in%
## Error: unexpected SPECIAL in "?%in%"
?`%in%` # OK
Sourcing non-R code
The source function runs R code from a file. It will break if you try to use it to read in your data. Probably you want read.table.
source(textConnection("x y"))
## Error in source(textConnection("x y")) :
## textConnection("x y"):1:3: unexpected symbol
## 1: x y
## ^
Corrupted RStudio desktop file
RStudio users have reported erroneous source errors due to a corrupted .rstudio-desktop file. These reports only occurred around March 2014, so it is possibly an issue with a specific version of the IDE. RStudio can be reset using the instructions on the support page.
Using expression without paste in mathematical plot annotations
When trying to create mathematical labels or titles in plots, the expression created must be a syntactically valid mathematical expression as described on the ?plotmath page. Otherwise the contents should be contained inside a call to paste.
plot(rnorm(10), ylab = expression(alpha ^ *)))
## Error: unexpected '*' in "plot(rnorm(10), ylab = expression(alpha ^ *"
plot(rnorm(10), ylab = expression(paste(alpha ^ phantom(0), "*"))) # OK
favicon.png vs favicon.ico - why should I use PNG instead of ICO?
Avoid PNG in any case if you want reliable IE6 compatibility.
How to convert WebResponse.GetResponseStream return into a string?
You can create a StreamReader around the stream, then call StreamReader.ReadToEnd().
StreamReader responseReader = new StreamReader(request.GetResponse().GetResponseStream());
var responseData = responseReader.ReadToEnd();
Count the number of times a string appears within a string
Here, I'll over-architect the answer using LINQ. Just shows that there's more than 'n' ways to cook an egg:
public int countTrue(string data)
{
string[] splitdata = data.Split(',');
var results = from p in splitdata
where p.Contains("true")
select p;
return results.Count();
}
Which websocket library to use with Node.js?
Getting the ball rolling with this community wiki answer. Feel free to edit me with your improvements.
ws WebSocket server and client for node.js. One of the fastest libraries if not the fastest one.
websocket-node WebSocket server and client for node.js
websocket-driver-node WebSocket server and client protocol parser node.js - used in faye-websocket-node
faye-websocket-node WebSocket server and client for node.js - used in faye and sockjs
socket.io WebSocket server and client for node.js + client for browsers + (v0 has newest to oldest fallbacks, v1 of Socket.io uses engine.io) + channels - used in stack.io. Client library tries to reconnect upon disconnection.
sockjs WebSocket server and client for node.js and others + client for browsers + newest to oldest fallbacks
faye WebSocket server and client for node.js and others + client for browsers + fallbacks + support for other server-side languages
deepstream.io clusterable realtime server that handles WebSockets & TCP connections and provides data-sync, pub/sub and request/response
socketcluster WebSocket server cluster which makes use of all CPU cores on your machine. For example, if you were to use an xlarge Amazon EC2 instance with 32 cores, you would be able to handle almost 32 times the traffic on a single instance.
primus Provides a common API for most of the libraries above for easy switching + stability improvements for all of them.
When to use:
use the basic WebSocket servers when you want to use the native WebSocket implementations on the clientside, beware of the browser incompatabilities
use the fallback libraries when you care about browser fallbacks
use the full featured libraries when you care about channels
use primus when you have no idea about what to use, are not in the mood for rewriting your application when you need to switch frameworks because of changing project requirements or need additional connection stability.
Where to test:
Firecamp is a GUI testing environment for SocketIO, WS and all major real-time technology. Debug the real-time events while you're developing it.
How to add a custom right-click menu to a webpage?
Answering your question - use contextmenu event, like below:
if (document.addEventListener) {_x000D_
document.addEventListener('contextmenu', function(e) {_x000D_
alert("You've tried to open context menu"); //here you draw your own menu_x000D_
e.preventDefault();_x000D_
}, false);_x000D_
} else {_x000D_
document.attachEvent('oncontextmenu', function() {_x000D_
alert("You've tried to open context menu");_x000D_
window.event.returnValue = false;_x000D_
});_x000D_
}<body>_x000D_
Lorem ipsum..._x000D_
</body>But you should ask yourself, do you really want to overwrite default right-click behavior - it depends on application that you're developing.
What is a constant reference? (not a reference to a constant)
By "constant reference" I am guessing you really mean "reference to constant data". Pointers on the other hand, can be a constant pointer (the pointer itself is constant, not the data it points to), a pointer to constant data, or both.
How to use Oracle ORDER BY and ROWNUM correctly?
The where statement gets executed before the order by. So, your desired query is saying "take the first row and then order it by t_stamp desc". And that is not what you intend.
The subquery method is the proper method for doing this in Oracle.
If you want a version that works in both servers, you can use:
select ril.*
from (select ril.*, row_number() over (order by t_stamp desc) as seqnum
from raceway_input_labo ril
) ril
where seqnum = 1
The outer * will return "1" in the last column. You would need to list the columns individually to avoid this.
How to position three divs in html horizontally?
Get rid of the position:relative; and replace it with float:left; and float:right;.
Example in jsfiddle: http://jsfiddle.net/d9fHP/1/
<html>
<title>
Website Title </title>
<div id="the whole thing" style="float:left; height:100%; width:100%">
<div id="leftThing" style="float:left; width:25%; background-color:blue;">
Left Side Menu
</div>
<div id="content" style="float:left; width:50%; background-color:green;">
Random Content
</div>
<div id="rightThing" style="float:right; width:25%; background-color:yellow;">
Right Side Menu
</div>
</div>
</html>?
How do I build an import library (.lib) AND a DLL in Visual C++?
Does your DLL project have any actual exports? If there are no exports, the linker will not generate an import library .lib file.
In the non-Express version of VS, the import libray name is specfied in the project settings here:
Configuration Properties/Linker/Advanced/Import Library
I assume it's the same in Express (if it even provides the ability to configure the name).
Changing column names of a data frame
In case we have 2 dataframes the following works
DF1<-data.frame('a', 'b')
DF2<-data.frame('c','d')
We change names of DF1 as follows
colnames(DF1)<- colnames(DF2)
Converting a date string to a DateTime object using Joda Time library
From comments I picked an answer like and also adding TimeZone:
String dateTime = "2015-07-18T13:32:56.971-0400";
DateTimeFormatter formatter = DateTimeFormat.forPattern("yyyy-MM-dd'T'HH:mm:ss.SSSZZ")
.withLocale(Locale.ROOT)
.withChronology(ISOChronology.getInstanceUTC());
DateTime dt = formatter.parseDateTime(dateTime);
How to check if a string contains a specific text
If you need to know if a word exists in a string you can use this. As it is not clear from your question if you just want to know if the variable is a string or not. Where 'word' is the word you are searching in the string.
if (strpos($a,'word') !== false) {
echo 'true';
}
or use the is_string method. Whichs returns true or false on the given variable.
<?php
$a = '';
is_string($a);
?>
"multiple target patterns" Makefile error
My IDE left a mix of spaces and tabs in my Makefile.
Setting my Makefile to use only tabs fixed this error for me.
if A vs if A is not None:
I created a file called test.py and ran it on the interpreter. You may change what you want to, to test for sure how things is going on behind the scenes.
import dis
def func1():
matchesIterator = None
if matchesIterator:
print( "On if." );
def func2():
matchesIterator = None
if matchesIterator is not None:
print( "On if." );
print( "\nFunction 1" );
dis.dis(func1)
print( "\nFunction 2" );
dis.dis(func2)
This is the assembler difference:

Source:
>>> import importlib
>>> reload( test )
Function 1
6 0 LOAD_CONST 0 (None)
3 STORE_FAST 0 (matchesIterator)
8 6 LOAD_FAST 0 (matchesIterator)
9 POP_JUMP_IF_FALSE 20
10 12 LOAD_CONST 1 ('On if.')
15 PRINT_ITEM
16 PRINT_NEWLINE
17 JUMP_FORWARD 0 (to 20)
>> 20 LOAD_CONST 0 (None)
23 RETURN_VALUE
Function 2
14 0 LOAD_CONST 0 (None)
3 STORE_FAST 0 (matchesIterator)
16 6 LOAD_FAST 0 (matchesIterator)
9 LOAD_CONST 0 (None)
12 COMPARE_OP 9 (is not)
15 POP_JUMP_IF_FALSE 26
18 18 LOAD_CONST 1 ('On if.')
21 PRINT_ITEM
22 PRINT_NEWLINE
23 JUMP_FORWARD 0 (to 26)
>> 26 LOAD_CONST 0 (None)
29 RETURN_VALUE
<module 'test' from 'test.py'>
Publish to IIS, setting Environment Variable
Edit: as of RC2 and RTM releases, this advice is out of date. The best way I have found to accomplish this in release is to edit the following web.config sections in IIS for each environment:
system.webServer/aspNetCore:
Edit the environmentVariable entry and add an environment variable setting:
ASPNETCORE_ENVIRONMENT : < Your environment name >
As an alternative to drpdrp's approach, you can do the following:
In your project.json, add commands that pass the ASPNET_ENV variable directly to Kestrel:
"commands": { "Development": "Microsoft.AspNet.Server.Kestrel --ASPNET_ENV Development", "Staging": "Microsoft.AspNet.Server.Kestrel --ASPNET_ENV Staging", "Production": "Microsoft.AspNet.Server.Kestrel --ASPNET_ENV Production" }When publishing, use the
--iis-commandoption to specify an environment:dnu publish --configuration Debug --iis-command Staging --out "outputdir" --runtime dnx-clr-win-x86-1.0.0-rc1-update1
I found this approach to be less intrusive than creating extra IIS users.
How to dynamically create a class?
You want to look at CodeDOM. It allows defining code elements and compiling them. Quoting MSDN:
...This object graph can be rendered as source code using a CodeDOM code generator for a supported programming language. The CodeDOM can also be used to compile source code into a binary assembly.
Modify XML existing content in C#
Using LINQ to xml if you are using framework 3.5
using System.Xml.Linq;
XDocument xmlFile = XDocument.Load("books.xml");
var query = from c in xmlFile.Elements("catalog").Elements("book")
select c;
foreach (XElement book in query)
{
book.Attribute("attr1").Value = "MyNewValue";
}
xmlFile.Save("books.xml");
Fastest way to remove first char in a String
I'd guess that Remove and Substring would tie for first place, since they both slurp up a fixed-size portion of the string, whereas TrimStart does a scan from the left with a test on each character and then has to perform exactly the same work as the other two methods. Seriously, though, this is splitting hairs.
How can I stop redis-server?
If you know on which port(default:6379) your redis server is running you can go with option 1 or you can check your redis process and you can kill with option 2
option 1:
Kill process on port:
check : sudo lsof -t -i:6379
kill : sudo kill `sudo lsof -t -i:6379`
option 2:
Find the previously Running Redis Server:
ps auxx | grep redis-server
Kill the specific process by finding PID (Process ID) - Redis Sever
kill -9 PID
Now start your redis server with
redis-server /path/to/redis.conf
How to check whether a string contains a substring in JavaScript?
There is a String.prototype.includes in ES6:
"potato".includes("to");
> true
Note that this does not work in Internet Explorer or some other old browsers with no or incomplete ES6 support. To make it work in old browsers, you may wish to use a transpiler like Babel, a shim library like es6-shim, or this polyfill from MDN:
if (!String.prototype.includes) {
String.prototype.includes = function(search, start) {
'use strict';
if (typeof start !== 'number') {
start = 0;
}
if (start + search.length > this.length) {
return false;
} else {
return this.indexOf(search, start) !== -1;
}
};
}
Increase days to php current Date()
The date_add() function should do what you want. In addition, check out the docs (unofficial, but the official ones are a bit sparse) for the DateTime object, it's much nicer to work with than the procedural functions in PHP.
Oracle Differences between NVL and Coalesce
NVL and COALESCE are used to achieve the same functionality of providing a default value in case the column returns a NULL.
The differences are:
- NVL accepts only 2 arguments whereas COALESCE can take multiple arguments
- NVL evaluates both the arguments and COALESCE stops at first occurrence of a non-Null value.
- NVL does a implicit datatype conversion based on the first argument given to it. COALESCE expects all arguments to be of same datatype.
- COALESCE gives issues in queries which use UNION clauses. Example below
- COALESCE is ANSI standard where as NVL is Oracle specific.
Examples for the third case. Other cases are simple.
select nvl('abc',10) from dual; would work as NVL will do an implicit conversion of numeric 10 to string.
select coalesce('abc',10) from dual; will fail with Error - inconsistent datatypes: expected CHAR got NUMBER
Example for UNION use-case
SELECT COALESCE(a, sysdate)
from (select null as a from dual
union
select null as a from dual
);
fails with ORA-00932: inconsistent datatypes: expected CHAR got DATE
SELECT NVL(a, sysdate)
from (select null as a from dual
union
select null as a from dual
) ;
succeeds.
More information : http://www.plsqlinformation.com/2016/04/difference-between-nvl-and-coalesce-in-oracle.html
What does the 'Z' mean in Unix timestamp '120314170138Z'?
Yes. 'Z' stands for Zulu time, which is also GMT and UTC.
From http://en.wikipedia.org/wiki/Coordinated_Universal_Time:
The UTC time zone is sometimes denoted by the letter Z—a reference to the equivalent nautical time zone (GMT), which has been denoted by a Z since about 1950. The letter also refers to the "zone description" of zero hours, which has been used since 1920 (see time zone history). Since the NATO phonetic alphabet and amateur radio word for Z is "Zulu", UTC is sometimes known as Zulu time.
Technically, because the definition of nautical time zones is based on longitudinal position, the Z time is not exactly identical to the actual GMT time 'zone'. However, since it is primarily used as a reference time, it doesn't matter what area of Earth it applies to as long as everyone uses the same reference.
From wikipedia again, http://en.wikipedia.org/wiki/Nautical_time:
Around 1950, a letter suffix was added to the zone description, assigning Z to the zero zone, and A–M (except J) to the east and N–Y to the west (J may be assigned to local time in non-nautical applications; zones M and Y have the same clock time but differ by 24 hours: a full day). These were to be vocalized using a phonetic alphabet which pronounces the letter Z as Zulu, leading sometimes to the use of the term "Zulu Time". The Greenwich time zone runs from 7.5°W to 7.5°E longitude, while zone A runs from 7.5°E to 22.5°E longitude, etc.
When should I use uuid.uuid1() vs. uuid.uuid4() in python?
One instance when you may consider uuid1() rather than uuid4() is when UUIDs are produced on separate machines, for example when multiple online transactions are process on several machines for scaling purposes.
In such a situation, the risks of having collisions due to poor choices in the way the pseudo-random number generators are initialized, for example, and also the potentially higher numbers of UUIDs produced render more likely the possibility of creating duplicate IDs.
Another interest of uuid1(), in that case is that the machine where each GUID was initially produced is implicitly recorded (in the "node" part of UUID). This and the time info, may help if only with debugging.
Spring Boot REST API - request timeout?
You can try server.connection-timeout=5000 in your application.properties. From the official documentation:
server.connection-timeout= # Time in milliseconds that connectors will wait for another HTTP request before closing the connection. When not set, the connector's container-specific default will be used. Use a value of -1 to indicate no (i.e. infinite) timeout.
On the other hand, you may want to handle timeouts on the client side using Circuit Breaker pattern as I have already described in my answer here: https://stackoverflow.com/a/44484579/2328781