Download and open PDF file using Ajax
You could use this plugin which creates a form, and submits it, then removes it from the page.
jQuery.download = function(url, data, method) {
//url and data options required
if (url && data) {
//data can be string of parameters or array/object
data = typeof data == 'string' ? data : jQuery.param(data);
//split params into form inputs
var inputs = '';
jQuery.each(data.split('&'), function() {
var pair = this.split('=');
inputs += '<input type="hidden" name="' + pair[0] +
'" value="' + pair[1] + '" />';
});
//send request
jQuery('<form action="' + url +
'" method="' + (method || 'post') + '">' + inputs + '</form>')
.appendTo('body').submit().remove();
};
};
$.download(
'/export.php',
'filename=mySpreadsheet&format=xls&content=' + spreadsheetData
);
This worked for me. Found this plugin here
How to check type of variable in Java?
Actually quite easy to roll your own tester, by abusing Java's method overload ability. Though I'm still curious if there is an official method in the sdk.
Example:
class Typetester {
void printType(byte x) {
System.out.println(x + " is an byte");
}
void printType(int x) {
System.out.println(x + " is an int");
}
void printType(float x) {
System.out.println(x + " is an float");
}
void printType(double x) {
System.out.println(x + " is an double");
}
void printType(char x) {
System.out.println(x + " is an char");
}
}
then:
Typetester t = new Typetester();
t.printType( yourVariable );
MS SQL Date Only Without Time
DATEADD(d, 0, DATEDIFF(d, 0, [tstamp]))
Edit: While this will remove the time portion of your datetime, it will also make the condition non SARGable. If that's important for this query, an indexed view or a between clause is more appropriate.
Shell command to tar directory excluding certain files/folders
tar -cvzf destination_folder source_folder -X /home/folder/excludes.txt
-X indicates a file which contains a list of filenames which must be excluded from the backup. For Instance, you can specify *~ in this file to not include any filenames ending with ~ in the backup.
Get selected key/value of a combo box using jQuery
<select name="foo" id="foo">
<option value="1">a</option>
<option value="2">b</option>
<option value="3">c</option>
</select>
<input type="button" id="button" value="Button" />
});
<script> ("#foo").val() </script>
which returns 1 if you have selected a and so on..
Dividing two integers to produce a float result
Cast the operands to floats:
float ans = (float)a / (float)b;
Add / Change parameter of URL and redirect to the new URL
though i take the url from an input, it's easy adjustable to the real url.
var value = 0;
$('#check').click(function()
{
var originalURL = $('#test').val();
var exists = originalURL.indexOf('&view-all');
if(exists === -1)
{
$('#test').val(originalURL + '&view-all=value' + value++);
}
else
{
$('#test').val(originalURL.substr(0, exists + 15) + value++);
}
});
Simple excel find and replace for formulas
You can also click on the Formulas tab in Excel and select Show Formulas, then use the regular "Find" and "Replace" function. This should not affect the rest of your formula.
Accessing dict keys like an attribute?
How about Prodict, the little Python class that I wrote to rule them all:)
Plus, you get auto code completion, recursive object instantiations and auto type conversion!
You can do exactly what you asked for:
p = Prodict()
p.foo = 1
p.bar = "baz"
Example 1: Type hinting
class Country(Prodict):
name: str
population: int
turkey = Country()
turkey.name = 'Turkey'
turkey.population = 79814871
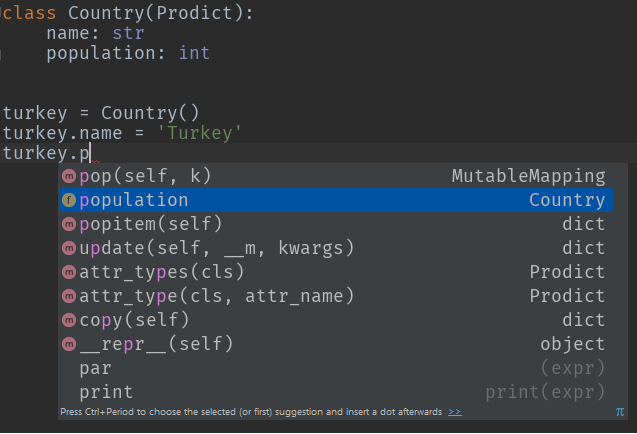
Example 2: Auto type conversion
germany = Country(name='Germany', population='82175700', flag_colors=['black', 'red', 'yellow'])
print(germany.population) # 82175700
print(type(germany.population)) # <class 'int'>
print(germany.flag_colors) # ['black', 'red', 'yellow']
print(type(germany.flag_colors)) # <class 'list'>
General error: 1364 Field 'user_id' doesn't have a default value
Post::create([
'title' => request('title'),
'body' => request('body'),
'user_id' => auth()->id()
]);
you dont need the request() as you doing that already pulling the value of body and title
How to use conditional breakpoint in Eclipse?
Make a normal breakpoint on the doIt(tablist[i]); line
Right-click -> Properties
Check 'Conditional'
Enter tablist[i].equalsIgnoreCase("LEADDELEGATES")
How do I replicate a \t tab space in HTML?
The same issue exists for a Mediawiki: It does not provide tabs, nor are consecutive spaces allowed.
Although not really a TAB function, the workaround was to add a template named 'Tab', which replaces each call (i.e. {{tab}}) by 4 non-breaking space symbols:
Those are not collapsed, and create a 4 space distance anywhere used.
It's not really a tab, because it would not align to fixed tab positions, but I still find many uses for it.
Maybe someone can come up with similar mechanism for a Wiki Template in HTML (CSS class or whatever).
Finding all objects that have a given property inside a collection
Use Google Guava.
final int lastSeq = myCollections.size();
Clazz target = Iterables.find(myCollections, new Predicate<Clazz>() {
@Override
public boolean apply(@Nullable Clazz input) {
return input.getSeq() == lastSeq;
}
});
I think to use this method.
Where does System.Diagnostics.Debug.Write output appear?
When I write debug.write("") in the code, it outputs in the "Immediate window", not "Output window".
You can try it. For displaying the "Immediate" window (Debug ? Window ? Immediate).
How to get the nth element of a python list or a default if not available
Using Python 3.4's contextlib.suppress(exceptions) to build a getitem() method similar to getattr().
import contextlib
def getitem(iterable, index, default=None):
"""Return iterable[index] or default if IndexError is raised."""
with contextlib.suppress(IndexError):
return iterable[index]
return default
Select Rows with id having even number
--This is for oracle
SELECT DISTINCT City FROM Station WHERE MOD(Id,2) = 0 ORDER BY City;
Rmi connection refused with localhost
had a simliar problem with that connection exception. it is thrown either when the registry is not started yet (like in your case) or when the registry is already unexported (like in my case).
but a short comment to the difference between the 2 ways to start the registry:
Runtime.getRuntime().exec("rmiregistry 2020");
runs the rmiregistry.exe in javas bin-directory in a new process and continues parallel with your java code.
LocateRegistry.createRegistry(2020);
the rmi method call starts the registry, returns the reference to that registry remote object and then continues with the next statement.
in your case the registry is not started in time when you try to bind your object
img src SVG changing the styles with CSS
I suggest to select your color , and go to this pen
https://codepen.io/sosuke/pen/Pjoqqp
it will convert HEX to css filter eg:#64D7D6
equal
filter: invert(88%) sepia(21%) saturate(935%) hue-rotate(123deg) brightness(85%) contrast(97%);
the final snippet
.filterit{
width:270px;
filter: invert(88%) sepia(21%) saturate(935%) hue-rotate(123deg) brightness(85%) contrast(97%);
}<img src="https://www.flaticon.com/svg/static/icons/svg/1389/1389029.svg"
class="filterit
/>Get month name from date in Oracle
If you are trying to pull the value from a field, you could use:
select extract(month from [field_name])
from [table_name]
You can also insert day or year for the "month" extraction value above.
How to return a dictionary | Python
What's going on is that you're returning right after the first line of the file doesn't match the id you're looking for. You have to do this:
def query(id):
for line in file:
table = {}
(table["ID"],table["name"],table["city"]) = line.split(";")
if id == int(table["ID"]):
file.close()
return table
# ID not found; close file and return empty dict
file.close()
return {}
Exit a Script On Error
If you want to be able to handle an error instead of blindly exiting, instead of using set -e, use a trap on the ERR pseudo signal.
#!/bin/bash
f () {
errorCode=$? # save the exit code as the first thing done in the trap function
echo "error $errorCode"
echo "the command executing at the time of the error was"
echo "$BASH_COMMAND"
echo "on line ${BASH_LINENO[0]}"
# do some error handling, cleanup, logging, notification
# $BASH_COMMAND contains the command that was being executed at the time of the trap
# ${BASH_LINENO[0]} contains the line number in the script of that command
# exit the script or return to try again, etc.
exit $errorCode # or use some other value or do return instead
}
trap f ERR
# do some stuff
false # returns 1 so it triggers the trap
# maybe do some other stuff
Other traps can be set to handle other signals, including the usual Unix signals plus the other Bash pseudo signals RETURN and DEBUG.
show all tables in DB2 using the LIST command
have you installed a user db2inst2, i think, i remember, that db2inst1 is very administrative
alter the size of column in table containing data
Case 1 : Yes, this works fine.
Case 2 : This will fail with the error ORA-01441 : cannot decrease column length because some value is too big.
Share and enjoy.
How to call a function from another controller in angularjs?
Communication between controllers is done though $emit + $on / $broadcast + $on methods.
So in your case you want to call a method of Controller "One" inside Controller "Two", the correct way to do this is:
app.controller('One', ['$scope', '$rootScope'
function($scope) {
$rootScope.$on("CallParentMethod", function(){
$scope.parentmethod();
});
$scope.parentmethod = function() {
// task
}
}
]);
app.controller('two', ['$scope', '$rootScope'
function($scope) {
$scope.childmethod = function() {
$rootScope.$emit("CallParentMethod", {});
}
}
]);
While $rootScope.$emit is called, you can send any data as second parameter.
clearing select using jquery
use .empty()
$('select').empty().append('whatever');
you can also use .html() but note
When
.html()is used to set an element's content, any content that was in that element is completely replaced by the new content. Consider the following HTML:
alternative: --- If you want only option elements to-be-remove, use .remove()
$('select option').remove();
iptables v1.4.14: can't initialize iptables table `nat': Table does not exist (do you need to insmod?)
"IP conntrack functionality has some negative impact on venet performance (uo to about 10%), so they better be disabled by default." It's need for nat
https://serverfault.com/questions/593263/iptables-nat-does-not-exist
How to export a Vagrant virtual machine to transfer it
None of the above answers worked for me. I have been 2 days working out the way to migrate a Vagrant + VirtualBox Machine from a computer to another... It's possible!
First, you need to understand that the virtual machine is separated from your sync / shared folder. So when you pack your machine you're packing it without your files, but with the databases.
What you need to do:
1- Open the CMD of your computer 1 host machine (Command line. Open it as Adminitrator with the right button -> "Run as administrator") and go to your vagrant installed files. On my case: C:/VVV You will see your Vagrantfile an also these folders:
/config/
/database/
/log/
/provision/
/www/
Vagrantfile
...
The /www/ folder is where I have my Sync Folder with my development domains. You may have your sync folder in other place, just be sure to understand what you are doing. Also /config and /database are sync folders.
2- run this command: vagrant package --vagrantfile Vagrantfile
(This command does a package of your virtual machine using you Vagrantfile configuration.)
Here's what you can read on the Vagrant documentation about the command:
A common misconception is that the --vagrantfile option will package a Vagrantfile that is used when vagrant init is used with this box. This is not the case. Instead, a Vagrantfile is loaded and read as part of the Vagrant load process when the box is used. For more information, read about the Vagrantfile load order.
https://www.vagrantup.com/docs/cli/package.html
When finnished, you will have a package.box file.
3- Copy all these files (/config, /database, Vagrantfile, package.box, etc.) and paste them on your Computer 2 just where you want to install your virtual machine (on my case D:/VVV).
Now you have a copy of everything you need on your computer 2 host.
4- run this: vagrant box add package.box --name VVV
(The --name is used to name your virtual machine. On my case it's named VVV) (You can use --force if you already have a virtual machine with this name and want to overwrite it. (Use carefully !))
This will unpack your new vagrant Virtual machine.
5- When finnished, run:
vagrant up
The machine will install and you should see it on the "Oracle virtual machine box manager". If you cannot see the virtual machine, try running the Oracle VM box as administrator (right click -> Run as administrator)
You now may have everything ok but remember to see if your hosts are as you expected:
c:/windows/system32/hosts
6- Maybe it's a good idea to copy your host file from your Computer 1 to your Computer 2. Or copy the lines you need. In my case these are the hosts I need:
192.168.50.4 test.dev
192.168.50.4 vvv.dev
...
Where the 192.168.50.4 is the IP of my Virtual machine and test.dev and vvv.dev are developing hosts.
I hope this can help you :) I'll be happy if you feedback your go.
Some particularities of my case that you may find:
When I ran vagrant up, there was a problem with mysql, it wasn't working. I had to run on the Virtual server (right click on the oracle virtual machine -> Show console): apt-get install mysql-server
After this, I ran again vagrant up and everything was working but without data on the databases. So I did a mysqldump all-tables from the Computer 1 and upload them to Computer 2.
OTHER NOTES:
My virtual machine is not exactly on Computer 1 and Computer 2. For example, I made some time ago internal configuration to use NFS (to speed up the server sync folders) and I needed to run again this command on the Computer 2 host: vagrant plugin install vagrant-winnfsd
Remove white space below image
Give the height of the div .youtube-thumb the height of the image. That should set the problem in Firefox browser.
.youtube-thumb{ height: 106px }
java.lang.UnsupportedClassVersionError
The code was most likely compiled with a later JDK (without using cross-compilation options) and is being run on an earlier JRE. While upgrading the JRE is one solution, it would be better to use the cross-compilation options to ensure the code will run on whatever JRE is intended as the minimum version for the app.
Page Redirect after X seconds wait using JavaScript
You can use this JavaScript function. Here you can display Redirection message to the user and redirected to the given URL.
<script type="text/javascript">
function Redirect()
{
window.location="http://www.newpage.com";
}
document.write("You will be redirected to a new page in 5 seconds");
setTimeout('Redirect()', 5000);
</script>
How do I draw a set of vertical lines in gnuplot?
Here is a snippet from my perl script to do this:
print OUTPUT "set arrow from $x1,$y1 to $x1,$y2 nohead lc rgb \'red\'\n";
As you might guess from above, it's actually drawn as a "headless" arrow.
How to determine the IP address of a Solaris system
Try using ifconfig -a. Look for "inet xxx.xxx.xxx.xxx", that is your IP address
Oracle "(+)" Operator
That's Oracle specific notation for an OUTER JOIN, because the ANSI-89 format (using a comma in the FROM clause to separate table references) didn't standardize OUTER joins.
The query would be re-written in ANSI-92 syntax as:
SELECT ...
FROM a
LEFT JOIN b ON b.id = a.id
This link is pretty good at explaining the difference between JOINs.
It should also be noted that even though the (+) works, Oracle recommends not using it:
Oracle recommends that you use the
FROMclauseOUTER JOINsyntax rather than the Oracle join operator. Outer join queries that use the Oracle join operator(+)are subject to the following rules and restrictions, which do not apply to theFROMclauseOUTER JOINsyntax:
Change URL parameters
Here I have taken Adil Malik's answer and fixed the 3 issues I identified with it.
/**
* Adds or updates a URL parameter.
*
* @param {string} url the URL to modify
* @param {string} param the name of the parameter
* @param {string} paramVal the new value for the parameter
* @return {string} the updated URL
*/
self.setParameter = function (url, param, paramVal){
// http://stackoverflow.com/a/10997390/2391566
var parts = url.split('?');
var baseUrl = parts[0];
var oldQueryString = parts[1];
var newParameters = [];
if (oldQueryString) {
var oldParameters = oldQueryString.split('&');
for (var i = 0; i < oldParameters.length; i++) {
if(oldParameters[i].split('=')[0] != param) {
newParameters.push(oldParameters[i]);
}
}
}
if (paramVal !== '' && paramVal !== null && typeof paramVal !== 'undefined') {
newParameters.push(param + '=' + encodeURI(paramVal));
}
if (newParameters.length > 0) {
return baseUrl + '?' + newParameters.join('&');
} else {
return baseUrl;
}
}
How many bytes does one Unicode character take?
Simply speaking Unicode is a standard which assigned one number (called code point) to all characters of the world (Its still work in progress).
Now you need to represent this code points using bytes, thats called character encoding. UTF-8, UTF-16, UTF-6 are ways of representing those characters.
UTF-8 is multibyte character encoding. Characters can have 1 to 6 bytes (some of them may be not required right now).
UTF-32 each characters have 4 bytes a characters.
UTF-16 uses 16 bits for each character and it represents only part of Unicode characters called BMP (for all practical purposes its enough). Java uses this encoding in its strings.
Copy all values in a column to a new column in a pandas dataframe
You can simply assign the B to the new column , Like -
df['D'] = df['B']
Example/Demo -
In [1]: import pandas as pd
In [2]: df = pd.DataFrame([['a.1','b.1','c.1'],['a.2','b.2','c.2'],['a.3','b.3','c.3']],columns=['A','B','C'])
In [3]: df
Out[3]:
A B C
0 a.1 b.1 c.1
1 a.2 b.2 c.2
2 a.3 b.3 c.3
In [4]: df['D'] = df['B'] #<---What you want.
In [5]: df
Out[5]:
A B C D
0 a.1 b.1 c.1 b.1
1 a.2 b.2 c.2 b.2
2 a.3 b.3 c.3 b.3
In [6]: df.loc[0,'D'] = 'd.1'
In [7]: df
Out[7]:
A B C D
0 a.1 b.1 c.1 d.1
1 a.2 b.2 c.2 b.2
2 a.3 b.3 c.3 b.3
In DB2 Display a table's definition
db2look -d <db_name> -e -z <schema_name> -t <table_name> -i <user_name> -w <password> > <file_name>.sql
For more information, please refer below:
db2look [-h]
-d: Database Name: This must be specified
-e: Extract DDL file needed to duplicate database
-xs: Export XSR objects and generate a script containing DDL statements
-xdir: Path name: the directory in which XSR objects will be placed
-u: Creator ID: If -u and -a are both not specified then $USER will be used
-z: Schema name: If -z and -a are both specified then -z will be ignored
-t: Generate statistics for the specified tables
-tw: Generate DDLs for tables whose names match the pattern criteria (wildcard characters) of the table name
-ap: Generate AUDIT USING Statements
-wlm: Generate WLM specific DDL Statements
-mod: Generate DDL statements for Module
-cor: Generate DDL with CREATE OR REPLACE clause
-wrap: Generates obfuscated versions of DDL statements
-h: More detailed help message
-o: Redirects the output to the given file name
-a: Generate statistics for all creators
-m: Run the db2look utility in mimic mode
-c: Do not generate COMMIT statements for mimic
-r: Do not generate RUNSTATS statements for mimic
-l: Generate Database Layout: Database partition groups, Bufferpools and Tablespaces
-x: Generate Authorization statements DDL excluding the original definer of the object
-xd: Generate Authorization statements DDL including the original definer of the object
-f: Extract configuration parameters and environment variables
-td: Specifies x to be statement delimiter (default is semicolon(;))
-i: User ID to log on to the server where the database resides
-w: Password to log on to the server where the database resides
Should I use Java's String.format() if performance is important?
Generally you should use String.Format because it's relatively fast and it supports globalization (assuming you're actually trying to write something that is read by the user). It also makes it easier to globalize if you're trying to translate one string versus 3 or more per statement (especially for languages that have drastically different grammatical structures).
Now if you never plan on translating anything, then either rely on Java's built in conversion of + operators into StringBuilder. Or use Java's StringBuilder explicitly.
Java: Simplest way to get last word in a string
Here is a way to do it using String's built-in regex capabilities:
String lastWord = sentence.replaceAll("^.*?(\\w+)\\W*$", "$1");
The idea is to match the whole string from ^ to $, capture the last sequence of \w+ in a capturing group 1, and replace the whole sentence with it using $1.
get and set in TypeScript
Based on example you show, you want to pass a data object and get a property of that object by get(). for this you need to use generic type, since data object is generic, can be any object.
export class Attributes<T> {
constructor(private data: T) {}
get = <K extends keyof T>(key: K): T[K] => {
return this.data[key];
};
set = (update: T): void => {
// this is like spread operator. it will take this.data obj and will overwrite with the update obj
// ins tsconfig.json change target to Es6 to be able to use Object.assign()
Object.assign(this.data, update);
};
getAll(): T {
return this.data;
}
}
< T > refers to generic type. let's initialize an instance
const myAttributes=new Attributes({name:"something",age:32})
myAttributes.get("name")="something"
Notice this syntax
<K extends keyof T>
in order to be able to use this we should be aware of 2 things:
1- in typestring strings can be a type.
2- all object properties in javascript essentially are strings.
when we use get(), type of argument that it is receiving is a property of object that passed to constructor and since object properties are strings and strings are allowed to be a type in typescript, we could use this <K extends keyof T>
Git Bash won't run my python files?
That command did not work for me, I used:
$ export PATH="$PATH:/c/Python27"
Then to make sure that git remembers the python path every time you open git type the following.
echo 'export PATH="$PATH:/c/Python27"' > .profile
What's the best way to loop through a set of elements in JavaScript?
I think you have two alternatives. For dom elements such as jQuery and like frameworks give you a good method of iteration. The second approach is the for loop.
Simulate user input in bash script
Here is a snippet I wrote; to ask for users' password and set it in /etc/passwd. You can manipulate it a little probably to get what you need:
echo -n " Please enter the password for the given user: "
read userPass
useradd $userAcct && echo -e "$userPass\n$userPass\n" | passwd $userAcct > /dev/null 2>&1 && echo " User account has been created." || echo " ERR -- User account creation failed!"
How to call a method with a separate thread in Java?
In Java 8 you can do this with one line of code.
If your method doesn't take any parameters, you can use a method reference:
new Thread(MyClass::doWork).start();
Otherwise, you can call the method in a lambda expression:
new Thread(() -> doWork(someParam)).start();
Difference between VARCHAR and TEXT in MySQL
TL;DR
TEXT
- fixed max size of 65535 characters (you cannot limit the max size)
- takes 2 +
cbytes of disk space, wherecis the length of the stored string. - cannot be (fully) part of an index. One would need to specify a prefix length.
VARCHAR(M)
- variable max size of
Mcharacters Mneeds to be between 1 and 65535- takes 1 +
cbytes (forM≤ 255) or 2 +c(for 256 ≤M≤ 65535) bytes of disk space wherecis the length of the stored string - can be part of an index
More Details
TEXT has a fixed max size of 2¹6-1 = 65535 characters.
VARCHAR has a variable max size M up to M = 2¹6-1.
So you cannot choose the size of TEXT but you can for a VARCHAR.
The other difference is, that you cannot put an index (except for a fulltext index) on a TEXT column.
So if you want to have an index on the column, you have to use VARCHAR. But notice that the length of an index is also limited, so if your VARCHAR column is too long you have to use only the first few characters of the VARCHAR column in your index (See the documentation for CREATE INDEX).
But you also want to use VARCHAR, if you know that the maximum length of the possible input string is only M, e.g. a phone number or a name or something like this. Then you can use VARCHAR(30) instead of TINYTEXT or TEXT and if someone tries to save the text of all three "Lord of the Ring" books in your phone number column you only store the first 30 characters :)
Edit: If the text you want to store in the database is longer than 65535 characters, you have to choose MEDIUMTEXT or LONGTEXT, but be careful: MEDIUMTEXT stores strings up to 16 MB, LONGTEXT up to 4 GB. If you use LONGTEXT and get the data via PHP (at least if you use mysqli without store_result), you maybe get a memory allocation error, because PHP tries to allocate 4 GB of memory to be sure the whole string can be buffered. This maybe also happens in other languages than PHP.
However, you should always check the input (Is it too long? Does it contain strange code?) before storing it in the database.
Notice: For both types, the required disk space depends only on the length of the stored string and not on the maximum length.
E.g. if you use the charset latin1 and store the text "Test" in VARCHAR(30), VARCHAR(100) and TINYTEXT, it always requires 5 bytes (1 byte to store the length of the string and 1 byte for each character). If you store the same text in a VARCHAR(2000) or a TEXT column, it would also require the same space, but, in this case, it would be 6 bytes (2 bytes to store the string length and 1 byte for each character).
For more information have a look at the documentation.
Finally, I want to add a notice, that both, TEXT and VARCHAR are variable length data types, and so they most likely minimize the space you need to store the data. But this comes with a trade-off for performance. If you need better performance, you have to use a fixed length type like CHAR. You can read more about this here.
The #include<iostream> exists, but I get an error: identifier "cout" is undefined. Why?
You need to specify the std:: namespace:
std::cout << .... << std::endl;;
Alternatively, you can use a using directive:
using std::cout;
using std::endl;
cout << .... << endl;
I should add that you should avoid these using directives in headers, since code including these will also have the symbols brought into the global namespace. Restrict using directives to small scopes, for example
#include <iostream>
inline void foo()
{
using std::cout;
using std::endl;
cout << "Hello world" << endl;
}
Here, the using directive only applies to the scope of foo().
How to list files in a directory in a C program?
An example, available for POSIX compliant systems :
/*
* This program displays the names of all files in the current directory.
*/
#include <dirent.h>
#include <stdio.h>
int main(void) {
DIR *d;
struct dirent *dir;
d = opendir(".");
if (d) {
while ((dir = readdir(d)) != NULL) {
printf("%s\n", dir->d_name);
}
closedir(d);
}
return(0);
}
Beware that such an operation is platform dependant in C.
Source : http://faq.cprogramming.com/cgi-bin/smartfaq.cgi?answer=1046380353&id=1044780608
What is the order of precedence for CSS?
Also important to note is that when you have two styles on an HTML element with equal precedence, the browser will give precedence to the styles that were written to the DOM last ... so if in the DOM:
<html>
<head>
<style>.container-ext { width: 100%; }</style>
<style>.container { width: 50px; }</style>
</head>
<body>
<div class="container container-ext">Hello World</div>
</body>
...the width of the div will be 50px
How to inject window into a service?
I know the question is how to inject the window object into a component but you're doing this just to get to localStorage it seems. If you realy just want localStorage, why not use a service that exposes just that, like h5webstorage. Then you component will describe its real dependencies which makes your code more readable.
How to check if an array value exists?
Using the instruction if?
if(isset($something['say']) && $something['say'] === 'bla') {
// do something
}
By the way, you are assigning a value with the key say twice, hence your array will result in an array with only one value.
Does JavaScript have a method like "range()" to generate a range within the supplied bounds?
You can also do the following:
const range = Array.from(Array(size)).map((el, idx) => idx+1).slice(begin, end);
Create a 3D matrix
If you want to define a 3D matrix containing all zeros, you write
A = zeros(8,4,20);
All ones uses ones, all NaN's uses NaN, all false uses false instead of zeros.
If you have an existing 2D matrix, you can assign an element in the "3rd dimension" and the matrix is augmented to contain the new element. All other new matrix elements that have to be added to do that are set to zero.
For example
B = magic(3); %# creates a 3x3 magic square
B(2,1,2) = 1; %# and you have a 3x3x2 array
"Keep Me Logged In" - the best approach
Security Notice: Basing the cookie off an MD5 hash of deterministic data is a bad idea; it's better to use a random token derived from a CSPRNG. See ircmaxell's answer to this question for a more secure approach.
Usually I do something like this:
- User logs in with 'keep me logged in'
- Create session
- Create a cookie called SOMETHING containing: md5(salt+username+ip+salt) and a cookie called somethingElse containing id
- Store cookie in database
- User does stuff and leaves ----
- User returns, check for somethingElse cookie, if it exists, get the old hash from the database for that user, check of the contents of cookie SOMETHING match with the hash from the database, which should also match with a newly calculated hash (for the ip) thus: cookieHash==databaseHash==md5(salt+username+ip+salt), if they do, goto 2, if they don't goto 1
Off course you can use different cookie names etc. also you can change the content of the cookie a bit, just make sure it isn't to easily created. You can for example also create a user_salt when the user is created and also put that in the cookie.
Also you could use sha1 instead of md5 (or pretty much any algorithm)
String to decimal conversion: dot separation instead of comma
Thanks for all reply.
Because I have to write a decimal number in a xml file I have find out the problem. In this discussion I have learned that xml file standard use dot for decimal value and this is culture independent.
So my solution is write dot decimal number in a xml file and convert the readed string from the same xml file mystring.Replace(".", ",");
Thanks Agat for suggestion to research the problem in xml context and ? ? ? ? ? ? because I didn't know visual studio doesn't respect the culture settings I have in my code.
PHP Regex to get youtube video ID?
This can be very easily accomplished using parse_str and parse_url and is more reliable in my opinion.
My function supports the following urls:
- http://youtube.com/v/dQw4w9WgXcQ?feature=youtube_gdata_player
- http://youtube.com/vi/dQw4w9WgXcQ?feature=youtube_gdata_player
- http://youtube.com/?v=dQw4w9WgXcQ&feature=youtube_gdata_player
- http://www.youtube.com/watch?v=dQw4w9WgXcQ&feature=youtube_gdata_player
- http://youtube.com/?vi=dQw4w9WgXcQ&feature=youtube_gdata_player
- http://youtube.com/watch?v=dQw4w9WgXcQ&feature=youtube_gdata_player
- http://youtube.com/watch?vi=dQw4w9WgXcQ&feature=youtube_gdata_player
- http://youtu.be/dQw4w9WgXcQ?feature=youtube_gdata_player
Also includes the test below the function.
/**
* Get Youtube video ID from URL
*
* @param string $url
* @return mixed Youtube video ID or FALSE if not found
*/
function getYoutubeIdFromUrl($url) {
$parts = parse_url($url);
if(isset($parts['query'])){
parse_str($parts['query'], $qs);
if(isset($qs['v'])){
return $qs['v'];
}else if(isset($qs['vi'])){
return $qs['vi'];
}
}
if(isset($parts['path'])){
$path = explode('/', trim($parts['path'], '/'));
return $path[count($path)-1];
}
return false;
}
// Test
$urls = array(
'http://youtube.com/v/dQw4w9WgXcQ?feature=youtube_gdata_player',
'http://youtube.com/vi/dQw4w9WgXcQ?feature=youtube_gdata_player',
'http://youtube.com/?v=dQw4w9WgXcQ&feature=youtube_gdata_player',
'http://www.youtube.com/watch?v=dQw4w9WgXcQ&feature=youtube_gdata_player',
'http://youtube.com/?vi=dQw4w9WgXcQ&feature=youtube_gdata_player',
'http://youtube.com/watch?v=dQw4w9WgXcQ&feature=youtube_gdata_player',
'http://youtube.com/watch?vi=dQw4w9WgXcQ&feature=youtube_gdata_player',
'http://youtu.be/dQw4w9WgXcQ?feature=youtube_gdata_player'
);
foreach($urls as $url){
echo $url . ' : ' . getYoutubeIdFromUrl($url) . "\n";
}
Change Background color (css property) using Jquery
The code below will change the div to blue.
<script>
$(document).ready(function(){
$("#co").click({
$("body").css("background-color","blue");
});
});
</script>
<body>
<div id="co">hello</div>
</body>
PHP: Calling another class' method
//file1.php
<?php
class ClassA
{
private $name = 'John';
function getName()
{
return $this->name;
}
}
?>
//file2.php
<?php
include ("file1.php");
class ClassB
{
function __construct()
{
}
function callA()
{
$classA = new ClassA();
$name = $classA->getName();
echo $name; //Prints John
}
}
$classb = new ClassB();
$classb->callA();
?>
What is tail recursion?
I'm not a Lisp programmer, but I think this will help.
Basically it's a style of programming such that the recursive call is the last thing you do.
Action Image MVC3 Razor
This would be work very fine
<a href="<%:Url.Action("Edit","Account",new { id=item.UserId }) %>"><img src="../../Content/ThemeNew/images/edit_notes_delete11.png" alt="Edit" width="25px" height="25px" /></a>
WPF Datagrid Get Selected Cell Value
When I faced this problem, I approached it like this:
I created a DataRowView, grabbed the column index, and then used that in the row's ItemArray
DataRowView dataRow = (DataRowView)dataGrid1.SelectedItem;
int index = dataGrid1.CurrentCell.Column.DisplayIndex;
string cellValue = dataRow.Row.ItemArray[index].ToString();
How do DATETIME values work in SQLite?
For practically all date and time matters I prefer to simplify things, very, very simple... Down to seconds stored in integers.
Integers will always be supported as integers in databases, flat files, etc. You do a little math and cast it into another type and you can format the date anyway you want.
Doing it this way, you don't have to worry when [insert current favorite database here] is replaced with [future favorite database] which coincidentally didn't use the date format you chose today.
It's just a little math overhead (eg. methods--takes two seconds, I'll post a gist if necessary) and simplifies things for a lot of operations regarding date/time later.
Add zero-padding to a string
string strvalue="11".PadRight(4, '0');
output= 1100
string strvalue="301".PadRight(4, '0');
output= 3010
string strvalue="11".PadLeft(4, '0');
output= 0011
string strvalue="301".PadLeft(4, '0');
output= 0301
Can I style an image's ALT text with CSS?
Setting the img tag color works
img {color:#fff}
body {background:#000022}_x000D_
img {color:#fff}<img src="http://badsrc.com/blah" alt="BLAH BLAH BLAH" />When to use HashMap over LinkedList or ArrayList and vice-versa
I will put here some real case examples and scenarios when to use one or another, it might be of help for somebody else:
HashMap
When you have to use cache in your application. Redis and membase are some type of extended HashMap. (Doesn't matter the order of the elements, you need quick ( O(1) ) read access (a value), using a key).
LinkedList
When the order is important (they are ordered as they were added to the LinkedList), the number of elements are unknown (don't waste memory allocation) and you require quick insertion time ( O(1) ). A list of to-do items that can be listed sequentially as they are added is a good example.
SET NAMES utf8 in MySQL?
Thanks @all!
don't use: query("SET NAMES utf8"); this is setup stuff and not a query. put it right afte a connection start with setCharset() (or similar method)
some little thing in parctice:
status:
- mysql server by default talks latin1
- your hole app is in utf8
- connection is made without any extra (so: latin1) (no SET NAMES utf8 ..., no set_charset() method/function)
Store and read data is no problem as long mysql can handle the characters. if you look in the db you will already see there is crap in it (e.g.using phpmyadmin).
until now this is not a problem! (wrong but works often (in europe)) ..
..unless another client/programm or a changed library, which works correct, will read/save data. then you are in big trouble!
Artisan migrate could not find driver
For anyone trying to enable the extension inside a Docker image:
RUN docker-php-ext-install pdo pdo_mysql \
&& docker-php-ext-enable pdo_mysql
Based on this answer.
Also props to @Krishna for shedding some light on the extension issue.
How to change workspace and build record Root Directory on Jenkins?
EDIT: Per other comments, the "Advanced..." button appears to have been removed in more recent versions of Jenkins. If your version doesn't have it, see knorx's answer.
I had the same problem, and even after finding this old pull request I still had trouble finding where to specify the Workspace Root Directory or Build Record Root Directory at the system level, versus specifying a custom workspace for each job.
To set these:
- Navigate to
Jenkins->Manage Jenkins->Configure System - Right at the top, under
Home directory, click theAdvanced...button:
- Now the fields for Workspace Root Directory and Build Record Root Directory appear:

- The information that appears if you click the help bubbles to the left of each option is very instructive. In particular (from the Workspace Root Directory help):
This value may include the following variables:
${JENKINS_HOME}— Absolute path of the Jenkins home directory${ITEM_ROOTDIR}— Absolute path of the directory where Jenkins stores the configuration and related metadata for a given job${ITEM_FULL_NAME}— The full name of a given job, which may be slash-separated, e.g. foo/bar for the job bar in folder foo
The value should normally include${ITEM_ROOTDIR}or${ITEM_FULL_NAME}, otherwise different jobs will end up sharing the same workspace.
How to join two sets in one line without using "|"
If you are fine with modifying the original set (which you may want to do in some cases), you can use set.update():
S.update(T)
The return value is None, but S will be updated to be the union of the original S and T.
IN Clause with NULL or IS NULL
An
instatement will be parsed identically tofield=val1 or field=val2 or field=val3. Putting a null in there will boil down tofield=nullwhich won't work.
I would do this for clairity
SELECT *
FROM tbl_name
WHERE
(id_field IN ('value1', 'value2', 'value3') OR id_field IS NULL)
Copy / Put text on the clipboard with FireFox, Safari and Chrome
way too old question but I didn't see this answer anywhere...
Check this link:
http://kb.mozillazine.org/Granting_JavaScript_access_to_the_clipboard
like everybody said, for security reasons is by default disabled. the link above shows the instructions of how to enable it (by editing about:config in firefox or the user.js).
Fortunately there is a plugin called "AllowClipboardHelper" which makes things easier with only a few clicks. however you still need to instruct your website's visitors on how to enable the access in firefox.
Django - Did you forget to register or load this tag?
For Django 2.2 up to 3, you have to load staticfiles in html template first before use static keyword
{% load staticfiles %}
<link rel="stylesheet" href="{% static 'css/bootstrap.min.css' %}">
For other versions use static
{% load static %}
<link rel="stylesheet" href="{% static 'css/bootstrap.min.css' %}">
Also you have to check that you defined STATIC_URL in setting.py
At last, make sure the static files exist in the defined folder
How to Find App Pool Recycles in Event Log
As it seems impossible to filter the XPath message data (it isn't in the XML to filter), you can also use powershell to search:
Get-WinEvent -LogName System | Where-Object {$_.Message -like "*recycle*"}
From this, I can see that the event Id for recycling seems to be 5074, so you can filter on this as well. I hope this helps someone as this information seemed to take a lot longer than expected to work out.
This along with @BlackHawkDesign comment should help you find what you need.
I had the same issue. Maybe interesting to mention is that you have to configure in which cases the app pool recycle event is logged. By default it's in a couple of cases, not all of them. You can do that in IIS > app pools > select the app pool > advanced settings > expand generate recycle event log entry – BlackHawkDesign Jan 14 '15 at 10:00
How can I get the content of CKEditor using JQuery?
Thanks to John Magnolia. This is my postForm function that I am using in my Symfony projects and it is fine now to work with CK Editor.
function postForm($form, callback)
{
// Get all form values
var values = {};
var fields = {};
for(var instanceName in CKEDITOR.instances){
CKEDITOR.instances[instanceName].updateElement();
}
$.each($form.serializeArray(), function(i, field) {
values[field.name] = field.value;
});
// Throw the form values to the server!
$.ajax({
type : $form.attr('method'),
url : $form.attr('action'),
data : values,
success : function(data) {
callback( data );
}
});
How to redirect and append both stdout and stderr to a file with Bash?
cmd >>file.txt 2>&1
Bash executes the redirects from left to right as follows:
>>file.txt: Openfile.txtin append mode and redirectstdoutthere.2>&1: Redirectstderrto "wherestdoutis currently going". In this case, that is a file opened in append mode. In other words, the&1reuses the file descriptor whichstdoutcurrently uses.
Format certain floating dataframe columns into percentage in pandas
Just another way of doing it should you require to do it over a larger range of columns
using applymap
df[['var1','var2']] = df[['var1','var2']].applymap("{0:.2f}".format)
df['var3'] = df['var3'].applymap(lambda x: "{0:.2f}%".format(x*100))
applymap is useful if you need to apply the function over multiple columns; it's essentially an abbreviation of the below for this specific example:
df[['var1','var2']].apply(lambda x: map(lambda x:'{:.2f}%'.format(x),x),axis=1)
Great explanation below of apply, map applymap:
Difference between map, applymap and apply methods in Pandas
SQL query to find record with ID not in another table
Keeping in mind the points made in @John Woo's comment/link above, this is how I typically would handle it:
SELECT t1.ID, t1.Name
FROM Table1 t1
WHERE NOT EXISTS (
SELECT TOP 1 NULL
FROM Table2 t2
WHERE t1.ID = t2.ID
)
What is the difference between syntax and semantics in programming languages?
Understanding how the compiler sees the code
Usually, syntax and semantics analysis of the code is done in the 'frontend' part of the compiler.
Syntax: Compiler generates tokens for each keyword and symbols: the token contains the information- type of keyword and its location in the code. Using these tokens, an AST(short for Abstract Syntax Tree) is created and analysed. What compiler actually checks here is whether the code is lexically meaningful i.e. does the 'sequence of keywords' comply with the language rules? As suggested in previous answers, you can see it as the grammar of the language(not the sense/meaning of the code). Side note: Syntax errors are reported in this phase.(returns tokens with the error type to the system)
Semantics: Now, the compiler will check whether your code operations 'makes sense'. e.g. If the language supports Type Inference, sematic error will be reported if you're trying to assign a string to a float. OR declaring the same variable twice. These are errors that are 'grammatically'/ syntaxially correct, but makes no sense during the operation. Side note: For checking whether the same variable is declared twice, compiler manages a symbol table
So, the output of these 2 frontend phases is an annotated AST(with data types) and symbol table.
Understanding it in a less technical way
Considering the normal language we use; here, English:
e.g. He go to the school. - Incorrect grammar/syntax, though he wanted to convey a correct sense/semantic.
e.g. He goes to the cold. - cold is an adjective. In English, we might say this doesn't comply with grammar, but it actually is the closest example to incorrect semantic with correct syntax I could think of.
How does one use the onerror attribute of an img element
This is actually tricky, especially if you plan on returning an image url for use cases where you need to concatenate strings with the onerror condition image URL, e.g. you might want to programatically set the url parameter in CSS.
The trick is that image loading is asynchronous by nature so the onerror doesn't happen sunchronously, i.e. if you call returnPhotoURL it immediately returns undefined bcs the asynchronous method of loading/handling the image load just began.
So, you really need to wrap your script in a Promise then call it like below. NOTE: my sample script does some other things but shows the general concept:
returnPhotoURL().then(function(value){
doc.getElementById("account-section-image").style.backgroundImage = "url('" + value + "')";
});
function returnPhotoURL(){
return new Promise(function(resolve, reject){
var img = new Image();
//if the user does not have a photoURL let's try and get one from gravatar
if (!firebase.auth().currentUser.photoURL) {
//first we have to see if user han an email
if(firebase.auth().currentUser.email){
//set sign-in-button background image to gravatar url
img.addEventListener('load', function() {
resolve (getGravatar(firebase.auth().currentUser.email, 48));
}, false);
img.addEventListener('error', function() {
resolve ('//rack.pub/media/fallbackImage.png');
}, false);
img.src = getGravatar(firebase.auth().currentUser.email, 48);
} else {
resolve ('//rack.pub/media/fallbackImage.png');
}
} else {
img.addEventListener('load', function() {
resolve (firebase.auth().currentUser.photoURL);
}, false);
img.addEventListener('error', function() {
resolve ('https://rack.pub/media/fallbackImage.png');
}, false);
img.src = firebase.auth().currentUser.photoURL;
}
});
}
Using a custom typeface in Android
I use DataBinding for this (with Kotlin).
Set up BindingAdapter:
BindingAdapter.kt
import android.graphics.Typeface
import android.view.View
import android.view.ViewGroup
import android.widget.TextView
import androidx.databinding.BindingAdapter
import java.util.*
object BindingAdapters {
@JvmStatic
@BindingAdapter("typeface", "typefaceStyle")
fun setTypeface(v: TextView, tf: Typeface?, style: Int?) {
v.setTypeface(tf ?: Typeface.DEFAULT, style ?: Typeface.NORMAL)
}
}
Usage:
fragment_custom_view.xml
<layout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools">
<data>
<import type="android.graphics.Typeface" />
<variable
name="typeface"
type="android.graphics.Typeface" />
</data>
<TextView
android:id="@+id/reference"
style="@style/TextAppearance.MaterialComponents.Body1"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="I'm formatted text"
app:typeface="@{typeface}"
app:typefaceStyle="@{Typeface.ITALIC}" />
</layout>
MyFragment.kt
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
super.onViewCreated(view, savedInstanceState)
binding = FragmentCustomView.bind(view)
binding.typeface = // some code to get user selected typeface
}
Now, if the user selects a new typeface you can just update the binding value and all your TextViews that you've set app:typeface will get updated.
make script execution to unlimited
You'll have to set it to zero. Zero means the script can run forever. Add the following at the start of your script:
ini_set('max_execution_time', 0);
Refer to the PHP documentation of max_execution_time
Note that:
set_time_limit(0);
will have the same effect.
Add to python path mac os x
Not sure why Matthew's solution didn't work for me (could be that I'm using OSX10.8 or perhaps something to do with macports). But I added the following to the end of the file at ~/.profile
export PYTHONPATH=/path/to/dir:$PYTHONPATH
my directory is now on the pythonpath -
my-macbook:~ aidan$ python
Python 2.7.2 (default, Jun 20 2012, 16:23:33)
[GCC 4.2.1 Compatible Apple Clang 4.0 (tags/Apple/clang-418.0.60)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import sys
>>> sys.path
['', '/path/to/dir', ...
and I can import modules from that directory.
Why can't DateTime.ParseExact() parse "9/1/2009" using "M/d/yyyy"
Set DateTimePicker's Format property to custom and CustomFormat prperty to M/dd/yyyy.
Function pointer to member function
Building on @IllidanS4 's answer, I have created a template class that allows virtually any member function with predefined arguments and class instance to be passed by reference for later calling.
template<class RET, class... RArgs> class Callback_t {
public:
virtual RET call(RArgs&&... rargs) = 0;
//virtual RET call() = 0;
};
template<class T, class RET, class... RArgs> class CallbackCalltimeArgs : public Callback_t<RET, RArgs...> {
public:
T * owner;
RET(T::*x)(RArgs...);
RET call(RArgs&&... rargs) {
return (*owner.*(x))(std::forward<RArgs>(rargs)...);
};
CallbackCalltimeArgs(T* t, RET(T::*x)(RArgs...)) : owner(t), x(x) {}
};
template<class T, class RET, class... Args> class CallbackCreattimeArgs : public Callback_t<RET> {
public:
T* owner;
RET(T::*x)(Args...);
RET call() {
return (*owner.*(x))(std::get<Args&&>(args)...);
};
std::tuple<Args&&...> args;
CallbackCreattimeArgs(T* t, RET(T::*x)(Args...), Args&&... args) : owner(t), x(x),
args(std::tuple<Args&&...>(std::forward<Args>(args)...)) {}
};
Test / example:
class container {
public:
static void printFrom(container* c) { c->print(); };
container(int data) : data(data) {};
~container() {};
void print() { printf("%d\n", data); };
void printTo(FILE* f) { fprintf(f, "%d\n", data); };
void printWith(int arg) { printf("%d:%d\n", data, arg); };
private:
int data;
};
int main() {
container c1(1), c2(20);
CallbackCreattimeArgs<container, void> f1(&c1, &container::print);
Callback_t<void>* fp1 = &f1;
fp1->call();//1
CallbackCreattimeArgs<container, void, FILE*> f2(&c2, &container::printTo, stdout);
Callback_t<void>* fp2 = &f2;
fp2->call();//20
CallbackCalltimeArgs<container, void, int> f3(&c2, &container::printWith);
Callback_t<void, int>* fp3 = &f3;
fp3->call(15);//20:15
}
Obviously, this will only work if the given arguments and owner class are still valid. As far as readability... please forgive me.
Edit: removed unnecessary malloc by making the tuple normal storage. Added inherited type for the reference. Added option to provide all arguments at calltime instead. Now working on having both....
Edit 2: As promised, both. Only restriction (that I see) is that the predefined arguments must come before the runtime supplied arguments in the callback function. Thanks to @Chipster for some help with gcc compliance. This works on gcc on ubuntu and visual studio on windows.
#ifdef _WIN32
#define wintypename typename
#else
#define wintypename
#endif
template<class RET, class... RArgs> class Callback_t {
public:
virtual RET call(RArgs... rargs) = 0;
virtual ~Callback_t() = default;
};
template<class RET, class... RArgs> class CallbackFactory {
private:
template<class T, class... CArgs> class Callback : public Callback_t<RET, RArgs...> {
private:
T * owner;
RET(T::*x)(CArgs..., RArgs...);
std::tuple<CArgs...> cargs;
RET call(RArgs... rargs) {
return (*owner.*(x))(std::get<CArgs>(cargs)..., rargs...);
};
public:
Callback(T* t, RET(T::*x)(CArgs..., RArgs...), CArgs... pda);
~Callback() {};
};
public:
template<class U, class... CArgs> static Callback_t<RET, RArgs...>* make(U* owner, CArgs... cargs, RET(U::*func)(CArgs..., RArgs...));
};
template<class RET2, class... RArgs2> template<class T2, class... CArgs2> CallbackFactory<RET2, RArgs2...>::Callback<T2, CArgs2...>::Callback(T2* t, RET2(T2::*x)(CArgs2..., RArgs2...), CArgs2... pda) : x(x), owner(t), cargs(std::forward<CArgs2>(pda)...) {}
template<class RET, class... RArgs> template<class U, class... CArgs> Callback_t<RET, RArgs...>* CallbackFactory<RET, RArgs...>::make(U* owner, CArgs... cargs, RET(U::*func)(CArgs..., RArgs...)) {
return new wintypename CallbackFactory<RET, RArgs...>::Callback<U, CArgs...>(owner, func, std::forward<CArgs>(cargs)...);
}
Path.Combine for URLs?
If you don't want to add a third-party dependency such as Flurl or create a custom extension method, in ASP.NET Core (also available in Microsoft.Owin), you can use PathString which is intended for the purpose of building up URI paths. You can then create your full URI using a combination of this, Uri and UriBuilder.
In this case, it would be:
new Uri(new UriBuilder("http", "MyUrl.com").Uri, new PathString("/Images").Add("/Image.jpg").ToString())
This gives you all the constituent parts without having to specify the separators in the base URL. Unfortunately, PathString requires that / is prepended to each string otherwise it in fact throws an ArgumentException! But at least you can build up your URI deterministically in a way that is easily unit-testable.
Creating a UIImage from a UIColor to use as a background image for UIButton
Xamarin.iOS solution
public UIImage CreateImageFromColor()
{
var imageSize = new CGSize(30, 30);
var imageSizeRectF = new CGRect(0, 0, 30, 30);
UIGraphics.BeginImageContextWithOptions(imageSize, false, 0);
var context = UIGraphics.GetCurrentContext();
var red = new CGColor(255, 0, 0);
context.SetFillColor(red);
context.FillRect(imageSizeRectF);
var image = UIGraphics.GetImageFromCurrentImageContext();
UIGraphics.EndImageContext();
return image;
}
Programmatically getting the MAC of an Android device
You can no longer get the hardware MAC address of a android device. WifiInfo.getMacAddress() and BluetoothAdapter.getAddress() methods will return 02:00:00:00:00:00. This restriction was introduced in Android 6.0.
But Rob Anderson found a solution which is working for < Marshmallow : https://stackoverflow.com/a/35830358
Java 8 Iterable.forEach() vs foreach loop
forEach() can be implemented to be faster than for-each loop, because the iterable knows the best way to iterate its elements, as opposed to the standard iterator way. So the difference is loop internally or loop externally.
For example ArrayList.forEach(action) may be simply implemented as
for(int i=0; i<size; i++)
action.accept(elements[i])
as opposed to the for-each loop which requires a lot of scaffolding
Iterator iter = list.iterator();
while(iter.hasNext())
Object next = iter.next();
do something with `next`
However, we also need to account for two overhead costs by using forEach(), one is making the lambda object, the other is invoking the lambda method. They are probably not significant.
see also http://journal.stuffwithstuff.com/2013/01/13/iteration-inside-and-out/ for comparing internal/external iterations for different use cases.
Splitting a table cell into two columns in HTML
Please try the following way.
<table>
<tr>
<th>Month</th>
<th>Savings</th>
</tr>
<tr>
<td>January</td>
<td>$100</td>
</tr>
<tr>
<td>February</td>
<td>$80</td>
</tr>
<tr>
<td colspan="2">Sum: $180</td>
</tr>
</table>
clientHeight/clientWidth returning different values on different browsers
What I did to fix my issue with clientHeight is to use the clientHight of the controls firstChild. I use IE 11 to print labels from a database and the clientHeight that worked in IE 8 was returning the height of 0 in IE 11. I found a property in that control that was listed as firstChild and that had a property if clientHeight and actually had the height I was looking for. So if your control is returning a clientSize of 0 take a look at the property of its firstChild. It helped me...
Scrolling to an Anchor using Transition/CSS3
Just apply scroll behaviour to all elements with this one-line code:
*{
scroll-behavior: smooth !important;
}How might I force a floating DIV to match the height of another floating DIV?
You should wrap them in a div with no float.
<div style="float:none;background:#FDD017;" class="clearfix">
<div id="response" style="float:left; width:65%;">Response with two lines</div>
<div id="note" style="float:left; width:35%;">single line note</div>
</div>
I also use the clearfix patch on here http://www.webtoolkit.info/css-clearfix.html
How to create a listbox in HTML without allowing multiple selection?
Just use the size attribute:
<select name="sometext" size="5">
<option>text1</option>
<option>text2</option>
<option>text3</option>
<option>text4</option>
<option>text5</option>
</select>
To clarify, adding the size attribute did not remove the multiple selection.
The single selection works because you removed the multiple="multiple" attribute.
Adding the size="5" attribute is still a good idea, it means that at least 5 lines must be displayed. See the full reference here
Git commit in terminal opens VIM, but can't get back to terminal
You need to return to normal mode and save the commit message with either
<Esc>:wq
or
<Esc>:x
or
<Esc>ZZ
The Esc key returns you from insert mode to normal mode. The :wq, :x or ZZ sequence writes the changes and exits the editor.
Escape dot in a regex range
The dot operator . does not need to be escaped inside of a character class [].
.do extension in web pages?
I've occasionally thought that it might serve a purpose to add a layer of security by obscuring the back-end interpreter through a remapping of .php or whatever to .aspx or whatever so that any potential hacker would be sent down the wrong path, at least for a while. I never bothered to try it and I don't do a lot of webserver work any more so I'm unlikely to.
However, I'd be interested in the perspective of an experienced server admin on that notion.
How do I get a plist as a Dictionary in Swift?
Simple struct to access plist file (Swift 2.0)
struct Configuration {
static let path = NSBundle.mainBundle().pathForResource("Info", ofType: "plist")!
static let dict = NSDictionary(contentsOfFile: path) as! [String: AnyObject]
static let someValue = dict["someKey"] as! String
}
Usage:
print("someValue = \(Configuration.someValue)")
How do I access my webcam in Python?
OpenCV has support for getting data from a webcam, and it comes with Python wrappers by default, you also need to install numpy for the OpenCV Python extension (called cv2) to work.
As of 2019, you can install both of these libraries with pip:
pip install numpy
pip install opencv-python
More information on using OpenCV with Python.
An example copied from Displaying webcam feed using opencv and python:
import cv2
cv2.namedWindow("preview")
vc = cv2.VideoCapture(0)
if vc.isOpened(): # try to get the first frame
rval, frame = vc.read()
else:
rval = False
while rval:
cv2.imshow("preview", frame)
rval, frame = vc.read()
key = cv2.waitKey(20)
if key == 27: # exit on ESC
break
cv2.destroyWindow("preview")
Find current directory and file's directory
A bit late to the party, but I think the most succinct way to find just the name of your current execution context would be
current_folder_path, current_folder_name = os.path.split(os.getcwd())
PHP write file from input to txt
use fwrite() instead of file_put_contents()
How do the major C# DI/IoC frameworks compare?
I came across another performance comparison(latest update 10 April 2014). It compares the following:
- AutoFac
- LightCore (site is German)
- LinFu
- Ninject
- Petite
- Simple Injector (the fastest of all contestants)
- Spring.NET
- StructureMap
- Unity
- Windsor
- Hiro
Here is a quick summary from the post:
Conclusion
Ninject is definitely the slowest container.
MEF, LinFu and Spring.NET are faster than Ninject, but still pretty slow. AutoFac, Catel and Windsor come next, followed by StructureMap, Unity and LightCore. A disadvantage of Spring.NET is, that can only be configured with XML.
SimpleInjector, Hiro, Funq, Munq and Dynamo offer the best performance, they are extremely fast. Give them a try!
Especially Simple Injector seems to be a good choice. It's very fast, has a good documentation and also supports advanced scenarios like interception and generic decorators.
You can also try using the Common Service Selector Library and hopefully try multiple options and see what works best for you.
Some informtion about Common Service Selector Library from the site:
The library provides an abstraction over IoC containers and service locators. Using the library allows an application to indirectly access the capabilities without relying on hard references. The hope is that using this library, third-party applications and frameworks can begin to leverage IoC/Service Location without tying themselves down to a specific implementation.
Update
13.09.2011: Funq and Munq were added to the list of contestants. The charts were also updated, and Spring.NET was removed due to it's poor performance.
04.11.2011: "added Simple Injector, the performance is the best of all contestants".
Why do you need ./ (dot-slash) before executable or script name to run it in bash?
Rationale for the / POSIX PATH rule
The rule was mentioned at: Why do you need ./ (dot-slash) before executable or script name to run it in bash? but I would like to explain why I think that is a good design in more detail.
First, an explicit full version of the rule is:
- if the path contains
/(e.g../someprog,/bin/someprog,./bin/someprog): CWD is used and PATH isn't - if the path does not contain
/(e.g.someprog): PATH is used and CWD isn't
Now, suppose that running:
someprog
would search:
- relative to CWD first
- relative to PATH after
Then, if you wanted to run /bin/someprog from your distro, and you did:
someprog
it would sometimes work, but others it would fail, because you might be in a directory that contains another unrelated someprog program.
Therefore, you would soon learn that this is not reliable, and you would end up always using absolute paths when you want to use PATH, therefore defeating the purpose of PATH.
This is also why having relative paths in your PATH is a really bad idea. I'm looking at you, node_modules/bin.
Conversely, suppose that running:
./someprog
Would search:
- relative to PATH first
- relative to CWD after
Then, if you just downloaded a script someprog from a git repository and wanted to run it from CWD, you would never be sure that this is the actual program that would run, because maybe your distro has a:
/bin/someprog
which is in you PATH from some package you installed after drinking too much after Christmas last year.
Therefore, once again, you would be forced to always run local scripts relative to CWD with full paths to know what you are running:
"$(pwd)/someprog"
which would be extremely annoying as well.
Another rule that you might be tempted to come up with would be:
relative paths use only PATH, absolute paths only CWD
but once again this forces users to always use absolute paths for non-PATH scripts with "$(pwd)/someprog".
The / path search rule offers a simple to remember solution to the about problem:
- slash: don't use
PATH - no slash: only use
PATH
which makes it super easy to always know what you are running, by relying on the fact that files in the current directory can be expressed either as ./somefile or somefile, and so it gives special meaning to one of them.
Sometimes, is slightly annoying that you cannot search for some/prog relative to PATH, but I don't see a saner solution to this.
Reading a string with scanf
I think that this below is accurate and it may help. Feel free to correct it if you find any errors. I'm new at C.
char str[]
- array of values of type char, with its own address in memory
- array of values of type char, with its own address in memory as many consecutive addresses as elements in the array
including termination null character
'\0'&str,&str[0]andstr, all three represent the same location in memory which is address of the first element of the arraystrchar *strPtr = &str[0]; //declaration and initialization
alternatively, you can split this in two:
char *strPtr; strPtr = &str[0];
strPtris a pointer to acharstrPtrpoints at arraystrstrPtris a variable with its own address in memorystrPtris a variable that stores value of address&str[0]strPtrown address in memory is different from the memory address that it stores (address of array in memory a.k.a &str[0])&strPtrrepresents the address of strPtr itself
I think that you could declare a pointer to a pointer as:
char **vPtr = &strPtr;
declares and initializes with address of strPtr pointer
Alternatively you could split in two:
char **vPtr;
*vPtr = &strPtr
*vPtrpoints at strPtr pointer*vPtris a variable with its own address in memory*vPtris a variable that stores value of address &strPtr- final comment: you can not do
str++,straddress is aconst, but you can dostrPtr++
What exactly do "u" and "r" string flags do, and what are raw string literals?
Unicode string literals
Unicode string literals (string literals prefixed by u) are no longer used in Python 3. They are still valid but just for compatibility purposes with Python 2.
Raw string literals
If you want to create a string literal consisting of only easily typable characters like english letters or numbers, you can simply type them: 'hello world'. But if you want to include also some more exotic characters, you'll have to use some workaround. One of the workarounds are Escape sequences. This way you can for example represent a new line in your string simply by adding two easily typable characters \n to your string literal. So when you print the 'hello\nworld' string, the words will be printed on separate lines. That's very handy!
On the other hand, there are some situations when you want to create a string literal that contains escape sequences but you don't want them to be interpreted by Python. You want them to be raw. Look at these examples:
'New updates are ready in c:\windows\updates\new'
'In this lesson we will learn what the \n escape sequence does.'
In such situations you can just prefix the string literal with the r character like this: r'hello\nworld' and no escape sequences will be interpreted by Python. The string will be printed exactly as you created it.
Raw string literals are not completely "raw"?
Many people expect the raw string literals to be raw in a sense that "anything placed between the quotes is ignored by Python". That is not true. Python still recognizes all the escape sequences, it just does not interpret them - it leaves them unchanged instead. It means that raw string literals still have to be valid string literals.
From the lexical definition of a string literal:
string ::= "'" stringitem* "'"
stringitem ::= stringchar | escapeseq
stringchar ::= <any source character except "\" or newline or the quote>
escapeseq ::= "\" <any source character>
It is clear that string literals (raw or not) containing a bare quote character: 'hello'world' or ending with a backslash: 'hello world\' are not valid.
Resize image with javascript canvas (smoothly)
I created a reusable Angular service to handle high quality resizing of images / canvases for anyone who's interested: https://gist.github.com/transitive-bullshit/37bac5e741eaec60e983
The service includes two solutions because they both have their own pros / cons. The lanczos convolution approach is higher quality at the cost of being slower, whereas the step-wise downscaling approach produces reasonably antialiased results and is significantly faster.
Example usage:
angular.module('demo').controller('ExampleCtrl', function (imageService) {
// EXAMPLE USAGE
// NOTE: it's bad practice to access the DOM inside a controller,
// but this is just to show the example usage.
// resize by lanczos-sinc filter
imageService.resize($('#myimg')[0], 256, 256)
.then(function (resizedImage) {
// do something with resized image
})
// resize by stepping down image size in increments of 2x
imageService.resizeStep($('#myimg')[0], 256, 256)
.then(function (resizedImage) {
// do something with resized image
})
})
Get ConnectionString from appsettings.json instead of being hardcoded in .NET Core 2.0 App
STEP 1: Include the following in OnConfiguring()
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
IConfigurationRoot configuration = new ConfigurationBuilder()
.SetBasePath(AppDomain.CurrentDomain.BaseDirectory)
.AddJsonFile("appsettings.json")
.Build();
optionsBuilder.UseSqlServer(configuration.GetConnectionString("DefaultConnection"));
}
STEP 2: Create appsettings.json:
{
"ConnectionStrings": {
"DefaultConnection": "Server=YOURSERVERNAME; Database=YOURDATABASENAME; Trusted_Connection=True; MultipleActiveResultSets=true"
}
}
STEP 3: Hard copy appsettings.json to the correct directory
Hard copy appsettings.json.config to the directory specified in the AppDomain.CurrentDomain.BaseDirectory directory.
Use your debugger to find out which directory that is.
Assumption: you have already included package Microsoft.Extensions.Configuration.Json (get it from Nuget) in your project.
This app won't run unless you update Google Play Services (via Bazaar)
I have found a nice solution which let you test your app in the emulator and also doesn't require you to revert to the older version of the library. See an answer to Stack Overflow question Running Google Maps v2 on the Android emulator.
How do I convert Word files to PDF programmatically?
Use a foreach loop instead of a for loop - it solved my problem.
int j = 0;
foreach (Microsoft.Office.Interop.Word.Page p in pane.Pages)
{
var bits = p.EnhMetaFileBits;
var target = path1 +j.ToString()+ "_image.doc";
try
{
using (var ms = new MemoryStream((byte[])(bits)))
{
var image = System.Drawing.Image.FromStream(ms);
var pngTarget = Path.ChangeExtension(target, "png");
image.Save(pngTarget, System.Drawing.Imaging.ImageFormat.Png);
}
}
catch (System.Exception ex)
{
MessageBox.Show(ex.Message);
}
j++;
}
Here is a modification of a program that worked for me. It uses Word 2007 with the Save As PDF add-in installed. It searches a directory for .doc files, opens them in Word and then saves them as a PDF. Note that you'll need to add a reference to Microsoft.Office.Interop.Word to the solution.
using Microsoft.Office.Interop.Word;
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Text;
...
// Create a new Microsoft Word application object
Microsoft.Office.Interop.Word.Application word = new Microsoft.Office.Interop.Word.Application();
// C# doesn't have optional arguments so we'll need a dummy value
object oMissing = System.Reflection.Missing.Value;
// Get list of Word files in specified directory
DirectoryInfo dirInfo = new DirectoryInfo(@"\\server\folder");
FileInfo[] wordFiles = dirInfo.GetFiles("*.doc");
word.Visible = false;
word.ScreenUpdating = false;
foreach (FileInfo wordFile in wordFiles)
{
// Cast as Object for word Open method
Object filename = (Object)wordFile.FullName;
// Use the dummy value as a placeholder for optional arguments
Document doc = word.Documents.Open(ref filename, ref oMissing,
ref oMissing, ref oMissing, ref oMissing, ref oMissing, ref oMissing,
ref oMissing, ref oMissing, ref oMissing, ref oMissing, ref oMissing,
ref oMissing, ref oMissing, ref oMissing, ref oMissing);
doc.Activate();
object outputFileName = wordFile.FullName.Replace(".doc", ".pdf");
object fileFormat = WdSaveFormat.wdFormatPDF;
// Save document into PDF Format
doc.SaveAs(ref outputFileName,
ref fileFormat, ref oMissing, ref oMissing,
ref oMissing, ref oMissing, ref oMissing, ref oMissing,
ref oMissing, ref oMissing, ref oMissing, ref oMissing,
ref oMissing, ref oMissing, ref oMissing, ref oMissing);
// Close the Word document, but leave the Word application open.
// doc has to be cast to type _Document so that it will find the
// correct Close method.
object saveChanges = WdSaveOptions.wdDoNotSaveChanges;
((_Document)doc).Close(ref saveChanges, ref oMissing, ref oMissing);
doc = null;
}
// word has to be cast to type _Application so that it will find
// the correct Quit method.
((_Application)word).Quit(ref oMissing, ref oMissing, ref oMissing);
word = null;
Python webbrowser.open() to open Chrome browser
Here's a somewhat robust way to get the path to Chrome.
(Note that you should do this only if you specifically need Chrome, and not the default browser, or Chromium, or something else.)
def try_find_chrome_path():
result = None
if _winreg:
for subkey in ['ChromeHTML\\shell\\open\\command', 'Applications\\chrome.exe\\shell\\open\\command']:
try: result = _winreg.QueryValue(_winreg.HKEY_CLASSES_ROOT, subkey)
except WindowsError: pass
if result is not None:
result_split = shlex.split(result, False, True)
result = result_split[0] if result_split else None
if os.path.isfile(result):
break
result = None
else:
expected = "google-chrome" + (".exe" if os.name == 'nt' else "")
for parent in os.environ.get('PATH', '').split(os.pathsep):
path = os.path.join(parent, expected)
if os.path.isfile(path):
result = path
break
return result
What does it mean when a PostgreSQL process is "idle in transaction"?
The PostgreSQL manual indicates that this means the transaction is open (inside BEGIN) and idle. It's most likely a user connected using the monitor who is thinking or typing. I have plenty of those on my system, too.
If you're using Slony for replication, however, the Slony-I FAQ suggests idle in transaction may mean that the network connection was terminated abruptly. Check out the discussion in that FAQ for more details.
Joining Spark dataframes on the key
you can use
val resultDf = PersonDf.join(ProfileDf, PersonDf("personId") === ProfileDf("personId"))
or shorter and more flexible (as you can easely specify more than 1 columns for joining)
val resultDf = PersonDf.join(ProfileDf,Seq("personId"))
How can I preview a merge in git?
I do not want to use the git merge command as the precursor to reviewing conflicting files. I don't want to do a merge, I want to identify potential problems before I merge - problems that auto-merge might hide from me. The solution I have been searching for is how to have git spit out a list of files that have been changed in both branches that will be merged together in the future, relative to some common ancestor. Once I have that list, I can use other file comparison tools to scout things out further. I have searched multiple times, and I still haven't found what I want in a native git command.
Here is my workaround, in case it helps anyone else out there:
In this scenario I have a branch called QA that has many changes in it since the last production release. Our last production release is tagged with "15.20.1". I have another development branch called new_stuff that I want to merge into the QA branch. Both QA and new_stuff point to commits that "follow" (as reported by gitk) the 15.20.1 tag.
git checkout QA
git pull
git diff 15.20.1 --name-only > QA_files
git checkout new_stuff
git pull
git diff 15.20.1 --name-only > new_stuff_files
comm -12 QA_files new_stuff_files
Here are some discussions that hit on why I'm interested in targeting these specific files:
https://softwareengineering.stackexchange.com/questions/199780/how-far-do-you-trust-automerge
rewrite a folder name using .htaccess
mod_rewrite can only rewrite/redirect requested URIs. So you would need to request /apple/… to get it rewritten to a corresponding /folder1/….
Try this:
RewriteEngine on
RewriteRule ^apple/(.*) folder1/$1
This rule will rewrite every request that starts with the URI path /apple/… internally to /folder1/….
Edit As you are actually looking for the other way round:
RewriteCond %{THE_REQUEST} ^GET\ /folder1/
RewriteRule ^folder1/(.*) /apple/$1 [L,R=301]
This rule is designed to work together with the other rule above. Requests of /folder1/… will be redirected externally to /apple/… and requests of /apple/… will then be rewritten internally back to /folder1/….
How to exclude records with certain values in sql select
SELECT SC.StoreId
FROM StoreClients SC
WHERE SC.StoreId NOT IN (SELECT StoreId FROM StoreClients WHERE ClientId = 5)
In this way neither JOIN nor GROUP BY is necessary.
T-SQL Substring - Last 3 Characters
You can use either way:
SELECT RIGHT(RTRIM(columnName), 3)
OR
SELECT SUBSTRING(columnName, LEN(columnName)-2, 3)
No more data to read from socket error
In our case we had a query which loads multiple items with select * from x where something in (...) The in part was so long for benchmark test.(17mb as text query). Query is valid but text so long. Shortening the query solved the problem.
Get random item from array
If you don't mind picking the same item again at some other time:
$items[rand(0, count($items) - 1)];
Best practice for instantiating a new Android Fragment
Some kotlin code:
companion object {
fun newInstance(first: String, second: String) : SampleFragment {
return SampleFragment().apply {
arguments = Bundle().apply {
putString("firstString", first)
putString("secondString", second)
}
}
}
}
And you can get arguments with this:
val first: String by lazy { arguments?.getString("firstString") ?: "default"}
val second: String by lazy { arguments?.getString("secondString") ?: "default"}
What does on_delete do on Django models?
CASCADE will also delete the corresponding field connected with it.
Use Font Awesome Icon in Placeholder
Teocci solution is as simple as it can be, thus, no need to add any CSS, just add class="fas" for Font Awesome 5, since it adds proper CSS font declaration to the element.
Here's an example for search box within Bootstrap navbar, with search icon added to the both input-group and placeholder (for the sake of demontration, of course, no one would use both at the same time). Image: https://i.imgur.com/v4kQJ77.png "> Code:
<form class="form-inline my-2 my-lg-0">
<div class="input-group mb-3">
<div class="input-group-prepend">
<span class="input-group-text"><i class="fas fa-search"></i></span>
</div>
<input type="text" class="form-control fas text-right" placeholder="" aria-label="Search string">
<div class="input-group-append">
<button class="btn btn-success input-group-text bg-success text-white border-0">Search</button>
</div>
</div>
</form>
How to check if an integer is within a range?
I don't think you'll get a better way than your function.
It is clean, easy to follow and understand, and returns the result of the condition (no return (...) ? true : false mess).
convert string to char*
There are many ways. Here are at least five:
/*
* An example of converting std::string to (const)char* using five
* different methods. Error checking is emitted for simplicity.
*
* Compile and run example (using gcc on Unix-like systems):
*
* $ g++ -Wall -pedantic -o test ./test.cpp
* $ ./test
* Original string (0x7fe3294039f8): hello
* s1 (0x7fe3294039f8): hello
* s2 (0x7fff5dce3a10): hello
* s3 (0x7fe3294000e0): hello
* s4 (0x7fe329403a00): hello
* s5 (0x7fe329403a10): hello
*/
#include <alloca.h>
#include <string>
#include <cstring>
int main()
{
std::string s0;
const char *s1;
char *s2;
char *s3;
char *s4;
char *s5;
// This is the initial C++ string.
s0 = "hello";
// Method #1: Just use "c_str()" method to obtain a pointer to a
// null-terminated C string stored in std::string object.
// Be careful though because when `s0` goes out of scope, s1 points
// to a non-valid memory.
s1 = s0.c_str();
// Method #2: Allocate memory on stack and copy the contents of the
// original string. Keep in mind that once a current function returns,
// the memory is invalidated.
s2 = (char *)alloca(s0.size() + 1);
memcpy(s2, s0.c_str(), s0.size() + 1);
// Method #3: Allocate memory dynamically and copy the content of the
// original string. The memory will be valid until you explicitly
// release it using "free". Forgetting to release it results in memory
// leak.
s3 = (char *)malloc(s0.size() + 1);
memcpy(s3, s0.c_str(), s0.size() + 1);
// Method #4: Same as method #3, but using C++ new/delete operators.
s4 = new char[s0.size() + 1];
memcpy(s4, s0.c_str(), s0.size() + 1);
// Method #5: Same as 3 but a bit less efficient..
s5 = strdup(s0.c_str());
// Print those strings.
printf("Original string (%p): %s\n", s0.c_str(), s0.c_str());
printf("s1 (%p): %s\n", s1, s1);
printf("s2 (%p): %s\n", s2, s2);
printf("s3 (%p): %s\n", s3, s3);
printf("s4 (%p): %s\n", s4, s4);
printf("s5 (%p): %s\n", s5, s5);
// Release memory...
free(s3);
delete [] s4;
free(s5);
}
Generate UML Class Diagram from Java Project
I use eUML2 plugin from Soyatec, under Eclipse and it works fine for the generation of UML giving the source code. This tool is useful up to Eclipse 4.4.x
Passing multiple variables to another page in url
Short answer:
This is what you are trying to do but it poses some security and encoding problems so don't do it.
$url = "http://localhost/main.php?email=" . $email_address . "&eventid=" . $event_id;
Long answer:
All variables in querystrings need to be urlencoded to ensure proper transmission. You should never pass a user's personal information in a url because urls are very leaky. Urls end up in log files, browsing histories, referal headers, etc. The list goes on and on.
As for proper url encoding, it can be achieved using either urlencode() or http_build_query(). Either one of these should work:
$url = "http://localhost/main.php?email=" . urlencode($email_address) . "&eventid=" . urlencode($event_id);
or
$vars = array('email' => $email_address, 'event_id' => $event_id);
$querystring = http_build_query($vars);
$url = "http://localhost/main.php?" . $querystring;
Additionally, if $event_id is in your session, you don't actually need to pass it around in order to access it from different pages. Just call session_start() and it should be available.
Spring MVC Missing URI template variable
This error may happen when mapping variables you defined in REST definition do not match with @PathVariable names.
Example: Suppose you defined in the REST definition
@GetMapping(value = "/{appId}", produces = "application/json", consumes = "application/json")
Then during the definition of the function, it should be
public ResponseEntity<List> getData(@PathVariable String appId)
This error may occur when you use any other variable other than defined in the REST controller definition with @PathVariable. Like, the below code will raise the error as ID is different than appId variable name:
public ResponseEntity<List> getData(@PathVariable String ID)
No signing certificate "iOS Distribution" found
I got the "No signing certificate" error when running Xcode 11.3 on macOS 10.14.x Mojave. (but after Xcode 12 was released.)
I was also using Fastlane. My fix was to set generate_apple_certs to false when running Match. This seemed to generate signing certificates that were backwards-compatible with Xcode 11.3
Match documentation - https://docs.fastlane.tools/actions/match/
This is the relevant section of my Fastfile:
platform :ios do
lane :certs do
force = false
match(type: "development", generate_apple_certs: false, force: force, app_identifier: "your.app.identifier.dev")
match(type: "adhoc", generate_apple_certs: false, force: force, app_identifier: "your.app.identifier.beta")
match(type: "appstore", generate_apple_certs: false, force: force, app_identifier: "your.app.identifier")
end
...
POST JSON fails with 415 Unsupported media type, Spring 3 mvc
adding content type into the request as application/json resolved the issue
Remove sensitive files and their commits from Git history
Use filter-branch:
git filter-branch --force --index-filter 'git rm --cached --ignore-unmatch *file_path_relative_to_git_repo*' --prune-empty --tag-name-filter cat -- --all
git push origin *branch_name* -f
failed to find target with hash string android-23
Mine was complaining about 26. I looked in my folders and found a folder for 27, but not 26. So I modified my build.gradle file, replacing 26 with 27. compileSdkVersion, targetSdkVersion, and implementation (changed those numbers to v:7:27.02). That changed my error message. Then I added buildToolsVersion "27.0.3" to the android bracket section right under compileSdkVersion.
Now the make project button works with 0 messages.
Next up, how to actually select a module in my configuration so I can run this.
How do I pretty-print existing JSON data with Java?
In one line:
String niceFormattedJson = JsonWriter.formatJson(jsonString)
or
System.out.println(JsonWriter.formatJson(jsonString.toString()));
The json-io libray (https://github.com/jdereg/json-io) is a small (75K) library with no other dependencies than the JDK.
In addition to pretty-printing JSON, you can serialize Java objects (entire Java object graphs with cycles) to JSON, as well as read them in.
Wrapping text inside input type="text" element HTML/CSS
You can not use input for it, you need to use textarea instead.
Use textarea with the wrap="soft"code and optional the rest of the attributes like this:
<textarea name="text" rows="14" cols="10" wrap="soft"> </textarea>
Atributes: To limit the amount of text in it for example to "40" characters you can add the attribute maxlength="40" like this: <textarea name="text" rows="14" cols="10" wrap="soft" maxlength="40"></textarea>
To hide the scroll the style for it. if you only use overflow:scroll; or overflow:hidden; or overflow:auto; it will only take affect for one scroll bar. If you want different attributes for each scroll bar then use the attributes like this overflow:scroll; overflow-x:auto; overflow-y:hidden; in the style area:
To make the textarea not resizable you can use the style with resize:none; like this:
<textarea name="text" rows="14" cols="10" wrap="soft" maxlength="40" style="overflow:hidden; resize:none;></textarea>
That way you can have or example a textarea with 14 rows and 10 cols with word wrap and max character length of "40" characters that works exactly like a input text box does but with rows instead and without using input text.
NOTE: textarea works with rows unlike like input <input type="text" name="tbox" size="10"></input> that is made to not work with rows at all.
Creating a select box with a search option
Use a data list instead.
<form action="/action_page.php" method="get">
<input list="browsers" name="browser">
<datalist id="browsers">
<option value="Internet Explorer">
<option value="Firefox">
<option value="Chrome">
<option value="Opera">
<option value="Safari">
</datalist>
<input type="submit">
</form>
Not supported I.E. 9 and back. https://www.w3schools.com/tags/tryit.asp?filename=tryhtml5_datalist
java.lang.OutOfMemoryError: bitmap size exceeds VM budget - Android
Well I've tried everything I found on the internet and none of them worked. Calling System.gc() only drags down the speed of app. Recycling bitmaps in onDestroy didn't work for me too.
The only thing that works now is to have a static list of all the bitmap so that the bitmaps survive after a restart. And just use the saved bitmaps instead of creating new ones every time the activity if restarted.
In my case the code looks like this:
private static BitmapDrawable currentBGDrawable;
if (new File(uriString).exists()) {
if (!uriString.equals(currentBGUri)) {
freeBackground();
bg = BitmapFactory.decodeFile(uriString);
currentBGUri = uriString;
bgDrawable = new BitmapDrawable(bg);
currentBGDrawable = bgDrawable;
} else {
bgDrawable = currentBGDrawable;
}
}
how to use #ifdef with an OR condition?
OR condition in #ifdef
#if defined LINUX || defined ANDROID
// your code here
#endif /* LINUX || ANDROID */
or-
#if defined(LINUX) || defined(ANDROID)
// your code here
#endif /* LINUX || ANDROID */
Both above are the same, which one you use simply depends on your taste.
P.S.: #ifdef is simply the short form of #if defined, however, does not support complex condition.
Further-
- AND:
#if defined LINUX && defined ANDROID - XOR:
#if defined LINUX ^ defined ANDROID
vue.js 2 how to watch store values from vuex
You could also subscribe to the store mutations:
store.subscribe((mutation, state) => {
console.log(mutation.type)
console.log(mutation.payload)
})
How to do an array of hashmaps?
The Java Language Specification, section 15.10, states:
An array creation expression creates an object that is a new array whose elements are of the type specified by the PrimitiveType or ClassOrInterfaceType. It is a compile-time error if the ClassOrInterfaceType does not denote a reifiable type (§4.7).
and
The rules above imply that the element type in an array creation expression cannot be a parameterized type, other than an unbounded wildcard.
The closest you can do is use an unchecked cast, either from the raw type, as you have done, or from an unbounded wildcard:
HashMap<String, String>[] responseArray = (Map<String, String>[]) new HashMap<?,?>[games.size()];
Your version is clearly better :-)
SQL Case Expression Syntax?
Sybase has the same case syntax as SQL Server:
Description
Supports conditional SQL expressions; can be used anywhere a value expression can be used.
Syntax
case
when search_condition then expression
[when search_condition then expression]...
[else expression]
end
Case and values syntax
case expression
when expression then expression
[when expression then expression]...
[else expression]
end
Parameters
case
begins the case expression.
when
precedes the search condition or the expression to be compared.
search_condition
is used to set conditions for the results that are selected. Search conditions for case expressions are similar to the search conditions in a where clause. Search conditions are detailed in the Transact-SQL User’s Guide.
then
precedes the expression that specifies a result value of case.
expression
is a column name, a constant, a function, a subquery, or any combination of column names, constants, and functions connected by arithmetic or bitwise operators. For more information about expressions, see “Expressions” in.
Example
select disaster,
case
when disaster = "earthquake"
then "stand in doorway"
when disaster = "nuclear apocalypse"
then "hide in basement"
when monster = "zombie apocalypse"
then "hide with Chuck Norris"
else
then "ask mom"
end
from endoftheworld
An existing connection was forcibly closed by the remote host - WCF
I' ve got the same problem. My solution is this :
If you using LinQ2SQL in your project, Open your dbml file in Visual Studio and change Serialization Mode to "Unidirectional" on
How to get coordinates of an svg element?
I use the consolidate function, like so:
element.transform.baseVal.consolidate()
The .e and .f values correspond to the x and y coordinates
ld cannot find an existing library
As mentioned above the linker is looking for libmagic.so, but you only have libmagic.so.1.
To solve this problem just perform an update cache.
ldconfig -v
To verify you can run:
$ ldconfig -p | grep libmagic
Pandas: how to change all the values of a column?
Or if one want to use lambda function in the apply function:
data['Revenue']=data['Revenue'].apply(lambda x:float(x.replace("$","").replace(",", "").replace(" ", "")))
Disable LESS-CSS Overwriting calc()
Using an escaped string (a.k.a. escaped value):
width: ~"calc(100% - 200px)";
Also, in case you need to mix Less math with escaped strings:
width: calc(~"100% - 15rem +" (10px+5px) ~"+ 2em");
Compiles to:
width: calc(100% - 15rem + 15px + 2em);
This works as Less concatenates values (the escaped strings and math result) with a space by default.
Change the bullet color of list
Bullets take the color property of the list:
.listStyle {
color: red;
}
Note if you want your list text to be a different colour, you have to wrap it in say, a p, for example:
.listStyle p {
color: black;
}
<ul class="listStyle">
<li>
<p><strong>View :</strong> blah blah.</p>
</li>
<li>
<p><strong>View :</strong> blah blah.</p>
</li>
</ul>
How to add class active on specific li on user click with jQuery
You specified both jQuery and Javascript in the tags so here's both approaches.
jQuery
var selector = '.nav li';
$(selector).on('click', function(){
$(selector).removeClass('active');
$(this).addClass('active');
});
Fiddle: http://jsfiddle.net/bvf9u/
Pure Javascript:
var selector, elems, makeActive;
selector = '.nav li';
elems = document.querySelectorAll(selector);
makeActive = function () {
for (var i = 0; i < elems.length; i++)
elems[i].classList.remove('active');
this.classList.add('active');
};
for (var i = 0; i < elems.length; i++)
elems[i].addEventListener('mousedown', makeActive);
Fiddle: http://jsfiddle.net/rn3nc/1
jQuery with event delegation:
Please note that in approach 1, the handler is directly bound to that element. If you're expecting the DOM to update and new lis to be injected, it's better to use event delegation and delegate to the next element that will remain static, in this case the .nav:
$('.nav').on('click', 'li', function(){
$('.nav li').removeClass('active');
$(this).addClass('active');
});
Fiddle: http://jsfiddle.net/bvf9u/1/
The subtle difference is that the handler is bound to the .nav now, so when you click the li the event bubbles up the DOM to the .nav which invokes the handler if the element clicked matches your selector argument. This means new elements won't need a new handler bound to them, because it's already bound to an ancestor.
It's really quite interesting. Read more about it here: http://api.jquery.com/on/
How to get duration, as int milli's and float seconds from <chrono>?
Taking a guess at what it is you're asking for. I'm assuming by millisecond frame timer you're looking for something that acts like the following,
double mticks()
{
struct timeval tv;
gettimeofday(&tv, 0);
return (double) tv.tv_usec / 1000 + tv.tv_sec * 1000;
}
but uses std::chrono instead,
double mticks()
{
typedef std::chrono::high_resolution_clock clock;
typedef std::chrono::duration<float, std::milli> duration;
static clock::time_point start = clock::now();
duration elapsed = clock::now() - start;
return elapsed.count();
}
Hope this helps.
Execute a batch file on a remote PC using a batch file on local PC
While I would recommend against this.
But you can use shutdown as client if the target machine has remote shutdown enabled and is in the same workgroup.
Example:
shutdown.exe /s /m \\<target-computer-name> /t 00
replacing <target-computer-name> with the URI for the target machine,
Otherwise, if you want to trigger this through Apache, you'll need to configure the batch script as a CGI script by putting AddHandler cgi-script .bat and Options +ExecCGI into either a local .htaccess file or in the main configuration for your Apache install.
Then you can just call the .bat file containing the shutdown.exe command from your browser.
MySQL my.cnf performance tuning recommendations
I tried this tool and it gave me good results.
OR is not supported with CASE Statement in SQL Server
Try
CASE WHEN ebv.db_no IN (22978,23218,23219) THEN 'WECS 9500' ELSE 'WECS 9520' END
What does this symbol mean in IntelliJ? (red circle on bottom-left corner of file name, with 'J' in it)
This situation happens when the IDE looks for src folder, and it cannot find it in the path. Select the project root (F4 in windows) > Go to Modules on Side Tab > Select Sources > Select appropriate folder with source files in it> Click on the blue sources folder icon (for adding sources) > Click on Green Test Sources folder ( to add Unit test folders).
Display Parameter(Multi-value) in Report
Hopefully someone else finds this useful:
Using the Join is the best way to use a multi-value parameter. But what if you want to have an efficient 'Select All'? If there are 100s+ then the query will be very inefficient.
To solve this instead of using a SQL Query as is, change it to using an expression (click the Fx button top right) then build your query something like this (speech marks are necessary):
= "Select * from tProducts Where 1 = 1 "
IIF(Parameters!ProductID.Value(0)=-1,Nothing," And ProductID In (" & Join(Parameters!ProductID.Value,"','") & ")")
In your Parameter do the following:
SELECT -1 As ProductID, 'All' as ProductName Union All
Select
tProducts.ProductID,tProducts.ProductName
FROM
tProducts
By building the query as an expression means you can make the SQL Statement more efficient but also handle the difficulty SQL Server has with handling values in an 'In' statement.
Python matplotlib multiple bars
The trouble with using dates as x-values, is that if you want a bar chart like in your second picture, they are going to be wrong. You should either use a stacked bar chart (colours on top of each other) or group by date (a "fake" date on the x-axis, basically just grouping the data points).
import numpy as np
import matplotlib.pyplot as plt
N = 3
ind = np.arange(N) # the x locations for the groups
width = 0.27 # the width of the bars
fig = plt.figure()
ax = fig.add_subplot(111)
yvals = [4, 9, 2]
rects1 = ax.bar(ind, yvals, width, color='r')
zvals = [1,2,3]
rects2 = ax.bar(ind+width, zvals, width, color='g')
kvals = [11,12,13]
rects3 = ax.bar(ind+width*2, kvals, width, color='b')
ax.set_ylabel('Scores')
ax.set_xticks(ind+width)
ax.set_xticklabels( ('2011-Jan-4', '2011-Jan-5', '2011-Jan-6') )
ax.legend( (rects1[0], rects2[0], rects3[0]), ('y', 'z', 'k') )
def autolabel(rects):
for rect in rects:
h = rect.get_height()
ax.text(rect.get_x()+rect.get_width()/2., 1.05*h, '%d'%int(h),
ha='center', va='bottom')
autolabel(rects1)
autolabel(rects2)
autolabel(rects3)
plt.show()
Post multipart request with Android SDK
Here is a Simple approach if you are using the AOSP library Volley.
Extend the class Request<T> as follows-
public class MultipartRequest extends Request<String> {
private static final String FILE_PART_NAME = "file";
private final Response.Listener<String> mListener;
private final Map<String, File> mFilePart;
private final Map<String, String> mStringPart;
MultipartEntityBuilder entity = MultipartEntityBuilder.create();
HttpEntity httpentity;
public MultipartRequest(String url, Response.ErrorListener errorListener,
Response.Listener<String> listener, Map<String, File> file,
Map<String, String> mStringPart) {
super(Method.POST, url, errorListener);
mListener = listener;
mFilePart = file;
this.mStringPart = mStringPart;
entity.setMode(HttpMultipartMode.BROWSER_COMPATIBLE);
buildMultipartEntity();
}
public void addStringBody(String param, String value) {
mStringPart.put(param, value);
}
private void buildMultipartEntity() {
for (Map.Entry<String, File> entry : mFilePart.entrySet()) {
// entity.addPart(entry.getKey(), new FileBody(entry.getValue(), ContentType.create("image/jpeg"), entry.getKey()));
try {
entity.addBinaryBody(entry.getKey(), Utils.toByteArray(new FileInputStream(entry.getValue())), ContentType.create("image/jpeg"), entry.getKey() + ".JPG");
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
for (Map.Entry<String, String> entry : mStringPart.entrySet()) {
if (entry.getKey() != null && entry.getValue() != null) {
entity.addTextBody(entry.getKey(), entry.getValue());
}
}
}
@Override
public String getBodyContentType() {
return httpentity.getContentType().getValue();
}
@Override
public byte[] getBody() throws AuthFailureError {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
try {
httpentity = entity.build();
httpentity.writeTo(bos);
} catch (IOException e) {
VolleyLog.e("IOException writing to ByteArrayOutputStream");
}
return bos.toByteArray();
}
@Override
protected Response<String> parseNetworkResponse(NetworkResponse response) {
Log.d("Response", new String(response.data));
return Response.success(new String(response.data), getCacheEntry());
}
@Override
protected void deliverResponse(String response) {
mListener.onResponse(response);
}
}
You can create and add a request like-
Map<String, String> params = new HashMap<>();
params.put("name", name.getText().toString());
params.put("email", email.getText().toString());
params.put("user_id", appPreferences.getInt( Utils.PROPERTY_USER_ID, -1) + "");
params.put("password", password.getText().toString());
params.put("imageName", pictureName);
Map<String, File> files = new HashMap<>();
files.put("photo", new File(Utils.LOCAL_RESOURCE_PATH + pictureName));
MultipartRequest multipartRequest = new MultipartRequest(Utils.BASE_URL + "editprofile/" + appPreferences.getInt(Utils.PROPERTY_USER_ID, -1), new Response.ErrorListener() {
@Override
public void onErrorResponse(VolleyError error) {
// TODO Auto-generated method stub
Log.d("Error: ", error.toString());
FugaDialog.showErrorDialog(ProfileActivity.this);
}
}, new Response.Listener<String>() {
@Override
public void onResponse(String jsonResponse) {
JSONObject response = null;
try {
Log.d("jsonResponse: ", jsonResponse);
response = new JSONObject(jsonResponse);
} catch (JSONException e) {
e.printStackTrace();
}
try {
if (response != null && response.has("statusmessage") && response.getBoolean("statusmessage")) {
updateLocalRecord();
}
} catch (JSONException e) {
e.printStackTrace();
}
FugaDialog.dismiss();
}
}, files, params);
RequestQueue queue = Volley.newRequestQueue(this);
queue.add(multipartRequest);
Responding with a JSON object in Node.js (converting object/array to JSON string)
var objToJson = { };
objToJson.response = response;
response.write(JSON.stringify(objToJson));
If you alert(JSON.stringify(objToJson)) you will get {"response":"value"}
How do you plot bar charts in gnuplot?
plot "data.dat" using 2: xtic(1) with histogram
Here data.dat contains data of the form
title 1 title2 3 "long title" 5
Retrieve last 100 lines logs
You can simply use the following command:-
tail -NUMBER_OF_LINES FILE_NAME
e.g tail -100 test.log
- will fetch the last 100 lines from test.log
In case, if you want the output of the above in a separate file then you can pipes as follows:-
tail -NUMBER_OF_LINES FILE_NAME > OUTPUT_FILE_NAME
e.g tail -100 test.log > output.log
- will fetch the last 100 lines from test.log and store them into a new file output.log)
How to list only the file names that changed between two commits?
git diff --name-only SHA1 SHA2
where you only need to include enough of the SHA to identify the commits. You can also do, for example
git diff --name-only HEAD~10 HEAD~5
to see the differences between the tenth latest commit and the fifth latest (or so).
How to refresh datagrid in WPF
From MSDN -
CollectionViewSource.GetDefaultView(myGrid.ItemsSource).Refresh();
Maven Error: Could not find or load main class
I got this error(classNotFoundException for main class), I actually changed pom version , so did maven install again and then error vanished.
C# delete a folder and all files and folders within that folder
Read the Manual:
Directory.Delete Method (String, Boolean)
Directory.Delete(folderPath, true);
Java: Integer equals vs. ==
As well for correctness of using == you can just unbox one of compared Integer values before doing == comparison, like:
if ( firstInteger.intValue() == secondInteger ) {..
The second will be auto unboxed (of course you have to check for nulls first).
"Uncaught TypeError: undefined is not a function" - Beginner Backbone.js Application
I have occurred the same error look following example-
async.waterfall([function(waterCB) {
waterCB(null);
}, function(**inputArray**, waterCB) {
waterCB(null);
}], function(waterErr, waterResult) {
console.log('Done');
});
In the above waterfall function, I am accepting inputArray parameter in waterfall 2nd function. But this inputArray not passed in waterfall 1st function in waterCB.
Cheak your function parameters Below are a correct example.
async.waterfall([function(waterCB) {
waterCB(null, **inputArray**);
}, function(**inputArray**, waterCB) {
waterCB(null);
}], function(waterErr, waterResult) {
console.log('Done');
});
Thanks
SQL to generate a list of numbers from 1 to 100
I created an Oracle function that returns a table of numbers
CREATE OR REPLACE FUNCTION [schema].FN_TABLE_NUMBERS(
NUMINI INTEGER,
NUMFIN INTEGER,
EXPONENCIAL INTEGER DEFAULT 0
) RETURN TBL_NUMBERS
IS
NUMEROS TBL_NUMBERS;
INDICE NUMBER;
BEGIN
NUMEROS := TBL_NUMBERS();
FOR I IN (
WITH TABLA AS (SELECT NUMINI, NUMFIN FROM DUAL)
SELECT NUMINI NUM FROM TABLA UNION ALL
SELECT
(SELECT NUMINI FROM TABLA) + (LEVEL*TO_NUMBER('1E'||TO_CHAR(EXPONENCIAL))) NUM
FROM DUAL
CONNECT BY
(LEVEL*TO_NUMBER('1E'||TO_CHAR(EXPONENCIAL))) <= (SELECT NUMFIN-NUMINI FROM TABLA)
) LOOP
NUMEROS.EXTEND;
INDICE := NUMEROS.COUNT;
NUMEROS(INDICE):= i.NUM;
END LOOP;
RETURN NUMEROS;
EXCEPTION
WHEN NO_DATA_FOUND THEN
RETURN NUMEROS;
WHEN OTHERS THEN
RETURN NUMEROS;
END;
/
Is necessary create a new data type:
CREATE OR REPLACE TYPE [schema]."TBL_NUMBERS" IS TABLE OF NUMBER;
/
Usage:
SELECT COLUMN_VALUE NUM FROM TABLE([schema].FN_TABLE_NUMBERS(1,10))--integers difference: 1;2;.......;10
And if you need decimals between numbers by exponencial notation:
SELECT COLUMN_VALUE NUM FROM TABLE([schema].FN_TABLE_NUMBERS(1,10,-1));--with 0.1 difference: 1;1.1;1.2;.......;10
SELECT COLUMN_VALUE NUM FROM TABLE([schema].FN_TABLE_NUMBERS(1,10,-2));--with 0.01 difference: 1;1.01;1.02;.......;10
What is INSTALL_PARSE_FAILED_NO_CERTIFICATES error?
Setting environment variable JAVA_HOME to JDK 5 or 6 (instead of JDK 7) fixed the error.
How to retrieve the current value of an oracle sequence without increment it?
This is not an answer, really and I would have entered it as a comment had the question not been locked. This answers the question:
Why would you want it?
Assume you have a table with the sequence as the primary key and the sequence is generated by an insert trigger. If you wanted to have the sequence available for subsequent updates to the record, you need to have a way to extract that value.
In order to make sure you get the right one, you might want to wrap the INSERT and RonK's query in a transaction.
RonK's Query:
select MY_SEQ_NAME.currval from DUAL;
In the above scenario, RonK's caveat does not apply since the insert and update would happen in the same session.
Shell script - remove first and last quote (") from a variable
There's a simpler and more efficient way, using the native shell prefix/suffix removal feature:
temp="${opt%\"}"
temp="${temp#\"}"
echo "$temp"
${opt%\"} will remove the suffix " (escaped with a backslash to prevent shell interpretation).
${temp#\"} will remove the prefix " (escaped with a backslash to prevent shell interpretation).
Another advantage is that it will remove surrounding quotes only if there are surrounding quotes.
BTW, your solution always removes the first and last character, whatever they may be (of course, I'm sure you know your data, but it's always better to be sure of what you're removing).
Using sed:
echo "$opt" | sed -e 's/^"//' -e 's/"$//'
(Improved version, as indicated by jfgagne, getting rid of echo)
sed -e 's/^"//' -e 's/"$//' <<<"$opt"
So it replaces a leading " with nothing, and a trailing " with nothing too. In the same invocation (there isn't any need to pipe and start another sed. Using -e you can have multiple text processing).
How can I give an imageview click effect like a button on Android?
Simply just use an ImageButton.
Bootstrap datepicker hide after selection
At least in version 2.2.3 that I'm using, you must use autoClose instead of autoclose. Letter case matters.
How to install MySQLdb (Python data access library to MySQL) on Mac OS X?
I ran into this issue and found that mysqlclient needs to know where to find openssl, and OSX hides this by default.
Locate openssl with brew info openssl, and then add the path to your openssl bin to your PATH:
export PATH="/usr/local/opt/openssl/bin:$PATH"
I recommend adding that to your .zshrc or .bashrc so you don't need to worry about it in the future. Then, with that variable exported (which may meed closing and re-opening your bash session), add two more env variables:
# in terminal
export LDFLAGS="-L/usr/local/opt/openssl/lib"
export CPPFLAGS="-I/usr/local/opt/openssl/include"
Then, finally, run:
pipenv install mysqlclient
and it should install just fine.
Source: https://medium.com/@shandou/pipenv-install-mysqlclient-on-macosx-7c253b0112f2
How do you connect to a MySQL database using Oracle SQL Developer?
Although @BrianHart 's answer is correct, if you are connecting from a remote host, you'll also need to allow remote hosts to connect to the MySQL/MariaDB database.
My article describes the full instructions to connect to a MySQL/MariaDB database in Oracle SQL Developer:
COALESCE Function in TSQL
Here is the way I look at COALESCE...and hopefully it makes sense...
In a simplistic form….
Coalesce(FieldName, 'Empty')
So this translates to…If "FieldName" is NULL, populate the field value with the word "EMPTY".
Now for mutliple values...
Coalesce(FieldName1, FieldName2, Value2, Value3)
If the value in Fieldname1 is null, fill it with the value in Fieldname2, if FieldName2 is NULL, fill it with Value2, etc.
This piece of test code for the AdventureWorks2012 sample database works perfectly & gives a good visual explanation of how COALESCE works:
SELECT Name, Class, Color, ProductNumber,
COALESCE(Class, Color, ProductNumber) AS FirstNotNull
FROM Production.Product
How to Generate Unique ID in Java (Integer)?
Do you need it to be;
- unique between two JVMs running at the same time.
- unique even if the JVM is restarted.
- thread-safe.
- support null? if not, use int or long.
How to add additional fields to form before submit?
Try this:
$('#form').submit(function(eventObj) {
$(this).append('<input type="hidden" name="field_name" value="value" /> ');
return true;
});
jQuery - trapping tab select event
Simply use the on click event for tab shown.
$(document).on('shown.bs.tab', 'a[href="#tab"]', function (){
});
Get page title with Selenium WebDriver using Java
If you're using Selenium 2.0 / Webdriver you can call driver.getTitle() or driver.getPageSource() if you want to search through the actual page source.
In Git, how do I figure out what my current revision is?
This gives you the first few digits of the hash and they are unique enough to use as say a version number.
git rev-parse --short HEAD
Fastest way to set all values of an array?
Java Programmer's FAQ Part B Sect 6 suggests:
public static void bytefill(byte[] array, byte value) {
int len = array.length;
if (len > 0)
array[0] = value;
for (int i = 1; i < len; i += i)
System.arraycopy( array, 0, array, i,
((len - i) < i) ? (len - i) : i);
}
This essentially makes log2(array.length) calls to System.arraycopy which hopefully utilizes an optimized memcpy implementation.
However, is this technique still required on modern Java JITs such as the Oracle/Android JIT?
MySQL Multiple Where Clause
I think that you are after this:
SELECT image_id
FROM list
WHERE (style_id, style_value) IN ((24,'red'),(25,'big'),(27,'round'))
GROUP BY image_id
HAVING count(distinct style_id, style_value)=3
You can't use AND, because values can't be 24 red and 25 big and 27 round at the same time in the same row, but you need to check the presence of style_id, style_value in multiple rows, under the same image_id.
In this query I'm using IN (that, in this particular example, is equivalent to an OR), and I am counting the distinct rows that match. If 3 distinct rows match, it means that all 3 attributes are present for that image_id, and my query will return it.
No newline at end of file
If you add a new line of text at the end of the existing file which does not already have a newline character at the end, the diff will show the old last line as having been modified, even though conceptually it wasn’t.
This is at least one good reason to add a newline character at the end.
Example
A file contains:
A() {
// do something
}
Hexdump:
00000000: 4128 2920 7b0a 2020 2020 2f2f 2064 6f20 A() {. // do
00000010: 736f 6d65 7468 696e 670a 7d something.}
You now edit it to
A() {
// do something
}
// Useful comment
Hexdump:
00000000: 4128 2920 7b0a 2020 2020 2f2f 2064 6f20 A() {. // do
00000010: 736f 6d65 7468 696e 670a 7d0a 2f2f 2055 something.}.// U
00000020: 7365 6675 6c20 636f 6d6d 656e 742e 0a seful comment..
The git diff will show:
-}
\ No newline at end of file
+}
+// Useful comment.
In other words, it shows a larger diff than conceptually occurred. It shows that you deleted the line } and added the line }\n. This is, in fact, what happened, but it’s not what conceptually happened, so it can be confusing.
In Python, how do I use urllib to see if a website is 404 or 200?
You can use urllib2 as well:
import urllib2
req = urllib2.Request('http://www.python.org/fish.html')
try:
resp = urllib2.urlopen(req)
except urllib2.HTTPError as e:
if e.code == 404:
# do something...
else:
# ...
except urllib2.URLError as e:
# Not an HTTP-specific error (e.g. connection refused)
# ...
else:
# 200
body = resp.read()
Note that HTTPError is a subclass of URLError which stores the HTTP status code.
Fast ceiling of an integer division in C / C++
Compile with O3, The compiler performs optimization well.
q = x / y;
if (x % y) ++q;
How to link to specific line number on github
Related to how to link to the README.md of a GitHub repository to a specific line number of code
You have three cases:
We can link to (custom commit)
But Link will ALWAYS link to old file version, which will NOT contains new updates in the master branch for example. Example:
https://github.com/username/projectname/blob/b8d94367354011a0470f1b73c8f135f095e28dd4/file.txt#L10We can link to (custom branch) like (master-branch). But the link will ALWAYS link to the latest file version which will contain new updates. Due to new updates, the link may point to an invalid business line number. Example:
https://github.com/username/projectname/blob/master/file.txt#L10GitHub can NOT make AUTO-link to any file either to (custom commit) nor (master-branch) Because of following business issues:
- line business meaning, to link to it in the new file
- length of target highlighted code which can be changed
How to indent/format a selection of code in Visual Studio Code with Ctrl + Shift + F
On OS X, choose "Document Format", and select all lines that you need format.
Then Option + Shift + F.
How does java do modulus calculations with negative numbers?
Modulo arithmetic with negative operands is defined by the language designer, who might leave it to the language implementation, who might defer the definition to the CPU architecture.
I wasn't able to find a Java language definition.
Thanks Ishtar, Java Language Specification for the Remainder Operator % says that the sign of the result is the same as the sign of the numerator.
How does strcmp() work?
Is just this:
int strcmp(char *str1, char *str2){
while( (*str1 == *str2) && (*str1 != 0) ){
++*str1;
++*str2;
}
return (*str1-*str2);
}
if you want more fast, you can add "register " before type, like this: register char
then, like this:
int strcmp(register char *str1, register char *str2){
while( (*str1 == *str2) && (*str1 != 0) ){
++*str1;
++*str2;
}
return (*str1-*str2);
}
this way, if possible, the register of the ALU are used.
Loop backwards using indices in Python?
You might want to use the reversed function in python.
Before we jump in to the code we must remember that the range
function always returns a list (or a tuple I don't know) so range(5) will return [0, 1, 2, 3, 4]. The reversed function reverses a list or a tuple so reversed(range(5)) will be [4, 3, 2, 1, 0] so your solution might be:
for i in reversed(range(100)):
print(i)
Difference between two lists
bit late but here is working solution for me
var myBaseProperty = (typeof(BaseClass)).GetProperties();//get base code properties
var allProperty = entity.GetProperties()[0].DeclaringType.GetProperties();//get derived class property plus base code as it is derived from it
var declaredClassProperties = allProperty.Where(x => !myBaseProperty.Any(l => l.Name == x.Name)).ToList();//get the difference
In above mention code I am getting the properties difference between my base class and derived class list
Saving a text file on server using JavaScript
It's not possible to save content to the website using only client-side scripting such as JavaScript and jQuery, but by submitting the data in an AJAX POST request you could perform the other half very easily on the server-side.
However, I would not recommend having raw content such as scripts so easily writeable to your hosting as this could easily be exploited. If you want to learn more about AJAX POST requests, you can read the jQuery API page:
http://api.jquery.com/jQuery.post/
And here are some things you ought to be aware of if you still want to save raw script files on your hosting. You have to be very careful with security if you are handling files like this!
File uploading (most of this applies if sending plain text too if javascript can choose the name of the file) http://www.developershome.com/wap/wapUpload/wap_upload.asp?page=security https://www.owasp.org/index.php/Unrestricted_File_Upload
Where does MySQL store database files on Windows and what are the names of the files?
You can check my.ini file to see where the data folder is located.
Usually there is a folder {mysqlDirectory}/data
MySQL data storage:
Commands.frm
Commands.myd
Commands.myi
The *.frm files contain the table definitions. Your *.myi files are MyISAM index files. Your *.myd files contain the table data.
Edit/Update. Because of the interest shown in the question here is more info which is found also in the comments.
In Windows 8.1, the MySQL databases are stored (by default) here: C:\ProgramData\MySQL\MySQL Server 5.6\data
The folder C:\ProgramData is a hidden folder, so you must type it into Windows Explorer address to get there. In that data folder, the databases are named /{database_name_folder}/{database_tables_and_files}.
For instance,
C:\ProgramData\MySQL\MySQL Server 5.6\data\mydatabase\mytable.frm
C:\ProgramData\MySQL\MySQL Server 5.6\data\mydatabase\mytable.ibd
Thank @marty-mcgee for this content
Exception : javax.net.ssl.SSLPeerUnverifiedException: peer not authenticated
You can get this if the client specifies "https" but the server is only running "http". So, the server isn't expecting to make a secure connection.
Logging levels - Logback - rule-of-thumb to assign log levels
I answer this coming from a component-based architecture, where an organisation may be running many components that may rely on each other. During a propagating failure, logging levels should help to identify both which components are affected and which are a root cause.
ERROR - This component has had a failure and the cause is believed to be internal (any internal, unhandled exception, failure of encapsulated dependency... e.g. database, REST example would be it has received a 4xx error from a dependency). Get me (maintainer of this component) out of bed.
WARN - This component has had a failure believed to be caused by a dependent component (REST example would be a 5xx status from a dependency). Get the maintainers of THAT component out of bed.
INFO - Anything else that we want to get to an operator. If you decide to log happy paths then I recommend limiting to 1 log message per significant operation (e.g. per incoming http request).
For all log messages be sure to log useful context (and prioritise on making messages human readable/useful rather than having reams of "error codes")
- DEBUG (and below) - Shouldn't be used at all (and certainly not in production). In development I would advise using a combination of TDD and Debugging (where necessary) as opposed to polluting code with log statements. In production, the above INFO logging, combined with other metrics should be sufficient.
A nice way to visualise the above logging levels is to imagine a set of monitoring screens for each component. When all running well they are green, if a component logs a WARNING then it will go orange (amber) if anything logs an ERROR then it will go red.
In the event of an incident you should have one (root cause) component go red and all the affected components should go orange/amber.
How to query MongoDB with "like"?
Using template literals with variables also works:
{"firstname": {$regex : `^${req.body.firstname}.*` , $options: 'si' }}
Is there an alternative to string.Replace that is case-insensitive?
The regular expression method should work. However what you can also do is lower case the string from the database, lower case the %variables% you have, and then locate the positions and lengths in the lower cased string from the database. Remember, positions in a string don't change just because its lower cased.
Then using a loop that goes in reverse (its easier, if you do not you will have to keep a running count of where later points move to) remove from your non-lower cased string from the database the %variables% by their position and length and insert the replacement values.
How to append rows in a pandas dataframe in a for loop?
First, create a empty DataFrame with column names, after that, inside the for loop, you must define a dictionary (a row) with the data to append:
df = pd.DataFrame(columns=['A'])
for i in range(5):
df = df.append({'A': i}, ignore_index=True)
df
A
0 0
1 1
2 2
3 3
4 4
If you want to add a row with more columns, the code will looks like this:
df = pd.DataFrame(columns=['A','B','C'])
for i in range(5):
df = df.append({'A': i,
'B': i * 2,
'C': i * 3,
}
,ignore_index=True
)
df
A B C
0 0 0 0
1 1 2 3
2 2 4 6
3 3 6 9
4 4 8 12
What does the keyword "transient" mean in Java?
It means that trackDAO should not be serialized.
Rename MySQL database
I used following method to rename the database
take backup of the file using mysqldump or any DB tool eg heidiSQL,mysql administrator etc
Open back up (eg backupfile.sql) file in some text editor.
Search and replace the database name and save file.
Restore the edited SQL file
Check if a string contains a substring in SQL Server 2005, using a stored procedure
CHARINDEX() searches for a substring within a larger string, and returns the position of the match, or 0 if no match is found
if CHARINDEX('ME',@mainString) > 0
begin
--do something
end
Edit or from daniels answer, if you're wanting to find a word (and not subcomponents of words), your CHARINDEX call would look like:
CHARINDEX(' ME ',' ' + REPLACE(REPLACE(@mainString,',',' '),'.',' ') + ' ')
(Add more recursive REPLACE() calls for any other punctuation that may occur)
VBA check if file exists
I use this function to check for file existence:
Function IsFile(ByVal fName As String) As Boolean
'Returns TRUE if the provided name points to an existing file.
'Returns FALSE if not existing, or if it's a folder
On Error Resume Next
IsFile = ((GetAttr(fName) And vbDirectory) <> vbDirectory)
End Function
How do I display local image in markdown?
Edited:
Working for me ( for local image )

tree
+-- doc
+-- jobsSystemSchema.jpg
+-- README.md
markdown file README.md is at the same level as doc directory.
In your case ,your markdown file should be at the same level as the directory files.
Working for me (absolute url with raw path)

NOT working for me (url with blob path)

How to specify jdk path in eclipse.ini on windows 8 when path contains space
I have Windows 8.1 and my JDK under "Program Files" as well. What worked for me was replacing the name of the folder by the 8-digit internal MS-DOS name.
-vm
C:/PROGRA~1/Java/jdk1.8.0_40/bin/javaw.exe
I realized what was going on after running this in cmd.exe
CD \
DIR P* /X
It returned...
<DIR> PROGRA~1 Program Files
<DIR> PROGRA~2 Program Files (x86)
So we can find out how to use a path containing spaces
Can’t delete docker image with dependent child images
In some cases (like in my case) you may be trying to delete an image by specifying the image id that has multiple tags that you don't realize exist, some of which may be used by other images. In which case, you may not want to remove the image.
If you have a case of redundant tags as described here, instead of docker rmi <image_id> use docker rmi <repo:tag> on the redundant tag you wish to remove.
"unmappable character for encoding" warning in Java
This worked for me -
<?xml version="1.0" encoding="utf-8" ?>
<project name="test" default="compile">
<target name="compile">
<javac srcdir="src" destdir="classes"
encoding="iso-8859-1" debug="true" />
</target>
</project>